本文记录了博主在阅读《Panoptic Segmentation》一文过程中记录的笔记。更新于2018.12.27。
文章目录
Useful links
COCO challenge 2018: panoptic segmentation
panoptic segmentation data set
Panoptic Segmentation API
中文介绍
Cityscapes
ADE20k
Mapillary Vistas
Introduction
全景分割(PS,Panoptic Segmentation)的task format: 每个像素点都必须被分配给一个语义标签(stuff、things中的各个语义)和一个实例id。具有相同标签和id的像素点属于同一目标;对于stuff标签,不需要实例id。
论文作者认为目前分割任务在things或stuff之间分别进行而非统一分割的一个很重要的原因是缺少合适的度量矩阵。因此,文中提出了一种适用于二者的panoptic quality(PQ) metric。
与语义分割相比,全景分割的困难在于为了区分不同类别的实例,全连接网络的设计要更困难一些;
与实例分割相比,目标的分割必须是非重叠的(non-overlapping),因此对那些每个目标单独标注一个区域是不同的。
Related Work
作者在这一部分写的还是很有启发性的,建议看一下。博主后面会更新这一部分。
Panoptic Segmentation Format
Task format: 全景分割的任务要求一个算法能够将图片内的每一个像素点 投射成 ,其中 是其语义分割的类别, 是其实例分割的id。具有相同 标注的像素点会被聚集成不同的部分。模棱两可或无法确定类别的点可以被赋予一个空标注,也就是说不是所有的点都必须有一个语义标注。
Stuff and thing labels: 这里,所有语义类别都要么属于stuff,要么属于thing,不会有一个类别既属于Stuff又属于thing。且,如果一个像素被标注为stuff,那么其实例类别就无所谓了,即默认所有具有相同stuff类别的物体都被认为是同一样东西(如都是蓝天);否则,只有具有相同实例类别的点才会被标注成同类目标(如同一辆车)。
与语义分割的关系: 如果所有的类别都是stuff,那么PS确实与语义分割相同(但task metrics不同)。且引入了thing类别后,图片中可能出现多个实例,这也对分割造成了影响。
与实例分割的关系: PS中不允许重叠,但是实例分割中可以有重叠区域。
Confidence scores: 与语义分割相同但不同于实例分割,PS不需要每个segment的置信概率。尽管不提供置信概率更贴近人类认知世界的方法;但是对于底层机器而言,置信概率还是有用的,因此论文作者提出也需要能够提供置信概率的PS算法。
Panoptic Segmentation Metric
论文作者认为,将stuff分割和thing分割统一起来的度量应当具有:
- 完整性:这个度量需要统一对待stuff和thing,将任务中所有方面都考虑到。
- 可解释性: 我们追求可定义的度量,因为其可以促进交流和理解。
- 简单:该度量应当定义简介,使用简单,能够被简单地复现。
考虑到上面几点,论文作者们提出了下面这个度量,其分为两步:segment matching和给定matches下的PQ computation。
Segment Matching
两个条件:
- IoU(intersection over union)要严格大于0.5才算匹配(predicted segment与ground truth segment);
- 不可以有重叠区域(non-overlapping property)。
上述这两个条件就限制了,每一个点最多只能有一个与之对应的ground truth segment(unique matching)。
这段话比较难理解,这里放上原文以辅助:
… gives a unique matching: there can be at most one predicted segment matched with each ground truth segment.
针对上面这个陈述,原文中给出了Theorem 1并附有证明,感兴趣可以看原文第四页。
在这个基础上,原文中归纳出了由定理1给出的两个性质:
- First, it is simple and efficient as correspondences are unique and trivial to obtain.
- Second, it is interpretable and easy to understand (and does not require solving a complex matching problem as is commonly the case for these types of metrics).
这些性质还是比较难理解的,博主个人认为,这两个性质的主要带来的好处也就是,一个位置就只能给一个标签了,不会像实例分割中那样,一个点还可能给多个分割标签(因为实例分割允许重叠),那么这一个点就是独特的了,对于该点所携带信息的理解也就是唯一的了。这种唯一性就使得:首先,分割任务更简单(因为不存在“一词多义”);其次,可解释(一个点就一个分割也就是一个含义)。这段理解如果各位在阅读原文后有不同的理解,欢迎在评论区讨论,这里博主仅将个人理解放在这里抛砖引玉。
另外,论文作者在文中还给出了一个博主认为很重要的结论:不需要考虑小于0.5的IoU,因为实际应用中,以IoU$\leq$0.5匹配的情况非常稀少。
PQ Computation
PQ:Panoptic Quality
论文作者首先单独计算每个类别对应的PQ,随后对所有类别取平均。这样就使得PQ对于类别不均衡(class imbalabce)不敏感。
对于每个类别,unique matching将predicted segments和ground truth segments分为三类:true positives (TP), false positives (FP), 和false negatives (FN),分别对应配对的分割(matched pairs of segments),不配对的估计分割(unmatched predicted segments),不配对的真值分割(unmatched ground truth segments)。
下图是一个例子:
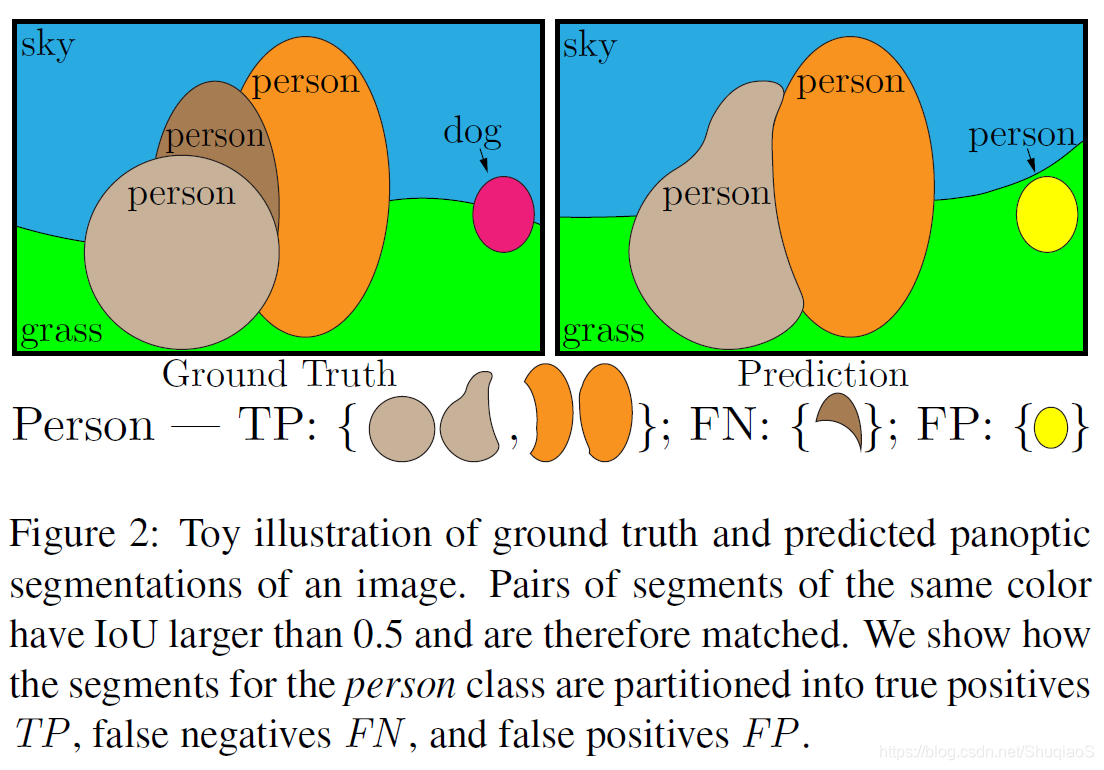
给定上述三个类别,PQ由下式定义:
其中, 很好理解,就是对于所有匹配上的分割求平均IoU,分母中增加的 是为了惩罚没有匹配正确的点(因为分母增加后,PQ的值降低,即分割质量下降)。需要注意的是,无论segments的位置,它们都具有相同的权重。
另外,PQ通过变换也可以理解为分割质量(SQ,segmentation quality)与识别质量(PQ,recognition quality)的乘积:
其中RQ就是检测中常用的质量估计 score。
空标注(Void labels)
在真值中有两种空标注类型:超出类别像素(out of class pixels)和模糊或未知像素(ambiguous or unkown pixels)。在评估过程中,对应真值空标注的这些点不参与评估。具体移除方式文中有说明,见原文第5页void labels。
组标注(Group labels)
在某些情况下,区分具有相同语义分割的不同相邻实例有一定困难,此时一种常用的做法是用group labels替代instance ids。在PQ中,首先,不使用group labels;其次,对于包含一部分相同类别像素点的unmatched predicted segments,这一部分将被去除并不视作false positives。
与现有度量的比较
语义分割度量
用于语义分割的现有度量主要包括像素准确度(pixel accuracy)、平均准确度(mean accuracy)和IoU。然而这些分割方法都只关注了像素级的正确率,而没有考虑实例正确性,因此不适合用于thing类别的分割任务。
实例分割度量
标准的实例分割度量是平均精度(Average Precision,AP)。AP要求所有的目标分割都有一个置信概率用于估计precision/recall曲线。然而,这种方法无法度量语义分割或全景分割的输出。
全景质量(Panoptic quality)
PQ不是单纯的语义分割度量与实例分割度量的组合,SQ和RQ对于每一个类别(stuff和thing)都被计算了,分别用于评估分割和识别的精度。
全景分割数据库
就论文作者已知的,目前只有三个数据库同时包括稠密语义分割与实例分割标注:Cityscapes、ADE20k和Mapillary Vistas。在全景分割中,这三种数据库都被使用了,论文作者也将进一步扩展COCO数据集(其中stuff类别已经有了标注)。
关于数据库的情况,博主直接截图放在下面了:

人类行为研究
论文中从人类标注(human annotations)、人类表现(human performance)、stuff vs. things、小物体vs.大物体、IoU阈值和SQvs.RQ平衡几个方面做了描述。博主认为这一部分的内容还是具有很大的启发性的,然而博主目前的理解仅限于机械的翻译,而没有办法对这一部分给出自己的理解,因此建议感兴趣的话自行阅读原文对应部分。当然博主后面如果有了不同的理解,会回来更新。