本文记录了博主阅读论文《An End-to-End Network for Panoptic Segmentation》的笔记,论文代码如果公布则回来更新。更新于2019.04.09。
文章目录
Abstract
文中提出了一个用于应对遮挡的端到端全景分割网络OANet,还给出了一个用于应对实例间遮挡问题的spatial ranking module。
Introduction
通常网络结构对于全景分割中的thing和stuff是通过两个分支完成,再融合在一起的。这篇论文提出了一个端到端结构,两种方式见下图:
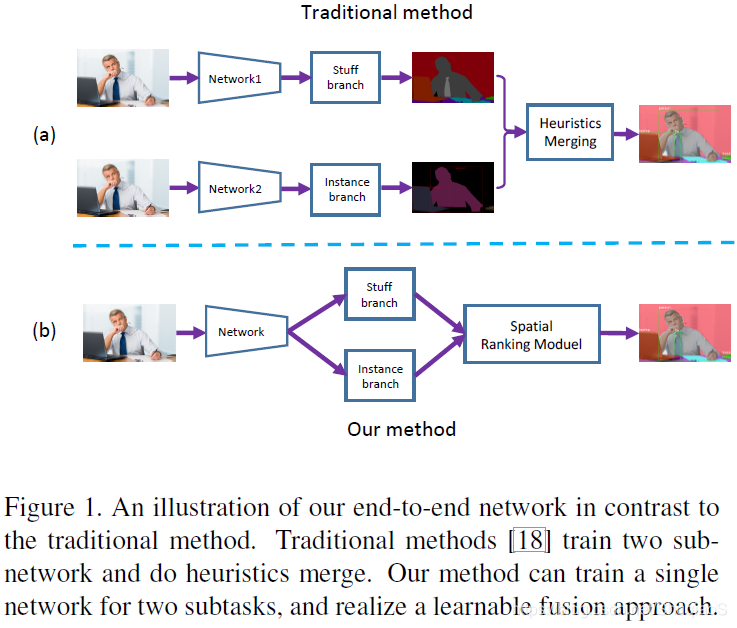
文中声称这是第一个端到端结构,但是就博主所知,至少博主这篇文章(【阅读笔记】《Panoptic Segmentation with a Joint Semantic and Instance Segmentation Network》)中提到的网络结构与之非常类似。
文中还提出了一个Spatial Ranking Module。该模块学习ranking score并提供实例的顺序。
总体而言,创新点如下:
- 端到端,遮挡敏感,全景分割
- 空间排序模块
- COCO全景分割第一
Related Work
实例分割
实例分割有两个主流架构,分别是proposal-based methods和segmentation-based methods。
前者([8],[14] Mask R-CNN,[24],[25],[28],[29],[33])首先生成目标检测的bounding boxes,再对每个box应用mask prediction实现实例分割。这一类方法与目标检测算法(比如Fast/Faster R-CNN和SPPNet,[12],[15],[36])关系密切。在这个架构下,遮挡问题是由独立估计各个实例造成的。也就是,在多个mask下,像素点可能被分配给错误的类别。
后者利用语义分割网络估计像素类别,再通过解码目标边界([19])或自定义范围(costum field,[2],[9],[27])获得每个实例的mask。最后,用一个自下而上的聚类机制生成目标实例。每次用RNN方法生成一个实例的mask([35],[37],[46])。
语义分割
FCN
编解码结构
全局卷积网络:缓解了分类和定位之间的矛盾。
全景分割
多任务学习
全景分割也可以被视作多任务学习问题。UberNet在一个网络中同时处理low-, mid-和high-level vision tasks,包括边缘检测、语义分割和法线估计。Zamir等人构建了一个directed graph named taskonomy(分类法),可以有效度量和利用不同视觉任务之间的相关性。这种方能能够避免重复学习,并且能够在数据量较小的条件下学习。
Proposed End-to-end Framework
下图是论文中提出算法的overview。总共包括三个主要部分:1)stuff分支,2)instance分支,3)空间排序模块。
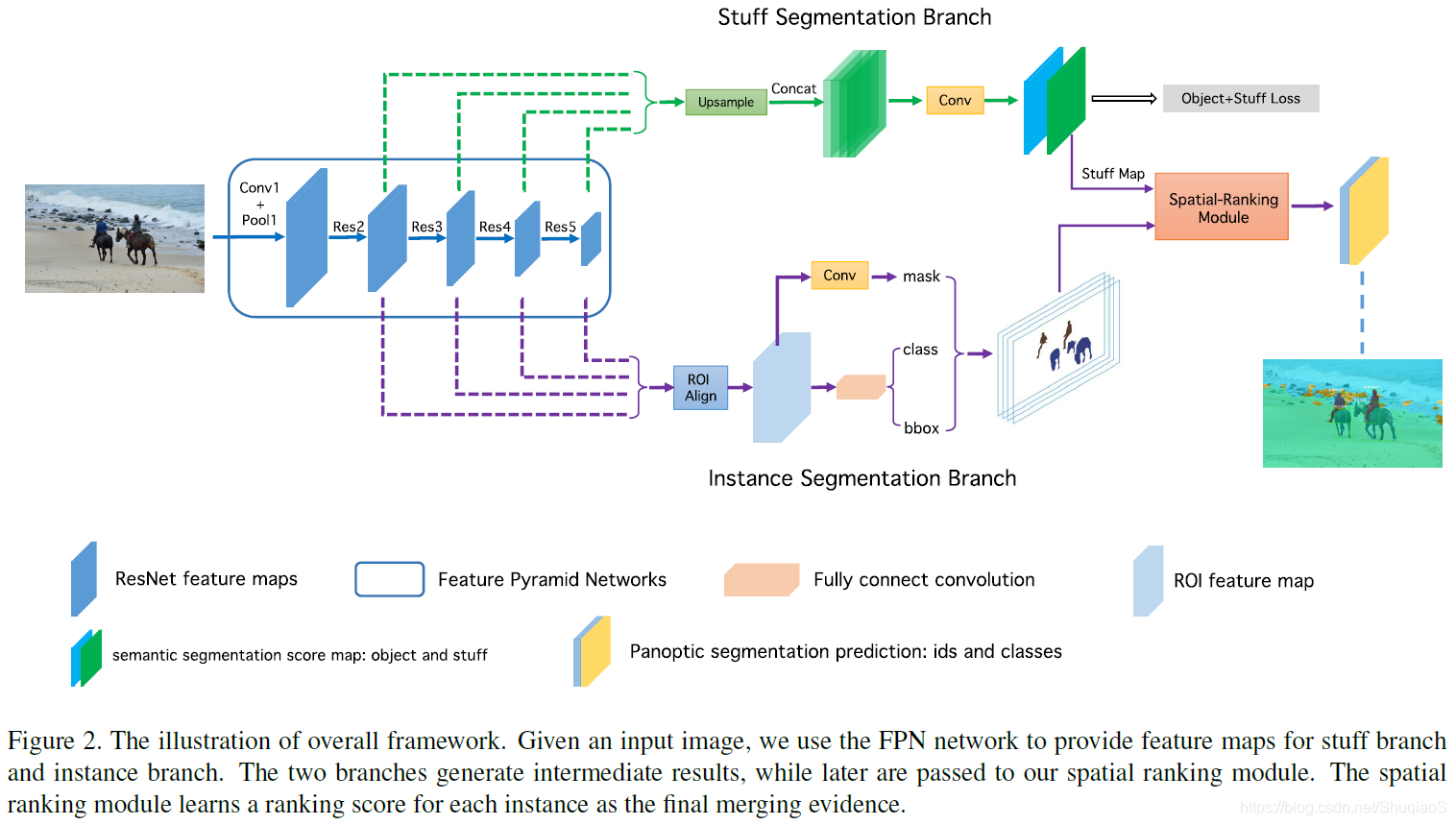
端到端网络结构
利用FPN作为基本结构,实例分割部分用原始的Mask R-CNN结构。应用自上而下的通路和横向连接提取特征图,随后用3x3的卷积层获取RPN(Region Proposal Network)特征图。之后,应用ROIAlign层提取目标proposal特征,并得到三个估计:proposal classification score, proposal bounding box coordinates, and proposal instance mask。
对于语义分割分值,两层3x3的卷积层堆叠在RPN特征图上。为了多尺度特征提取,随后将这些层级联在一起,送入一层3x3的卷积层和一个1x1的卷积层。下图是这个分支的详细结构:
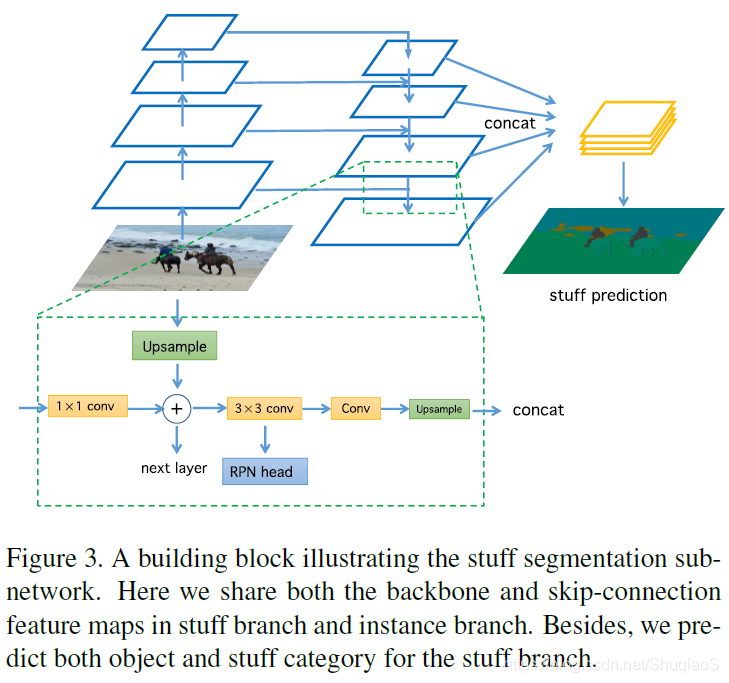
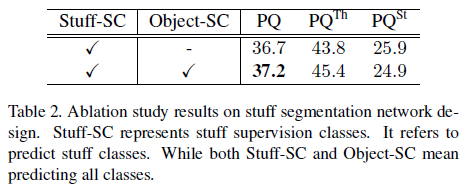
在训练过程中,同时监督两个分支。在测试时,只提取stuff分支的估计,并将其归一化成概率。
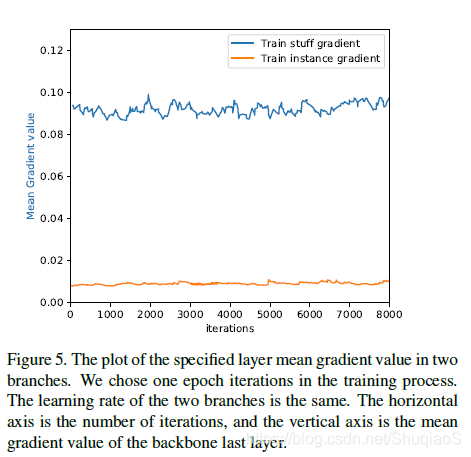
两个分支共用特征引起了两类问题:1)特征图上的共享粒度(granularity)和2)instance loss和stuff loss的平衡。在实践中,论文作者发现共享的特征图越多,表现越好。因此,直到skip connections之前都共享特征图,也就是Figure 3中的RPNhead之前的3x3卷积层。
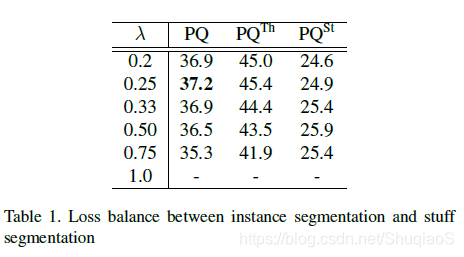
为了平衡两个监督任务,提出了如下损失:
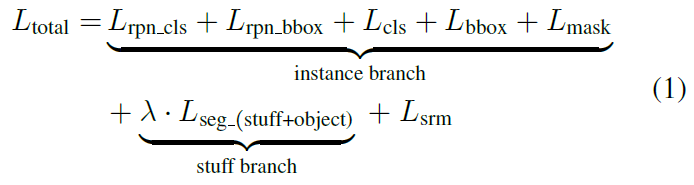
实例分支包括5个损失:

语义分割分支只有一个损失:
。
表示空间排序模块的损失。
空间排序模块
通常,是用detection score来分配实例,即score更大的实例在score更小的实例上面。但是这种方法在实际应用中很容易失败。比如,一个人系了一条领带,如下图所示:

由于在COCO数据库中,类别“人”出现的概率比“领带”出现的概率高,其detection score也倾向于比“领带”的高。此时,根据上述标准,领带就会被类别“人”覆盖掉,从而导致分割效果的下降。论文中提出的spatial ranking module如下图所示:
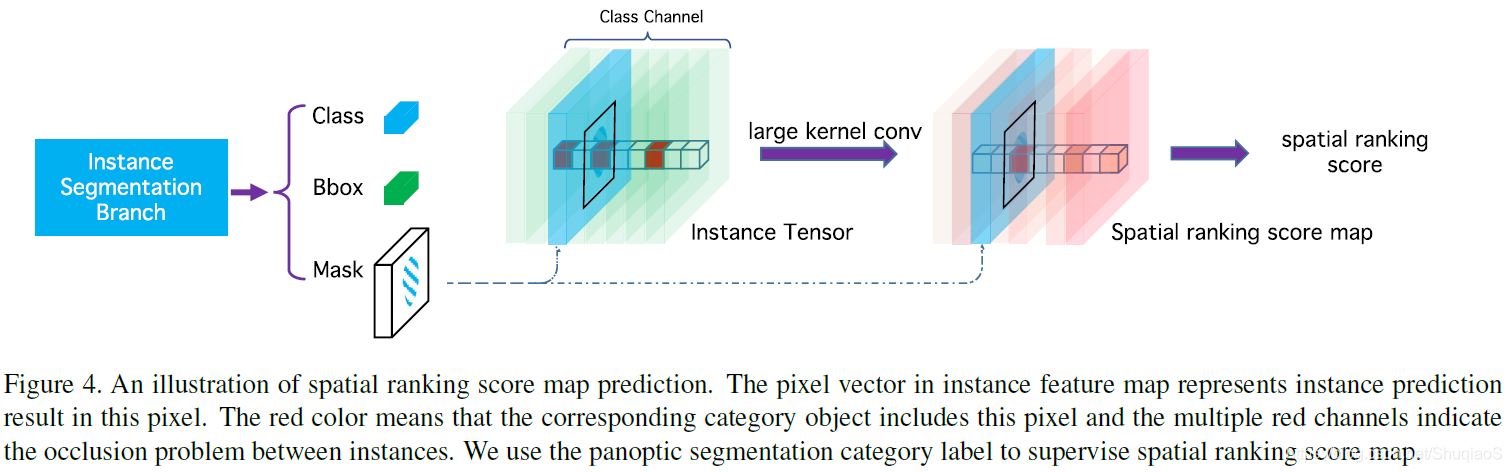
首先将实例分割的结果映射成输入尺寸的张量,特征图张数等于类别数,不同类别的实例被映射到不同特征图上。实例张量初始化为0,映射值为1。之后,对该张量应用large kernel convolution,得到ranking score map。最后,用pixel-wise cross entropy loss优化ranking score map,公式如下:
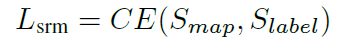
其中,
代表输出ranking score map,
代表对应的non-overlap语义标签。
得到ranking score map后,用下式计算每个实例的ranking score:
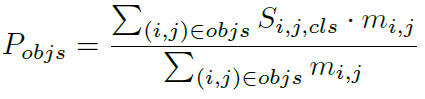
其中,
代表在
处的类别
的ranking score,归一化到概率形式。
是表示是否属于这个实例的mask indicator。整个实例的ranking score
由整个mask中全部像素点的ranking score平均得到。
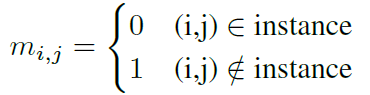
Experiments
数据库和度量
数据库:COCO
度量:
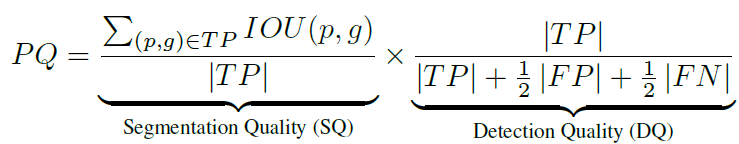
实验细节


网络结构剥离实验



Conclusion
