(马尔可夫与马尔科夫都可以,所以也别纠结)
马尔可夫模型(Markov Model)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的统计工具。 -----------百度
对于马尔科夫实际上是根据根据历史数据和其中的规律,总结出变化的规律,使用概率转移图的形式来推断或者拟合某些事实。其实际使用的主要是状态和概率。那么我们首先需要明确的是什么样的问题可以使用马尔科夫模型?而什么样的问题需要使用隐马尔可夫模型,在简单的叙述过后如果大家可以带着问题和答案来学习,那么就会真正理解这个的意义。
马尔科夫模型适用的问题
1)我们的问题是基于序列的,比如时间序列,或者状态序列。
2)序列之间有固定的转移模式,而不是随机变化的,即概率是不变的
隐马尔科夫模型适用的问题
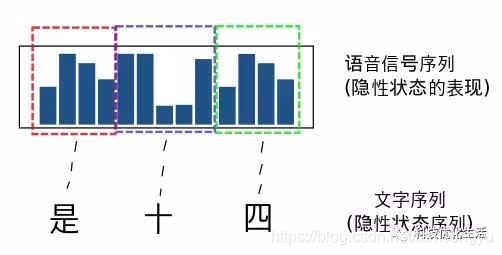
1)我们的问题中有两类数据,一类序列数据是可以观测到的,即观测序列;而另一类数据是不能观察到的,即隐藏状态序列,简称状态序列。
2)观测序列和状态序列存在对应关系,不必须是一一对应,但是必须有对应的关系。
接下来详细介绍一下,帮助大家对其的初步理解,存在诸多的问题还请批评指正。
马尔可夫模型:
马尔可夫模型MM(MarkovModel)是一种统计模型。它的原始模型马尔可夫链,马尔可夫链是与马尔可夫过程紧密相关。马尔可夫过程是研究离散事件动态系统状态空间的重要方法,它的数学基础是随机过程理论。广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的统计工具。
马尔可夫链:
马尔可夫链(Markov Chain)是指数学中具有马尔可夫性质的离散事件随机过程。该过程中,在给定当前知识或信息的情况下,过去对于预测将来是无关的。在马尔可夫链的每一步,系统根据概率分布,可以从一个状态变到另一个状态,也可以保持当前状态。状态的改变叫做转移,与不同的状态改变相关的概率叫做转移概率。其中所有的状态的总和可以称为“状态空间”,
时间和状态都离散的马尔可夫过程成为马尔可夫链。
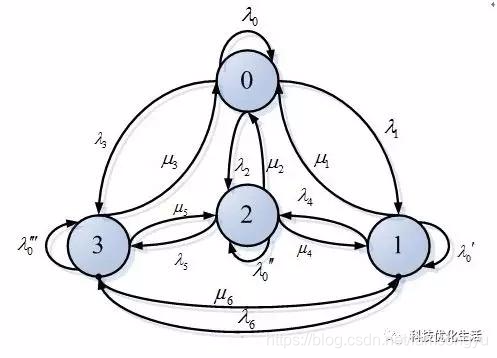
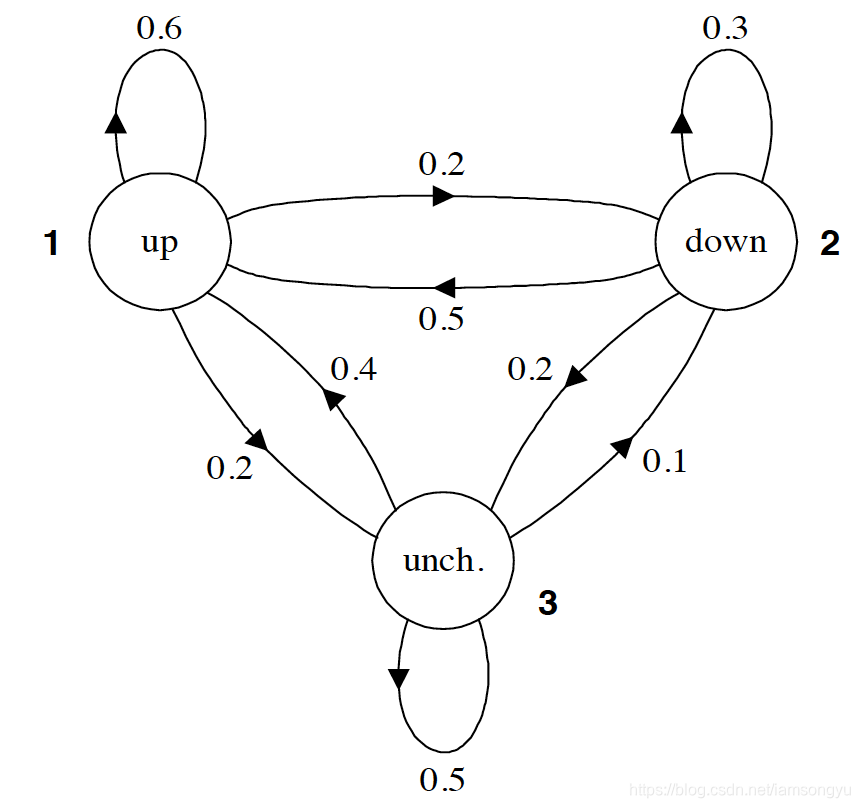
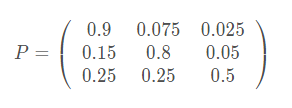
其中的圆圈表示不同的状态,箭头的出发点表示的状态转移的源,箭头指向的圈表示状态转移的目的,各个箭头上的数字代表的就是状态之间相互转化的概率。一个含有M个状态的一阶过程有M的平方个状态转移。每一个转移的概率叫做状态转移概率(state transition probability),就是从一个状态转移到另一个状态的概率。这所有的M的平方个概率可以用一个状态转移矩阵来表示。这个就类似于混淆矩阵的形式,简单的例子如下,与本图无关
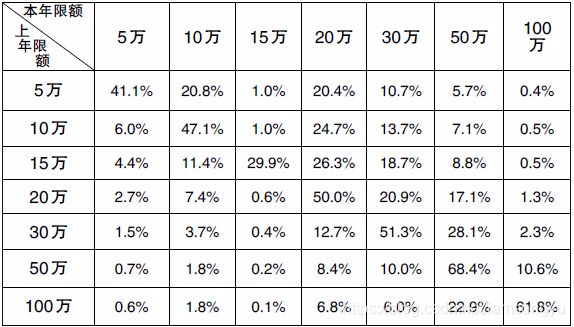
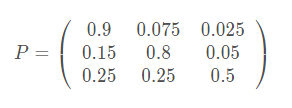
在上述的矩阵中将初始状态作为行标i,目的状态作为列j,则P(i,j)则表示的是由i所表示的状态转移到有j所表示的状态的概率。那我们可知矩阵中的数字为概率,每行表示一个状态的所有转移情况。(强调,只有当测量概率是离散的情况下,我们才能用一个矩阵来表示 。对于连续的情况,我们会在下面继续说)
也许我们需要再次重申一下这个原理,马尔可夫链状是态空间中经过从一个状态到另一个状态的转换的随机过程。根据当前状态我们有不同的概率可以转移到下一个状态,在时间序列中它前面的事件均与之无关,这种特定类型的“无记忆性”称作马尔可夫性质。这个模型看起来类似于自动机模型,但是却有着本质的区别。我在这里简单说两点,由于知识有限,可能理解的有偏差:
- 自动机模型的状态之间的转移依靠事件的驱动,而马尔科夫链则是概率决定
- 自动机模型一个状态可以向另外有限个状态转移,甚至是不转移,但马尔科夫链则是所有状态均有连接,甚至还有转移矩阵用来描述这个关系
- 自动机模型用来拟合和判断序列是否符合模型,而马尔科夫链根据这个原理,大多数则是用来估计和识别的。
马尔可夫链性质:
其每个状态值取决于前面有限个状态。运用马尔可夫链只需要最近或现在的知识便可预测将来。
根据概率的基本理论,我们可以得知,马尔科夫链必定存在以下特征:
1)正定性:状态转移矩阵中的每一个元素被称为状态转移概率,所以每个状态的每个转移概率一定为正数
![]()
2)有限性:由于马尔科夫链中包含一个状态到其余状态的所有可能,由概率论知识知,一个事件的概率总和必为1,即一个状态向外转移的所有链路的和值为1
![]()
这体现在转移矩阵中,就是每一行的概率相加的总和为1
马尔可夫模型分类:
1)显马尔可夫模型(VMM),又叫马尔可夫模型MM,也就是我们上述所描述的种类的模型,具体状态已知。
2)隐马尔可夫模型(HMM),描述一个含有隐含未知参数的马尔可夫过程,是一个双重随机过程(包括马尔可夫链和一般随机过程)。
隐马尔可夫模型是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。所以,隐马尔可夫模型是一个双重随机过程----具有一定状态数的隐马尔可夫链和显示随机函数集。
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。而这个未知的参数指的是什么?为了弄清这个东西,看了几篇博客,看了不少例子,争取用最简洁易懂的语言来描述。
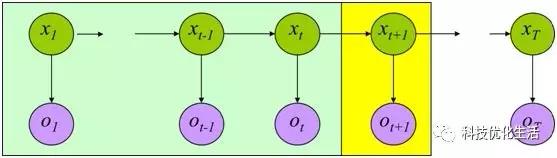
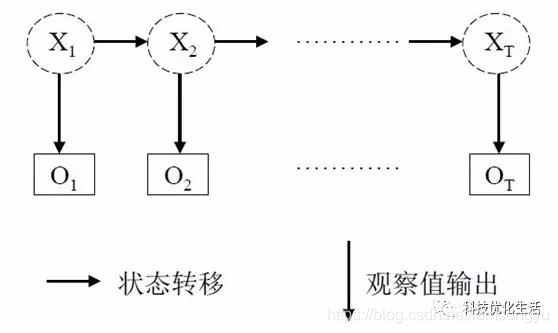
隐含位置参数实际上指的是我们得到的状态不是原始的状态,而是跟其有关的显现出来的状态,就比如下面的图,实际上的状态是X1-XT 而我们观察到的状态是O1-OT,虽然我们不能得知原始的状态是什么,但是两个是有关系的,我们可以根据输出的状态转移推测原始状态。
一篇文章作者的例子非常好,我们存在的隐状态为天气{下雨,天晴},一个人根据天气选择当天的活动,现在我们得知他在微博上发的动态为
“我前天公园散步、昨天购物、今天清理房间了!”,需要由此推断天气是什么样的,显状态是活动,隐状态是天气。
任何一个HMM都可以通过下列五元组来描述:
1. 隐含状态 S
2. 可观测状态 O
3. 初始状态概率矩阵 π
4. 隐含状态转移概率矩阵 A。
5. 观测状态转移概率矩阵 B 发射概率 (隐状态表现为显状态的概率)。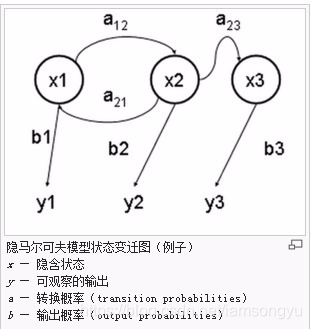
其实要我们猜,那就很可能第一天晴天,第二天晴天,第三天下雨,当然这只是一个猜测,而我们猜测的基础是什么?没错就是我们的先验知识,很少有人会下雨天出去散步对吧,如果下雨了大多数人都会留在家里收拾房间对不对~,实际上隐马尔科夫解决问题时也是基于类似的先验知识,也就是概率。
首先我们需要从已知的状态中了解隐状态和表现出的状态的对应关系,当然不必须是确定的,可以是一个概率关系,其次我们需要知道隐状态之间的转移关系。这么说吧,我们了解上图中所有的y值信息和b值信息及其对应的位置,我们知道所以的x值和a值但是不知道是如何与y对应的,即不知道他们的位置,x1可能表示的是晴天,也可能是雨天,也可能是雪天,其他的两个隐状态也是如此。
对此我们假设已知先验信息
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6},
}
emission_probability = {
'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},
}我们经过简单的计算演示原理,(第一天的天气需要初始状态,也就是多种可能),第一天和朋友散步,概率是两种情况的概率分别是
(下雨的概率)*(下雨天散步的发射概率)=0.6*0.1 = 0.06
(晴天的概率)*(晴天散步的发射概率)=0.4*0.6= 0.24
从直觉上来看,因为第一天朋友出门了,她一般喜欢在天晴的时候散步,所以第一天天晴的概率比较大,数字与直觉统一了。
而后续的计算需要在前一天的基础上计算天气的转移概率 然后在重复上述的计算
(第一天晴天概率)*(转移为晴天)*(晴天出去购物的概率)‘
(第一天晴天概率)*(转移为雨天)*(雨天出去购物的概率)
(第一天雨天概率)*(转移为雨天)*(雨天出去购物的概率)
(第一天雨天概率)*(转移为晴天)*(晴天出去购物的概率)
就是这样通过概率的比较,选择可能性最大的最为最终的结果,确定隐状态的对应关系。
马尔可夫模型应用:
马尔可夫模型广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理、算术编码、地理统计学、企业产品市场预测、人口过程、生物信息学(编码区域或基因预测)等应用领域。经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的统计工具。
1)状态统计建模:马尔可夫链通常用来建模排队理论和统计学中的建模。还可作为信号模型用于熵编码技术等。马尔科夫链预测法是一种适用于随机过程的科学、有效的动态预测方法。马尔可夫链有众多的生物学应用,特别是人口过程,可以帮助模拟生物人口过程的建模。
2)隐蔽马尔可夫模型(HMM)还被用于生物信息学,用以编码区域或基因预测。1980年代后半期,HMM开始应用到生物序列尤其是DNA的分析中。此后,在生物信息学领域HMM逐渐成为一项不可或缺的技术。到目前为止,隐马尔可夫模型(HMM)一直被认为是实现快速精确的语音识别系统的最成功的方法。复杂的语音识别问题通过隐含马尔可夫模型能非常简单地被表述、解决,让人们由衷地感叹数学模型之妙。
参考文章:
https://blog.csdn.net/bi_mang/article/details/52289087
http://mp.ofweek.com/ai/a945673920186
https://blog.csdn.net/bitcarmanlee/article/details/82819860
https://blog.csdn.net/class_brick/article/details/78849441
https://www.cnblogs.com/skyme/p/4651331.html
https://www.cnblogs.com/pinard/p/6945257.html
https://www.xuebuyuan.com/3233640.html