摘要
全景图分割是通过统一以往语义分割和实例分割任务,称为视觉识别任务的新标准。
1.在本文中,我们提出并探索了一种新的视频扩展任务,称为视频全景分割。该任务要求生成一致的全景分割以及跨视频帧的实例ID关联。
2.为了激励对这一新任务的研究,我们提出了两种类型的视频全景数据集。第一个是将合成的VIPER数据集转换为视频全景格式,以利用其大规模标注。第二个是Cityscapes val.set的时间扩展,通过提供新的视频全景注释(Cityscapes-VPD)。它通过每5个视频帧的像素级全景标签,将Cityscapes扩展到视频级别。
3.此外,我们提出了一个新的视频全景分割网络(VPSNet),它可以联合预测视频帧中的对象类、边界框、掩码、实例id跟踪和语义分割。
4.为了这项任务提供适当的指标,我们提出了一个视频全景质量(VPQ)指标,并评估了我们的方法和其它对比。
引言
在本文中,我们将图片域中的全景分割扩展到视频域中。与图像全景分割不同,新问题旨在同时预测对象类别、边界框、掩码、实例ID关联和语义分割,同时为视频中的每一个像素分配唯一的答案。图1展示了这个问题的GT视频序列示例。我们将这项新任务命名为视频全景分割(VPS)。
我们提出了两种类型的视频全景数据集。第一个是将合成的VIPER数据集转换为视频全景格式,以利用其大规模标注。第二个是Cityscapes val.set的时间扩展,通过提供新的视频全景注释(Cityscapes-VPD)。它通过每5个视频帧的像素级全景标签,将Cityscapes扩展到视频级别。
此外,我们提出了一个新的视频全景分割网络(VPSNet),为这项新任务提供了一种Baseline方法。在UPSNet的基础上,我们涉及了VPSNet,在像素级融合和目标级跟踪两个层次上,以额外的帧作为关联时间信息的参考。为了提取参考帧的互补特征点,我们提出了一种基于流的特征图对齐模块以及一个不对称的注意块,该模块计算目标和参考特征之间的相似性,将它们融合在一帧形状中。此外,为了跨时间关联对象实例,我们添加了一个目标跟踪头,该跟踪头根据目标和参考帧的Rol特征相似度来学习实例之间的对应关系。
我们采用标准的图像全景质量(PQ)度量来适应视频全景质量(VPQ)格式。具体来说,该度量是从多个帧的跨度中获得的,其中跨度内的每个全景段的序列被认为是一个单一的3D tube预测,以产生与GT的IOU。时间跨度越长,获得超过阈值的IOU并将其计算为最终VPQ分数的TP就越有挑战性。我们使用VPQ度量对我们提出的方法与其它几个Baseline进行评估。
文章贡献
1.第一次正式定义和探索视频全景分割VPS
2.提供重新转换VIPER数据集和基于Cityscapes数据集创建新的视频全景标签,给出了第一个VPS数据集。这两个数据集在构建一个准确的VPS模型时是互补的。
3.提出了一种新的VPSNet,在Cityscapes和VIPRER数据集上实现了最高的PQ,并于新数据集上的几个Baseline进行了比较
3.提出了一个评价指标:视频全景质量VPQ来度量预测和GT的时空一致性。VPQ验证了我们提出的数据集和方法的有效性。
问题定义
Task Format:对于一个包含T帧的视频序列,我们设置一个跨越K个连续帧的时间窗口。给定一个K-span片段It:t+k = {It,It+1,…, It+k},我们将一个tube预测定义为其帧级段的轨迹ˆu(ci,zi) ={ˆst,…,ˆst+k}(ci,zi),作为tube的分割类别c和实例id z。thing类的实例id zi可以大于0,例如car-0, car-1,…,而对于stuff类,例如sky,它总是0。视频中的所有像素都通过这种tube预测进行分组,它们将会产生一组相互关联的stuff和thing视频tube。GTtube的定义类似,但注释频率略有调整,如下所述。视频全景分割的目标是精确定位整个视频中的所有语义边界和实例边界 ,并为这些分割的视频tube’分配正确的标签。
Evaluation Metric:通过构建VPS问题,视频tube之间不可能存在重叠。因此,在目标检测或分割的AP指标就不能用于评估VPS任务。相反,我们借助图形全景分割中的全景质量PQ指标,并对其进行修改以适应我们的新任务。
给定一个片段It:t+k,我们将一组GT和预测tube表示为Ut:t+k和ˆUt:t+k。一组真正匹配定义为TP={(u,ˆu)∈ U׈U:IoU(U,ˆU)>0.5}。相应地定义了假阳性(FP)和假阴性(FN)。当注释给定每个λ帧时,匹配只考虑一个片段中带注释标记的帧指标t: t+ k: λ (start: end: stride),例如,当k = 10和λ = 5时,考虑帧t, t+5和t+10。我们在整个视频中以λ的步幅滑动k跨度窗口,从帧0开始到结束,即t经过0:t−k: λ(我们假设帧0是带注释的)。每一步都构建一个新的片段,我们在其中计算上面提到的iou、TP、FP和FN。
在数据集级别,片段级别的IoU、| TP |、| FP |和| FN |值在所有预测视频中收集。然后,根据每个类c计算数据集级别的VPQ度量,并在所有类中求平均值,如下所示: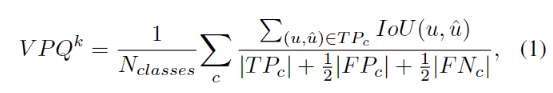
其中,分母中的1/2 |FP| + 1/2 |FN|是为了惩罚预测错误的tube,如图像PQ度量的那样。
根据定义,K=0将使得评价指标等于图形PQ指标,并且K=T-1将构造一系列完整的video-long tubes。任何语义或实例标签预测的跨帧不一致都将导致一个低的tube IOU,并可能会将TP中去掉,如图2所示。因此,窗口尺寸越大,获得高VPQ评分就越难。实际上,我们包含不同窗口的大小k∈ {0,5,10,15}提供更全面的评估。通过对K=4进行平均,计算最终VPQ,如下所示: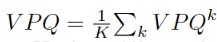

使用不同的K值可以实现从现有图形PQ评估到视频的平滑过渡。
Dataset Collection
Existing Image-level Benchmarks:现有的图像级基准:有几个公共数据集具有密集的全景分割符号:Cityscapes [5], ADE20k [41], Mapillary[25]和COCO[23]。然而,这些数据集都不符合我们的视频全景分割任务的要求。因此,我们需要准备一个合适的数据集来开发和评估视频全景分割方法。在收集VPS数据集时,我们有几个方向。首先,注释的质量和数量都要高,其中注释的质量和数量是现有多边形分割数据集中普遍存在的问题,而注释的成本又高,限制了注释的质量和数量。更重要的是,它应该易于适应和扩展现有的基于图像的全景数据集,从而促进研究界在图像和视频领域之间无缝地转移知识。基于上述方向,我们通过1)重新格式化VIPER数据集和2)基于cityscape数据集创建新的视频全景注释来呈现两个VPS数据集。
Revisit ing VIPER dataset:重新访问VIPER数据集:为了最大化VPS任务可用注释的质量和数量,我们利用了从GTA-V游戏引擎中提取的合成VIPER数据集[32]。它包括基于254K帧、1080 × 1920分辨率、以自我为中心的驾驶场景的10个事物和13个事物类的基于像素的语义注释和实例分割。如图1-(顶部一行)所示,我们将它们的注释调整为我们的VPS格式,并以流行的COCO风格创建元数据,这样它就可以无缝地插入最近的识别模型,如Mask-RCNN。
Cityscapes-VPS我们不是独立地从头开始构建数据集,而是在最流行的公共城市景观数据集以及COCO上构建全景分割的基准数据集。它由以自我为中心的驾驶场景的图像级注释帧组成,其中每个标记帧是30帧视频片段中的第20帧。有2965、500和1525张这样的采样图像,分别与8个事物类和11个事物类的密集全景注释配对,用于训练、评估和测试。具体来说,我们选择验证集来构建我们自己的视频级扩展数据集。我们从500个视频中每五帧采样一次,然后让人仔细地用所有19个类标记每个像素,并为对象分配时间上一致的实例ID,如图1所示。我们得到的数据集以1024×2048的分辨率为3000帧提供了密集的全景注释,每个视频中的帧之间都有实例id关联。新基准称为城市景观VPS。

我们的新数据集Cityscapes VPS不仅是视频全景分割的第一个基准,而且也是视频实例分割和视频语义分割等其他视觉任务的有用基准;后者也一直缺乏成熟的视频基准。我们在表1中显示了重新格式化的VIPER和新城市景观VPS的一些高级统计数据以及相关数据集。
Network Design
Overview:由于VPS任务的性质,任何类标签和实例id的时间不一致都会导致这些全景分割序列的低视频质量。因此对thing类的严格要求也就到位了。考虑到这一点,我们在VPSNet中设计了两个级别的视频上下文:像素级和对象级。第一个是为下游多任务分支利用相邻帧的特征,第二个是显式地将跨帧实例建模为专门用于跟踪的关联。特征融合和目标跟踪的各个模块单独使用并不是全新的,但它们首次联合用于视频全视域分割任务。我们在整个论文中称它们为Fuse和Track模块。整个模型体系结构如图3所示。

Baseline:我们建立在图像级全景分割网络之上。在不敏感于任何特定的基线网络设计的情况下,我们选择了最先进的方法,UPSNet,它采用Mask R-CNN和可变形卷积等,分别采用语义分割分支,并结合这两个分支的全景头。其中一个修改是,为了算法的简单性,我们不使用未知的类预测。此外,我们还有一个额外的非参数颈部层。他们使用平衡的语义特征来增强pyramidal neck的表示。与他们不同的是,我们的主要设计目的是在单一的分辨率水平上拥有一个具有代表性的feature map本身。由于这个原因,我们的extra neck仅由没有附加参数的gather和redistribute步骤组成。首先,在gather步骤,将输入特征金字塔网络(FPN)特征{p2, p3, p4, p5}调整为与p2相同大小的最高分辨率,并在多个层次上逐元素求和,得到f。然后,通过残差相加将该代表性特征重新分布到原始特征中。
Fuse at Pixel Level:主要思想是利用视频上下文,通过时间特征融合来改善每帧特征。在每一个时间步长t,特征提取器给定一个目标帧It和一个(或多个)参考帧It−τ,生成FPN特征{p2, p3, p4, p5}t和{p2, p3, p4, p5}t−τ。我们用τ∈{t−5:t + 5}对参考帧进行采样。
我们在收集和重新分发步骤之间提出了一个align-and-attribute管道。根据收集的特征ft和ft−τ,我们的align模块学习流扭曲以对齐参考特征ft−τ到达目标特征ft。校准模块接收初始光流φinit t→T−τ由FlowNet2[13]计算,并对其进行细化,以获得更精确的深层特征流。在连接这些对齐的特征后,我们的ATTAIN模块学习时空注意,以重新加权特征,并将时间维度融合为一个维度以获得gt,然后将gt重新分配到{p2、p3、p4、p5}t,然后将其转发给下游实例和语义分支。
Track at Object level:这里,目标是跟踪It中的所有对象实例与It−τ中的实例。在多任务头部用于全景分割的同时,我们添加了MaskTrack头部[38],该头部用于最先进的视频实例分割方法。它在生成的n个RoI建议{r1, r2,…{r1, r2,…rm}t−τ from It−τ。对于每一对{ri,t, rj,t−τ},一个Siamese全连通层将它们嵌入单个向量{ei,t, ej,t−τ},然后余弦相似度由Aij = cos (ei,t, ej,t−τ)度量。
MaskTrack是为静态图像设计的,只使用外观特征,在训练期间不使用任何视频特征。为了解决这一问题,我们将跟踪分支与时间融合模块相结合。具体来说,每个RoI特征{r1, r2…Rn}t首先通过上述来自多帧的时域融合特征gt增强,从而在被输入跟踪分支之前具有更强的分辨力。因此,从实例跟踪的角度出发,VPSNet在像素级和对象级对其进行同步。像素级模块对实例的局部特征进行比对,将其在参考帧和目标帧之间传递,而对象级模块则侧重于通过对时间标记的感兴趣区域特征的相似性函数将目标实例与其他参考对象区分开来。在训练过程中,我们VPSNet中的跟踪头与[38]相同。在推断阶段,我们从全景头部添加了一个额外的线索:thiing logits的IoU。实例logits可以看作是帧间的变形因子或空间相关性,实验表明它提高了thing类别的视频图像质量。
Implementation Details:我们遵循Mask R-CNN和其它全景分割模型的大部分设置和超参数,如UPSNet。在整个实验中,我们使用Resnet-50 FPN作为特征提取部分。
Train:我们使用MMDetection [2]工具箱,在Pytorch [29]中实现我们的模型。我们使用具有8个GPU的分布式训练框架。每个Mini-Batch每个GPU都有1个图像。我们使用参考框架的地面真相框来训练轨道头。在随机将每个帧随机缩放0.8至1.25×随机缩放后,我们在1024×2048城市景观和1080×1920 Viper图像中播出800×1600像素。由于图像的高分辨率,我们将语义头部和Panoptic Head的登录缩小到200×400 Pix-els。除了RPN损失之外,我们的VPSNet总共包含6个任务相关的损耗功能:Bbox头(分类和边界盒),面罩头,语义头,Panoptic Head和轨道头。我们将所有损失重量设置为1.0,以使其尺度大致相同的数量级。
我们将所有数据集的学习率和权重衰减设置为0.005和0.0001。对于VIPER,我们训练12个epochs,在8和11个纪元epochslr衰减。对于城市景观和城市景观- vps,我们训练144个epochs,在96和128个epochs应用lr衰减。对于预训练的模型,我们导入COCO或viper预训练的基础模型参数,并通过kaiaim初始化初始化其余的层,例如Fuse (align- and-attend)和Track模块。
Inference:给定一个新的测试视频,我们的方法以在线方式顺序处理每一帧。在每一帧,我们的VPSNet首先生成一组实例假设。作为一个掩码修剪过程,我们执行类无关的非最大值抑制,框IoU阈值为0.5,以过滤掉一些冗余框。然后,根据预测的类别概率对剩余框进行排序,如果概率大于0.6,则保留该框。对于视频序列的第一帧,我们根据概率顺序分配实例ID。对于所有其他帧,修剪后的剩余框根据学习到的相似性A与先前帧中识别的实例相匹配,并相应地分配实例id。在处理所有帧后,我们的方法产生一系列全景分割,其中每个像素在整个序列中包含一个唯一的类别标签和实例标签。对于IPQ和VPQ评估,我们使用单尺度测试测试所有可用模型。
实验结果


