最近研究OCR,有篇比较好的算法文章,《EAST: An Efficient and Accurate Scene Text Detector》,该文发表在2017年CVPR上。代码地址:https://github.com/argman/EAST ,这是原作者参与的一份tensorflow版本代码,网上还有其他的实现。
下面根据原文的结构和上述提供的代码详细的解读一下该算法
一、网络架构
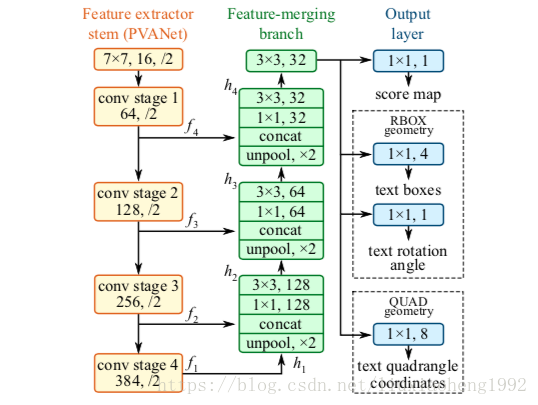
文中使用了PVANet和VGG16,下图1是原文的网络结构图(PVANet)
网络输入一张图片,经过四个阶段的卷积层可以得到四张feature map, 分别为
,它们相对于输入图片分别缩小
,之后使用上采样、concat(串联)、卷积操作依次得到
,在得到
这个融合的feature map后,使用大小为
通道数为32的卷积核卷积得到最终的feature map。
文中对文本框的定义有两种,一种是旋转矩形(RBOX),另一种是四边形(QUAD)。因为代码只实现了RBOX,所以下面也只对RBOX框进行分析
得到最终的feature map后,使用一个大小为 通道数为1的卷积核得到一张score map用 表示。在feature map上使用一个大小为 通道数为4的卷积核得到text boxes,使用一个大小为 通道数为1的卷积核得到text rotation angle,这里text boxes和text rotation angle合起来称为geometry map用 表示。
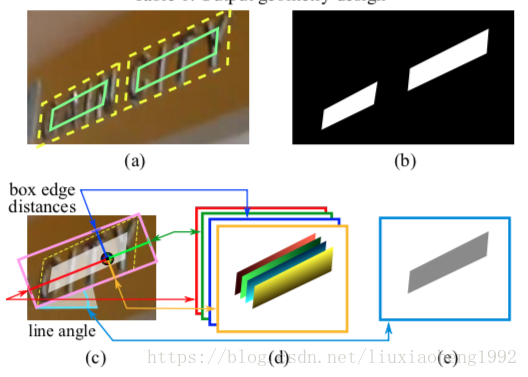
关于上述的 要说明几点(如下图2所示):
- 大小为原图的 通道数为1,每个像素表示对应于原图中像素为文字的概率值,所以值在[0,1]范围内。
- 大小也为原图的 通道数为5,即4+1(text boxes + text rotation angle)。
- text boxes通道数为4,其中text boxes每个像素如果对应原图中该像素为文字,四个通道分别表示该像素点到文本框的四条边的距离,范围定义为输入图像大小,如果输入图像为512,那范围就是[0,512]。下图2d表示
- text rotation angle通道数为1,其中text rotation angle每个像素如果对应原图中该像素为文字,该像素所在框的倾斜角度,角度范围定义为[-45,45]度。下图2e表示
二、关于训练标签的生成
如上可知,训练标签由两个部分组成,一个是score map的标签,一个是geometry map标签。
注意:程序要求输入的四边形标定点是以顺时针方向标定的,这点很重要
1. score map标签的生成方法
- 首先生成一个与图片大小一样的矩阵,值都为0
- 根据标定好的四边形框对该四边形框进行缩小,缩小方法下面会详细说明,得到最终结果如上图2a中的绿框
- 将绿框中的像素赋值1表示正样本的score,其他为负样本的score
- 最后按照每隔4个像素采样,得到图片 大小的score map
上述缩小四边形的方法:
- 首先定义四个顶点 ,这四个顶点按照顺时针方向排列
- 计算缩小的参考大小如下式所示,下式表示的是选取与顶点相连的两条边中最小的边的大小记为
其中 表示点 与 之间的距离 - 对于边$ p_{i}, p_{(i mod 4)+1}$,缩小 与 的和的像素大小
2. geometry map标签的生成方法

- 首先生成一个与图片大小一样的5通道矩阵用来制作text boxes 与 text rotation angle
- 根据标定的四变形生成一个面积最小的平行四边形,进而得到平行四边形的外界旋转矩形
- 根据旋转矩形的四个点坐标,可以选择出y值最大的坐标顶点和该顶点逆时针方向的顶点(也可以称该顶点右边的顶点),根据这两个点的连线可以求出连线与x轴的夹角,这个夹角取值在(0,90)度之间,称这个夹角为angle
- 当angle<45度时,定义y值最大的点为 点,其它点按顺时针方向依次类推。当angle>45度时,定义y值最大的点为 点,此时angle角变换为 ,这样就保证了angle角度[-45,45]度
- 上述还有一种特殊情况要考虑,当y值最大的点有两个时,说明矩形与x轴平行,angle定义为0度,这时候将x与y坐标相加最小的点定义为 点,其它点依次类推
- 根据得到的旋转矩形和angle值将geometry map的五个通道赋值,赋值方法为,对于text boxes的四个通道,每个通道表示图像中的像素点坐标到旋转矩形的四个边的距离顺序为,0通道表示点到 与 边的距离,1通道表示点到 与 边的距离,按照顺时针依次赋值四个通道,也分别称为到top、right、bottom、left边的距离,对于text rotation angle这一个通道,将旋转矩形中所有像素都赋值上述计算出的angle大小
- 最后得到的五个通道按照每隔4个像素采样,这样就可以得到图片 大小的geometry map了
三、损失函数的定义
损失函数定义如下
其中
和
分别表示score map和geometry map的损失,
表示两个损失的权重,文章设为1
1. score map的损失计算
这里要说明的是文章采用的是交叉熵计算该损失,但是程序实现没有采用,程序采用的是dice loss
其中
代表位置敏感图像分割(position-sensitive segmentation)的label,
代表预测的分割值
2. geometry map的损失计算
采用IoU loss,计算方法如下
其中
-
其中, 表示预测, 表示真实值
计算可以通过下述方法
其中 表示点到top、right、bottom、left边的距离。
-
,其中 表示预测值, 表示真实值
最后文章还提出了Locality-Aware NMS,感觉就是先合并一次窗口,然后采用标准的NMS去抑制窗口,详细可以看代码实现,采用的是c++实现的
欢迎加入OCR交流群:785515057