摘要
在这项工作中,我们引入了Panoptic-DeepLab,一个简单、强大、快速的全景分割系统,旨在为bottom-up方法建立一个baseline,可以实现与两阶段方法相当的性能,同时产生快速的推理速度。特别是,Panoptic-Deeplab分别采用了针对语义和实例分割的双ASPP和双解码结构。语义分割分支与任何语义分割模型(如DeepLab)的典型设计相同,而实例分割分支是class-agnostic,包括一个简单的示例中心回归。
引言
由于最近提出的全景质量度量和相关的识别挑战,统一了语义分割和实例分割的全景分割受到了广泛关注。全景分割的目标是为图像中的每个像素分配一个唯一的值,包括语义标签和实例id。它需要识别图像中每一个“事物”的类别和范围,并标记所有可能的像素。
全景分割的目的:对每个像素点给予不同的label + instance ID(如果对于stuff,比如地面,背景,不需要instance ID)
总体来说目前有2种流行思路:Top-down & Bottom-up:
Top-down方式基本上可以认为在Mask-RCNN的基础上接一个语义分割的头部,但是这种方式会造成语义分割和实例分割之间的冲突(因为一个像素点可能被实例分割成一类,但语义分割又变成了另一类),为了解决这个问题,就需要通过某种设定的方式来融合语义分割的score + 实例分割的score
由于top-down的方式会有一个很长的pipeline(RPN + RCNN/Mask),外加一个semantic,因此通常会比较慢
bottom-up:先生成语义分割的信息,然后根据语义分割以及其他信息将语义分割的同类、同实例的像素点归并到一起。bottom-up系列和top-down相比更快,性能
Top-down方法面临的困难,以及之前对互补方法的研究的缺乏,促使我们建立一个简单、强大、快速的bottom-up的全景分割baseline。我们提出的前景式DeepLab在训练期间只需要三个损失函数,并且在构建现代语义分割模型时引入额外的边界参数和额外的计算量。所提出的全景式DeepLab的设计在概念上很简单,分别采用了针对语义分割和实例分割的双ASPP和双解码器模块。语义分分支遵循任何语义分割模型的典型设计,而实例分割分支涉及简单的实例中心回归,其中模型学习预测实例中心以及每个像素到其对应中心的偏移,通过将像素分配到其最接近的预测中心,从而产生极其简单的分组操作。

网络结构
Panoptic-DeepLab由四个部分组成:
1.一个用于语义分割和实例分割的编码器骨干
2.解耦的ASPP模块
3.特定于每个任务的解码器模块
4.特定于每个任务的预测头
Basic architecture
编码器骨干网络采用imagenet预训练的神经网络和Atrus卷积相结合的方法,用于其最后一个block。基于这两个分支需要不同的上下文和解码器信息的假设,我们分别使用ASPP和解码器模块进行语义分割和实例分割,在下一节得到验证。我们的轻量级解码器模块经过两次修改后实现了DeepLabv3+:1.我们引入了一个额外stride为8的低级特征图到解码器,因此空间分辨率恢复为2倍。2.在每个上采样阶段,我们使用一个5*5深度可分离卷积。
Semantic segmentation head
我们采用加权自举交叉熵损失函数进行语义分割,预测“thing”和“stuff”的类别。通过对每个像素进行不同的加权,这种损失较于自举交叉熵损失有所改善。
Class-agnostic instance segmentation head
根据Hough投票,我们通过质心来表示每个对象实例。对于每个前景像素(即类别为“thing”),我们进一步预测其到对应质心的偏移。在训练使其,GT实例中心由标准偏差为8像素的二维高斯算法进行编码。我们采用均方差损失来最小化一簇额热力图和二维高斯编码的GT热力图之间的距离。我们使用L1损失进行偏移预测,仅在属于对象实例的像素时激活。在推理过程中,预测的前景像素(通过从语义分割预测中过滤掉背景区域获得)被分组到其最接近的预测质心,形成我们的不可知类的分割结果。
Panoptic Segmentation
在推理阶段,我们使用非常简单的分组操作来获取实例掩码,并使用高效的多数投票算法将语义和实例分割合并到最终的全景分割中。
- Simple instance representation:我们简单的用其质心来表示每个对象。为了获得中心点预测,我们首先对实例中心热力图进行基于关键点的非极大值抑制,本质上相当于对热力图预测应用最大池化,并保持最大池化前后的值不变。最后使用硬阈值来过滤掉置信度低的预测,只保留置信度最高的位置。
- Simple instance grouping:为了获得每个像素的实例id,我们使用一个简单的实例中心回归。例如,考虑在位置(i,j)的一个预测的“thing”像素,我们预测一个偏移向量O(i,j)到它的实例中心。O(i,j)是一个包含两个元素的向量,分别表示水平方向和垂直方向的偏移量。因此,像素的实例id是在像素位置(i,j)移动偏移量O(i,j)后最近的位置中心的索引。我们使用语义分割预测来过滤掉实例id总是设置为0的“stuff”像素
- Efficient merging:考虑到预测的语义分割和类别不可知的实例分割结果,我们采用一种快速且可并行化的方法来合并结果,遵循DeeperLab中提出的“多数投票”原则。具体地说,预测实例掩码的语义标签是通过相应的预测语义标签的多数投票来推断的。这个操作本质上是累积类标签直方图,因此在GPU中有效地实现,当操作1025 ×2049输入时只需要3毫秒。
Instance Segmentation
Panopics DeepLab还可以生成作为副产品实例分段预测。为了正确评估实例分割结果,需要将置信度得分与每个预测的实例掩码相关联。以前的自底向上实例分割方法使用一些启发式的方法来获得置信度分数。例如,DWT[2]和SSAP[23]对一些简单的类使用平均语义分段分数,对其他较难的类使用随机分数。此外,对于每个类,它们移除面积低于某个阈值的掩码。另一方面,我们的Panopics DeepLab不采用任何启发式或后处理来进行实例分割。受YOLO的启发,我们计算每个实例掩码的特定于类的置信度得分,如下所示:
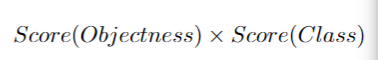
实验


