一、什么是BPR
BPR主要利用用户的隐式反馈(如点赞、浏览等),通过对问题的贝叶斯分析得到的最大后验概率来对用户的项目列表进行排序。
贝叶斯定理由英国数学家贝叶斯 ( Thomas Bayes 1702-1761 ) 发展,用来描述两个条件概率之间的关系。假设,现在有两个一定概率发生的事件A和B,且它们之间存在一定的关系。
- P(A)表示事件A发生的概率。
- P(B)表示事件A发生的概率。
- P(A | B)表示事件B已经发生的情况下,事件A发生的概率。
- P(B | A)表示事件A已经发生的情况下,事件B发生的概率。
理解了以上内容,就可以看一下数学上的贝叶斯定理:
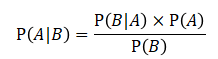
二、文中一些概念理解
1、显式反馈
在推荐系统中,显式反馈可以包括用户对物品的评分、评价、喜欢/不喜欢标记等直接的反馈形式。这些反馈信息提供了用户对物品的明确意见和偏好,可以用于建立用户与物品之间的关系模型,进而进行个性化推荐。
显式反馈的优点是用户提供了直接的反馈信息,可以提供相对准确和明确的用户偏好信号。然而,显式反馈也存在一些挑战和限制。首先,用户提供反馈的成本相对较高,因此用户可能只对少数物品进行评分或提供反馈,导致数据稀疏性问题。其次,用户的反馈可能具有主观性和不一致性,不同用户对相同物品的评分和偏好可能存在差异。最后,显式反馈只能反映用户意识到和愿意表达的偏好,无法涵盖用户的潜在偏好和兴趣。
1-1 显示反馈模型介绍

这个表格就是机器学习里面最常见的混淆矩阵,用来评判模型的好坏。
具体例子分析
假如某个班级有男生80人,女生20人,共计100人。目标是找出所有女生。
某人挑选出50个人,其中20人是女生,另外还错误的把30个男生也当作女生挑选出来了。
作为评估者的你需要来评估下他的工作,我们需要先需要定义TP,FN,FP,TN四种分类情况。
按照前面例子,我们需要从一个班级中的人中寻找所有女生,如果把这个任务当成一个分类器的话,那么女生就是我们需要的,,而男生不是,所以我们称女生为"正类",而男生为"负类"。

1-2显示反馈数据分析
我们可以通过计算模型分类的准确率,和召回率进来通过计算F-Measure的值来对模型分类的好坏进行评价。下面结合例子中这几个分类的值:TP=20,FP=30,FN=0,TN=50介绍准确率,召回率,和F-measure的概念与计算方法。

2、隐式反馈
在推荐系统中,隐式反馈可以包括用户的点击、浏览记录、购买历史、停留时间、收藏行为、社交网络关系等。这些行为和交互数据可能是隐含的、隐晦的,但它们可以暗示用户对物品的兴趣和偏好,并且隐式反馈是通过自然的行为和交互产生的数据来反映其偏好。这些数据通常可以更容易地获得,因为用户不需要额外的努力来提供反馈。
3、非个性化排名
非个性化排名是一种不考虑用户个体差异和偏好的排序方法,它为所有用户提供相同的物品排序结果;在非个性化排名中,物品的排序是基于一般性规则或全局标准进行的,而不考虑用户的个性化需求和偏好。这种排名方法通常适用于一些普遍适用的情境,例如热门排行榜、热门商品推荐等;通常使用一些全局的排序准则,例如物品的流行度、销量、评分平均值等指标。
4、个性化排名
个性化排名是一种根据用户的个体偏好和特征,为每个用户定制的物品排序方法,个性化排名的实现通常依赖于机器学习和数据挖掘技术,例如协同过滤、内容过滤、深度学习等。这些技术根据用户的历史行为、兴趣标签、社交网络关系等数据,建立用户模型和物品模型,从而预测用户对不同物品的偏好,并为用户生成个性化的排序结果。
5、似然函数
似然函数是统计学中的一个概念,用于描述参数在给定观测数据下的可能性。似然函数可以形式化地表示为:L(θ | D) = P(D | θ)
其中,L(θ | D) 表示在给定参数值 θ 的情况下,观测数据 D 发生的概率。它可以被看作是参数 θ 的函数,而观测数据 D 被视为已知的。似然函数描述了参数值生成观测数据的可能性,而不是给出参数的先验概率。似然函数的值越大,意味着给定参数值下观测数据发生的可能性越高。因此,我们可以使用似然函数来比较不同参数值对观测数据的拟合程度,从而找到最可能的参数估计值。
需要注意的是,概率P(D | θ)与似然函数L(θ | D)是相关的,但表示的角度不同。概率P(D | θ)是关于观测数据的函数,描述的是观测数据D在给定参数值θ下的出现概率;而似然函数L(θ | D)是关于参数值的函数,描述的是给定参数值θ下观测数据D出现的可能性。
6、最大后验估计(MAP)
最大后验估计(Maximum a Posteriori Estimation,MAP)是一种参数估计方法,用于在贝叶斯统计推断中确定参数的最优值。
7、正/负类对
BPR(Bayesian Personalized Ranking)方法中,正类对(Positive Pairs)指的是观测数据中的正例样本对,用于训练和优化个性化排名模型。
对于每个用户,根据其观测到的正例行为(例如点击、购买等),构建正类对。以用户-物品交互为例,如果用户在观测数据中与物品A有交互行为,而与物品B没有交互行为,则将(A, B)作为一个正类对。
8、ROC
ROC(Receiver Operating Characteristic)曲线是一种常用的评估二分类模型性能的工具。ROC曲线通过绘制真阳性率(True Positive Rate,TPR)与伪阳性率(False Positive Rate,FPR)之间的关系图来描述分类器在不同阈值下的性能。
真阳性率(TPR)是指在所有实际正例中,分类器正确地将其预测为正例的比例。即 TPR = TP / (TP + FN),其中 TP 表示真正例(True Positive),FN 表示假反例(False Negative)。
伪阳性率(FPR)是指在所有实际负例中,分类器错误地将其预测为正例的比例。即 FPR = FP / (FP + TN),其中 FP 表示假正例(False Positive),TN 表示真负例(True Negative)。
ROC曲线以 FPR 为横轴,TPR 为纵轴绘制,可以用于可视化分类器在不同阈值下的性能表现。理想情况下,分类器的ROC曲线会沿着左上角到右下角的方向弯曲,表示较高的TPR和较低的FPR,即分类器能够有效地区分正例和负例。
通过ROC曲线,可以计算出对应不同阈值下的AUC(Area Under the Curve),用于衡量分类器性能的好坏。AUC表示ROC曲线下的面积,取值范围在0到1之间,越接近于1表示分类器性能越好。
ROC曲线和AUC被广泛应用于评估二分类模型的性能,特别是在处理不平衡数据集、选择最佳分类阈值以及比较不同模型性能时。较高的AUC值和ROC曲线靠近左上角的情况通常意味着分类器具有更好的性能和更高的区分度。
9、AUC
AUC(Area Under the Curve)是一种常用的评估指标,用于衡量二分类模型的性能。AUC主要用于评估分类模型在ROC曲线下的表现。ROC曲线是以不同的分类阈值为基础绘制的,横轴表示伪阳性率(False Positive Rate,FPR),纵轴表示真阳性率(True Positive Rate,TPR)。
AUC是ROC曲线下的面积,取值范围在0和1之间。AUC的含义是,随机选择一个正例样本以及一个负例样本,分类器将正例排在负例前的概率。AUC越接近于1,表示模型性能越好,能够更好地区分正例和负例。如果AUC等于0.5,则表示模型的分类效果等同于随机猜测。
AUC的优点是对类别不平衡的数据集不敏感,且不受分类阈值的影响。因此,AUC被广泛用于评估各种分类任务,如广告点击率预测、医学诊断、信用风险评估等。
三、BPR相关算法定义
训练的数据集是多个三元组的<u,i,j>的条目,其含义表示的是用户u对i的选择优先级要高于j。在BPR算法中,我们将任意用户u对应的物品进行标记,如果用户u在同时有物品i和j的时候点击了i,那么我们就得到了一个三元组<u,i,j>,它表示对用户u来说,i的排序要比j靠前。
U代表所有用户user集合;I代表所有物品item集合;
S代表所有用户的隐式反馈, 。如下图所示,只要用户对某个物品产生过行为(如点击、收藏、加入购物车等),就标记为+,所有+样本构成了S。那些为观察到的数据(即用户没有产生行为的数据)标记为?。

这里我们假设:
1. 一是每个用户之间的偏好行为相互独立,即用户u在商品i和j之间的偏好和其他用户无关。
2. 二是同一用户对不同物品的偏序相互独立,也就是用户u在商品i和j之间的偏好和其他的商品无关。
其中用i ≻ u j 表示用户u在物品i和物品j之间更偏向与物品i
在BPR中,这个排序关系符号≻ u满足完全性,反对称性和传递性,即对于用户集U和物品集I:

完整性:对于项目 I 集中的任意两个项目 i 和 j,如果 i 不等于 j,则用户 u 优先于 i 而不是 j,或者用户 u 优先于 j
反对称性:项目 I 集中的任意两个项目 i 和 j,如果用户 u 优先于 i 而不是 j,用户 u 优先于 j,则 i 和 j 相等
传递性:对于项目 I 集中的任意三个项目 i、j 和 k,如果用户 u 首选 i 而不是 j,用户 u 首选 j 而不是 k,则用户 u 首选 i 而不是 k
四、BPR建模
在BPR算法中,我们将任意用户u对应的物品进行标记,如果用户u在同时有物品i和j的时候对i产生了行为,那么我们就得到了一个三元组<u,i,j>,但是如果一个用户对两个物品同时产生过行为,它表示对用户u来说,i的排序要比j靠前。或者同时没有产生行为,则无法构成偏好对。如果对于用户u来说我们有m组这样的反馈,那么我们就可以得到m组用户u对应的训练样本。可以看到BPR采用了pairwise的方式。
那么如下图所示,基于观察到的数据S构建数据集 Ds ,通过对每个用户,可以构建 I × I的偏好矩阵。所有用户的偏好对构成了训练集。
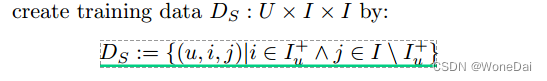
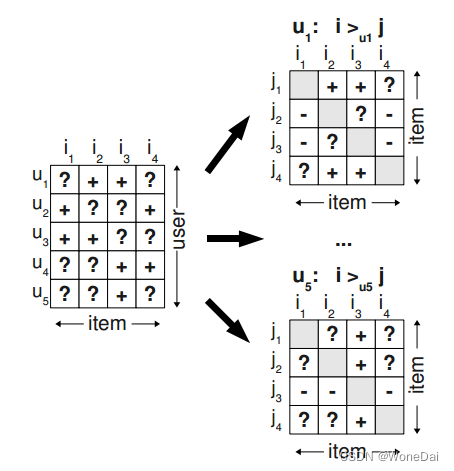
那么注意,对于每个三元组样本<u,i,j>,i必然时产生过行为的物品,而j必然时未被产生过行为的物品,因此 Ds只包括下图右边分解后+的数据,不包括-的数据。
BPR模型本质上是一种矩阵分解算法,所以其模型本质上是为了将用户物品矩阵分解成两个低维矩阵,再由两个低维矩阵相乘后得到完整的矩阵。 根据提供数据所形成的用户物品评分矩阵往往是稀疏的,即有很多未知项目,通过矩阵分解的方法分解出用户矩阵W和物品矩阵H。
根据这两个矩阵得到未知项目的评分:![]() ,因此我们需要学习的权重参数有W*K,H*k,这里的k和矩阵分解模型,也是自己定义的,一般远远小于|U|,|I|。
,因此我们需要学习的权重参数有W*K,H*k,这里的k和矩阵分解模型,也是自己定义的,一般远远小于|U|,|I|。
由于BPR是基于用户维度的,所以对于任意一个用户,对应的任意一个物品i我们期望有: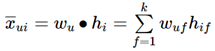
最终我们的目标,是希望寻找合适的矩阵W和H,让和
相似;这和矩阵分解模型可能没有什么区别,现在还看不出,下面我们来看看BPR的算法优化思路,慢慢理解和矩阵分解模型有什么不同。
五、BPR算法优化
BPR算法的基本思想是利用最大化后验概率来确定所有item,i∈I正确个性化排序,我们不妨假设正确的个性化排序可以由某个模型(如矩阵分解)给出,而θ表示这个模型的参数向量(W,H)。于是我们优化的目标就是使得![]() 最大,进而求出θ。根据贝叶斯公式得 :
最大,进而求出θ。根据贝叶斯公式得 :
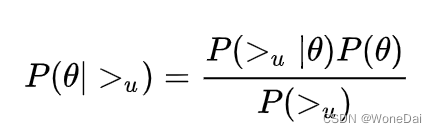
因为BPR假设用户的排序和其他用户无关,那么对于任意一个用户u来说,P(>u)对所有的物品都为一个常数,所以最大化P(|>u),等价于最大化P(>u|
)P(
),既
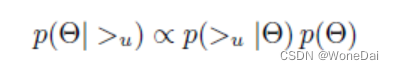
这个最大化目标可以分为两部分,左边的部分与数据集有关,右边部分P(θ)与数据集无关。
对于第一部分,由于我们假设每个用户之间的偏好行为相互独立,同一用户对不同物品的偏序相互独立,所以有:
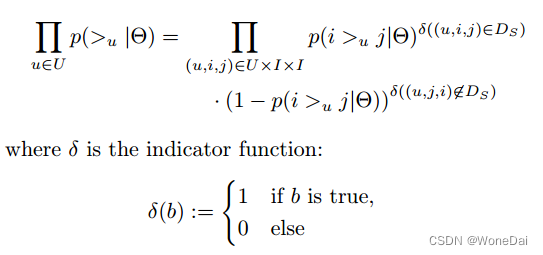
根据上面讲到的完整性和反对称性,优化目标的第一部分可以简化为:
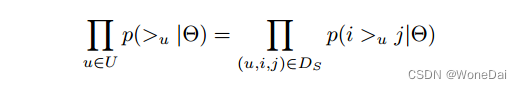
对于这部分,可以使用下面这个式子来代替:

X表达的是i与j的顺序关系,那么不难想像,如果用户比起 i 更喜欢 j 的话,那么矩阵中 i 的分数是不是要比 j 更高一点呢,我们希望更高一点,所以直接让![]() 不就好了。
不就好了。
补充解释:

根据独立同分布原则:
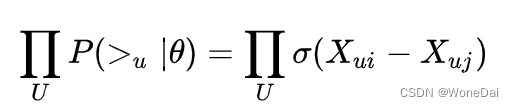
并且为了优化计算,将乘法转成加法,在前面加个log函数。
对于第二部分P(θ),原作者大胆使用了贝叶斯假设,即这个概率分布符合正太分布,且对应的均值是0,协方差矩阵是I,既:


最后变成求解下面式子最大值:
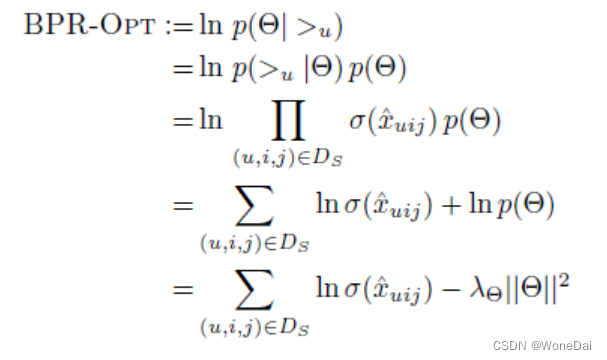
这个式子可以用梯度上升法或者牛顿法等方法来优化求解模型参数。如果用梯度上升法,对θ求导,我们有:

或
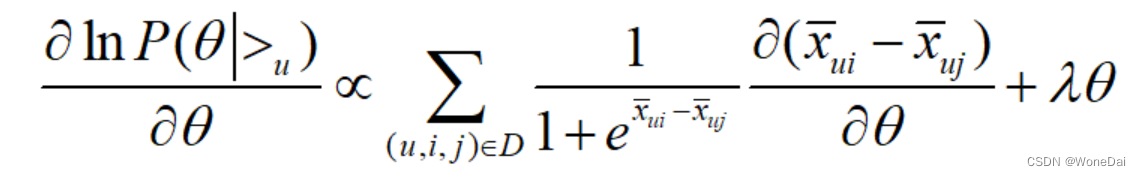
由于有:
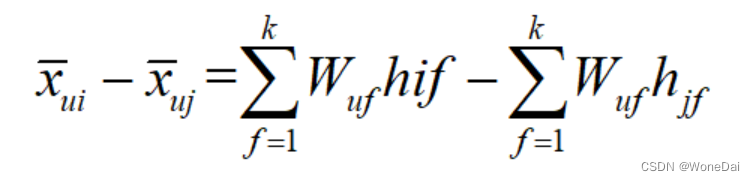
故可以求出:
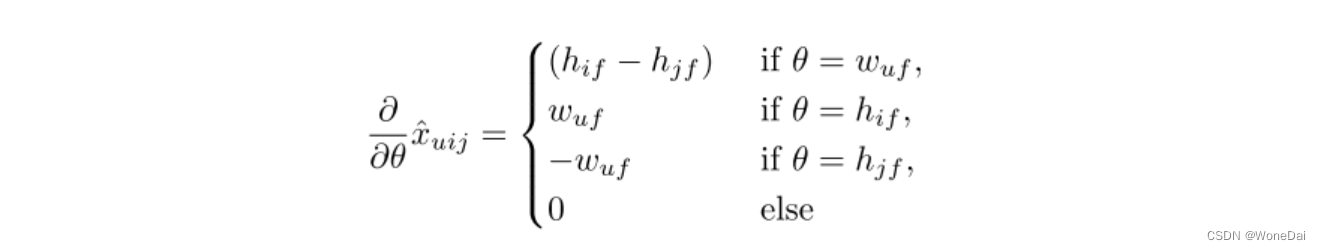
六、算法使用流程
输入:训练集D三元组,梯度步长α,正则化参数,分解矩阵维度K。
输出:模型参数,矩阵W,H
1. 随机初始化矩阵W,H
2. 迭代更新模型参数:
3·直到W、H收敛,否则重复步骤2
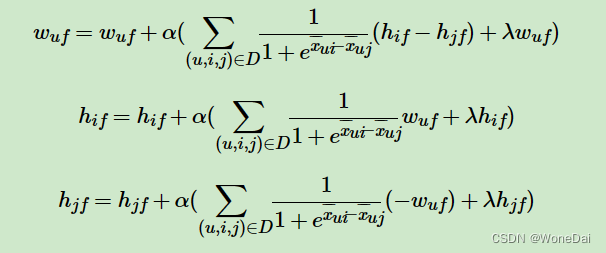
当计算出W,H后,就可以计算出每一个用户u对应的任意一个商品的排序分:x=w·h,最终选择排序分最高的若干商品输出。
七、代码实现
1:BPR的主函数
# !/usr/bin/env python
# @Time:2021/4/6 19:21
# @Author:华阳
# @File:Basical BPR.py
# @Software:PyCharm
import random
from collections import defaultdict
import numpy as np
from sklearn.metrics import roc_auc_score
import scores
'''
函数说明:BPR类(包含所需的各种参数)
Parameters:
无
Returns:
无
'''
class BPR:
#用户数
user_count = 943
#项目数
item_count = 1682
#k个主题,k数
latent_factors = 20
#步长α
lr = 0.01
#参数λ
reg = 0.01
#训练次数
train_count = 10000
#训练集
train_data_path = 'train.txt'
#测试集
test_data_path = 'test.txt'
#U-I的大小
size_u_i = user_count * item_count
# 随机设定的U,V矩阵(即公式中的Wuk和Hik)矩阵
U = np.random.rand(user_count, latent_factors) * 0.01 #大小无所谓
V = np.random.rand(item_count, latent_factors) * 0.01
biasV = np.random.rand(item_count) * 0.01
#生成一个用户数*项目数大小的全0矩阵
test_data = np.zeros((user_count, item_count))
print("test_data_type",type(test_data))
#生成一个一维的全0矩阵
test = np.zeros(size_u_i)
#再生成一个一维的全0矩阵
predict_ = np.zeros(size_u_i)
#获取U-I数据对应
'''
函数说明:通过文件路径,获取U-I数据
Paramaters:
输入要读入的文件路径path
Returns:
输出一个字典user_ratings,包含用户-项目的键值对
'''
def load_data(self, path):
user_ratings = defaultdict(set)
with open(path, 'r') as f:
for line in f.readlines():
u, i = line.split(" ")
u = int(u)
i = int(i)
user_ratings[u].add(i)
return user_ratings
'''
函数说明:通过文件路径,获取测试集数据
Paramaters:
测试集文件路径path
Returns:
输出一个numpy.ndarray文件(n维数组)test_data,其中把含有反馈信息的数据置为1
'''
#获取测试集的评分矩阵
def load_test_data(self, path):
file = open(path, 'r')
for line in file:
line = line.split(' ')
user = int(line[0])
item = int(line[1])
self.test_data[user - 1][item - 1] = 1
'''
函数说明:对训练集数据字典处理,通过随机选取,(用户,交互,为交互)三元组,更新分解后的两个矩阵
Parameters:
输入要处理的训练集用户项目字典
Returns:
对分解后的两个矩阵以及偏置矩阵分别更新
'''
def train(self, user_ratings_train):
for user in range(self.user_count):
# 随机获取一个用户
u = random.randint(1, self.user_count) #找到一个user
# 训练集和测试集的用于不是全都一样的,比如train有948,而test最大为943
if u not in user_ratings_train.keys():
continue
# 从用户的U-I中随机选取1个Item
i = random.sample(user_ratings_train[u], 1)[0] #找到一个item,被评分
# 随机选取一个用户u没有评分的项目
j = random.randint(1, self.item_count)
while j in user_ratings_train[u]:
j = random.randint(1, self.item_count) #找到一个item,没有被评分
#构成一个三元组(uesr,item_have_score,item_no_score)
# python中的取值从0开始
u = u - 1
i = i - 1
j = j - 1
#BPR
r_ui = np.dot(self.U[u], self.V[i].T) + self.biasV[i]
r_uj = np.dot(self.U[u], self.V[j].T) + self.biasV[j]
r_uij = r_ui - r_uj
loss_func = -1.0 / (1 + np.exp(r_uij))
# 更新2个矩阵
self.U[u] += -self.lr * (loss_func * (self.V[i] - self.V[j]) + self.reg * self.U[u])
self.V[i] += -self.lr * (loss_func * self.U[u] + self.reg * self.V[i])
self.V[j] += -self.lr * (loss_func * (-self.U[u]) + self.reg * self.V[j])
# 更新偏置项
self.biasV[i] += -self.lr * (loss_func + self.reg * self.biasV[i])
self.biasV[j] += -self.lr * (-loss_func + self.reg * self.biasV[j])
'''
函数说明:通过输入分解后的用户项目矩阵得到预测矩阵predict
Parameters:
输入分别后的用户项目矩阵
Returns:
输出相乘后的预测矩阵,即我们所要的评分矩阵
'''
def predict(self, user, item):
predict = np.mat(user) * np.mat(item.T)
return predict
#主函数
def main(self):
#获取U-I的{1:{2,5,1,2}....}数据
user_ratings_train = self.load_data(self.train_data_path)
#获取测试集的评分矩阵
self.load_test_data(self.test_data_path)
#将test_data矩阵拍平
for u in range(self.user_count):
for item in range(self.item_count):
if int(self.test_data[u][item]) == 1:
self.test[u * self.item_count + item] = 1
else:
self.test[u * self.item_count + item] = 0
#训练
for i in range(self.train_count):
self.train(user_ratings_train) #训练10000次完成
predict_matrix = self.predict(self.U, self.V) #将训练完成的矩阵內积
# 预测
self.predict_ = predict_matrix.getA().reshape(-1) #.getA()将自身矩阵变量转化为ndarray类型的变量
print("predict_new",self.predict_)
self.predict_ = pre_handel(user_ratings_train, self.predict_, self.item_count)
auc_score = roc_auc_score(self.test, self.predict_)
print('AUC:', auc_score)
# Top-K evaluation
scores.topK_scores(self.test, self.predict_, 5, self.user_count, self.item_count)
'''
函数说明:对结果进行修正,即用户已经产生交互的用户项目进行剔除,只保留没有产生用户项目的交互的数据
Paramaters:
输入用户项目字典集,以及一维的预测矩阵,项目个数
Returns:
输出修正后的预测评分一维的预测矩阵
'''
def pre_handel(set, predict, item_count):
# Ensure the recommendation cannot be positive items in the training set.
for u in set.keys():
for j in set[u]:
predict[(u - 1) * item_count + j - 1] = 0
return predict
if __name__ == '__main__':
#调用类的主函数
bpr = BPR()
bpr.main()
2:计算模型指标
# -*- coding: utf-8 -*-
"""scores.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/17qoo1U4Iw58GRDDIyCaB2GmbRUg1gTPd
"""
import heapq
import numpy as np
import math
#计算项目top_K分数
def topK_scores(test, predict, topk, user_count, item_count):
PrecisionSum = np.zeros(topk+1)
RecallSum = np.zeros(topk+1)
F1Sum = np.zeros(topk+1)
NDCGSum = np.zeros(topk+1)
OneCallSum = np.zeros(topk+1)
DCGbest = np.zeros(topk+1)
MRRSum = 0
MAPSum = 0
total_test_data_count = 0
for k in range(1, topk+1):
DCGbest[k] = DCGbest[k - 1]
DCGbest[k] += 1.0 / math.log(k + 1)
for i in range(user_count):
user_test = []
user_predict = []
test_data_size = 0
for j in range(item_count):
if test[i * item_count + j] == 1.0:
test_data_size += 1
user_test.append(test[i * item_count + j])
user_predict.append(predict[i * item_count + j])
if test_data_size == 0:
continue
else:
total_test_data_count += 1
predict_max_num_index_list = map(user_predict.index, heapq.nlargest(topk, user_predict))
predict_max_num_index_list = list(predict_max_num_index_list)
hit_sum = 0
DCG = np.zeros(topk + 1)
DCGbest2 = np.zeros(topk + 1)
for k in range(1, topk + 1):
DCG[k] = DCG[k - 1]
item_id = predict_max_num_index_list[k - 1]
if user_test[item_id] == 1:
hit_sum += 1
DCG[k] += 1 / math.log(k + 1)
# precision, recall, F1, 1-call
prec = float(hit_sum / k)
rec = float(hit_sum / test_data_size)
f1 = 0.0
if prec + rec > 0:
f1 = 2 * prec * rec / (prec + rec)
PrecisionSum[k] += float(prec)
RecallSum[k] += float(rec)
F1Sum[k] += float(f1)
if test_data_size >= k:
DCGbest2[k] = DCGbest[k]
else:
DCGbest2[k] = DCGbest2[k-1]
NDCGSum[k] += DCG[k] / DCGbest2[k]
if hit_sum > 0:
OneCallSum[k] += 1
else:
OneCallSum[k] += 0
# MRR
p = 1
for mrr_iter in predict_max_num_index_list:
if user_test[mrr_iter] == 1:
break
p += 1
MRRSum += 1 / float(p)
# MAP
p = 1
AP = 0.0
hit_before = 0
for mrr_iter in predict_max_num_index_list:
if user_test[mrr_iter] == 1:
AP += 1 / float(p) * (hit_before + 1)
hit_before += 1
p += 1
MAPSum += AP / test_data_size
print('MAP:', MAPSum / total_test_data_count)
print('MRR:', MRRSum / total_test_data_count)
print('Prec@5:', PrecisionSum[4] / total_test_data_count)
print('Rec@5:', RecallSum[4] / total_test_data_count)
print('F1@5:', F1Sum[4] / total_test_data_count)
print('NDCG@5:', NDCGSum[4] / total_test_data_count)
print('1-call@5:', OneCallSum[4] / total_test_data_count)
return
参考文献:
BPR-贝叶斯个性化排序 - 简书 (jianshu.com)
推荐系统论文阅读(七) | Learner (yifdu.github.io)
(3条消息) BPR贝叶斯个性化推荐算法—推荐系统基础算法(含python代码实现以及详细例子讲解)_bpr代码_啥都不懂的小程序猿的博客-CSDN博客