论文链接:
https://arxiv.org/abs/1506.02640
文章大意:
目标检测的需求是在图片中定位物体,即估计一个BOX将待定位物体“框住”。对于一类物体的detection涉及的就是估计BOX的边界(一般的有两种BOX的描述,即中心点及宽度或直接给出边界坐标),对于多类物体的detection,还要给出估计BOX的分类置信度。根据对上述两个任务(detection \ classify)的不同处理方式。所使用的模型分为单阶段及多阶段的,前者对应在单个模型结构同时解决两类问题、后者对应利用不同的结构解决对应的问题。
多阶段的一个例子是R-CNN。其基本思想是利用卷积结构抽象特征,之后进入全连接层,学习到一个dense特征,利用这个特征进入SVM完成对BOX分类判定的置信度刻画,也利用这个特征完成bboxing regression (确定BOX具体坐标)。
单阶段的一个例子就是本文要提到的YOLO。其基本思想是将类别判定与坐标学习放在一个任务中,假设其作为一个卷积结构的统一输出(即分类概率与坐标值位于单个卷积pixel输出的不同通道位置),故在数值上要“控制”不同通道的值(施加一些关于位置的数值变换,否者数值不稳定)。其利用回归结构一致的学习了分类概率及
坐标值。下面是网络结构图:
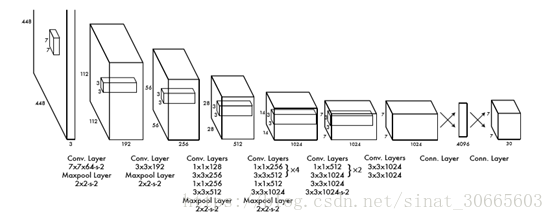
上面是一个24个conv层的YOLO上卷积结构,添加了两个FC层。(在R-CNN中FC层地作用为分类做特征抽取,从直觉上来讲,FC层会损失图形的空间结构,但是这里(YOLO)在进行特征提取的过程中直觉上是不需要FC层的,因为最后的输出仍是一个类似卷积的结构,一些观点认为目标检测常常采取FC作为中间层的原因是学习卷积可能丢失的目标position信息,相应观点见:
)。最后的channel维度30的构成为 B * 5 + C,这里B为使用的anchor的数量,C为分类类数(在原文的例子中为20,相应元素为分类概率),5对应x, y,(中心坐标) w, h(宽长)及该pixel包含目标的概率。
关于最后一个channel的组成结构,其与语义分割及landmarks是不同的,后两者更多地可以看成是一种分类标注问题,所以通道对应类别及背景的维度,而目标检测为多个类别的detect,需要用pixel包含目标的概率来控制(存在有无及数量问题),这是其通道结构与后二者不同的一个原因。
引入anchor的原因在于使得有更大的可能“覆盖”(与目标产生更多的“交集”——参见IOU概念),使得多个anchors进行覆盖的原因还有在估计detection的时候要将这个问题看成一个“解码”问题(类比的,可以想到seq2seq中的生成序列解码),在这里相当于增加cover目标的“可能性”,类似于序列生成问题中的解码问题也会出现,如beam search算法,那里是对于一个序列生置信度最大化的解码过程,是一种“并集”意义上的最大化,不断加强与已知token有关的序列出现置信度,这里的多个anchor对于目标的解码是一种“交集”意义上的最大化,从有限的集合中选择出IOU与目标最大的那“若干个”,在一般情况下要处理多类BOX的保留问题,包括是否相交的关系,对应的用到算法NMS(non maximum suppression)。
上面提到,要对xywh对应通道做变换以使得数值稳定,其变换公式见下面:
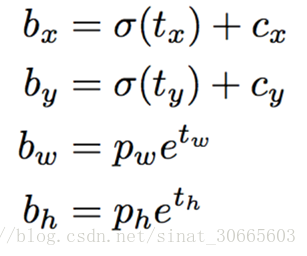
t即对应神经网络对应通道的输出,sigma为sigmoid function。c为对应grid坐标(这里就是7 x 7),p对应经验选取的anchor值。
有了上述变换后如下构造回归损失:
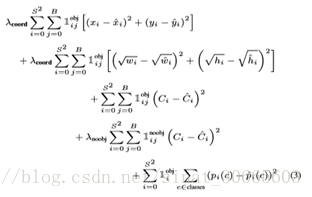
示性函数描述是否有包含object,xywh见上文,C为pixel包含object的概率,p(c)为该object属于某一类的概率,lambda为调节参数。
原文中还提到了FAST YOLO是对应9个conv层的版本,具有更快的速度(YOLO主打的也是一个“快”字),精度也会下降。下面对于袋鼠识别数据集(单个类别)构建FAST YOLO并进行测试。(验证实现上的解码部分没有给出NMS实现,而是直接比较了最大置信度对应predection于ground truth的IOU值)。
数据处理部分(图片增强、label解析使用了https://github.com/experiencor/keras-yolo2
中的程序),下面尝试给出实现:
数据集下载:https://github.com/experiencor/kangaroo
数据导出:(使用keras-yolo2工程中utils.py及preprocessing.py两个脚本,并对后者添加一个数据导出函数,后者脚本变化后如下)
import os
import cv2
import copy
import numpy as np
from imgaug import augmenters as iaa
from keras.utils import Sequence
import xml.etree.ElementTree as ET
from utils import BoundBox, bbox_iou
ANCHORS = [0.57273, 0.677385, 1.87446, 2.06253]
def parse_annotation(ann_dir, img_dir, labels=[]):
all_imgs = []
seen_labels = {}
for ann in sorted(os.listdir(ann_dir)):
img = {'object':[]}
tree = ET.parse(ann_dir + "\\" + ann)
for elem in tree.iter():
if 'filename' in elem.tag:
img['filename'] = img_dir + "\\" + elem.text
if 'width' in elem.tag:
img['width'] = int(elem.text)
if 'height' in elem.tag:
img['height'] = int(elem.text)
if 'object' in elem.tag or 'part' in elem.tag:
obj = {}
for attr in list(elem):
if 'name' in attr.tag:
obj['name'] = attr.text
if obj['name'] in seen_labels:
seen_labels[obj['name']] += 1
else:
seen_labels[obj['name']] = 1
if len(labels) > 0 and obj['name'] not in labels:
break
else:
img['object'] += [obj]
if 'bndbox' in attr.tag:
for dim in list(attr):
if 'xmin' in dim.tag:
obj['xmin'] = int(round(float(dim.text)))
if 'ymin' in dim.tag:
obj['ymin'] = int(round(float(dim.text)))
if 'xmax' in dim.tag:
obj['xmax'] = int(round(float(dim.text)))
if 'ymax' in dim.tag:
obj['ymax'] = int(round(float(dim.text)))
if len(img['object']) > 0:
all_imgs += [img]
return all_imgs, seen_labels
class BatchGenerator(Sequence):
def __init__(self, images,
config,
shuffle=True,
jitter=True,
norm=None):
self.generator = None
self.images = images
self.config = config
self.shuffle = shuffle
self.jitter = jitter
self.norm = norm
self.anchors = [BoundBox(0, 0, config['ANCHORS'][2*i], config['ANCHORS'][2*i+1]) for i in range(int(len(config['ANCHORS'])//2))]
### augmentors by https://github.com/aleju/imgaug
sometimes = lambda aug: iaa.Sometimes(0.5, aug)
# Define our sequence of augmentation steps that will be applied to every image
# All augmenters with per_channel=0.5 will sample one value _per image_
# in 50% of all cases. In all other cases they will sample new values
# _per channel_.
self.aug_pipe = iaa.Sequential(
[
# apply the following augmenters to most images
#iaa.Fliplr(0.5), # horizontally flip 50% of all images
#iaa.Flipud(0.2), # vertically flip 20% of all images
#sometimes(iaa.Crop(percent=(0, 0.1))), # crop images by 0-10% of their height/width
sometimes(iaa.Affine(
#scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # scale images to 80-120% of their size, individually per axis
#translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)}, # translate by -20 to +20 percent (per axis)
#rotate=(-5, 5), # rotate by -45 to +45 degrees
#shear=(-5, 5), # shear by -16 to +16 degrees
#order=[0, 1], # use nearest neighbour or bilinear interpolation (fast)
#cval=(0, 255), # if mode is constant, use a cval between 0 and 255
#mode=ia.ALL # use any of scikit-image's warping modes (see 2nd image from the top for examples)
)),
# execute 0 to 5 of the following (less important) augmenters per image
# don't execute all of them, as that would often be way too strong
iaa.SomeOf((0, 5),
[
#sometimes(iaa.Superpixels(p_replace=(0, 1.0), n_segments=(20, 200))), # convert images into their superpixel representation
iaa.OneOf([
iaa.GaussianBlur((0, 3.0)), # blur images with a sigma between 0 and 3.0
iaa.AverageBlur(k=(2, 7)), # blur image using local means with kernel sizes between 2 and 7
iaa.MedianBlur(k=(3, 11)), # blur image using local medians with kernel sizes between 2 and 7
]),
iaa.Sharpen(alpha=(0, 1.0), lightness=(0.75, 1.5)), # sharpen images
#iaa.Emboss(alpha=(0, 1.0), strength=(0, 2.0)), # emboss images
# search either for all edges or for directed edges
#sometimes(iaa.OneOf([
# iaa.EdgeDetect(alpha=(0, 0.7)),
# iaa.DirectedEdgeDetect(alpha=(0, 0.7), direction=(0.0, 1.0)),
#])),
iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.05*255), per_channel=0.5), # add gaussian noise to images
iaa.OneOf([
iaa.Dropout((0.01, 0.1), per_channel=0.5), # randomly remove up to 10% of the pixels
#iaa.CoarseDropout((0.03, 0.15), size_percent=(0.02, 0.05), per_channel=0.2),
]),
#iaa.Invert(0.05, per_channel=True), # invert color channels
iaa.Add((-10, 10), per_channel=0.5), # change brightness of images (by -10 to 10 of original value)
iaa.Multiply((0.5, 1.5), per_channel=0.5), # change brightness of images (50-150% of original value)
iaa.ContrastNormalization((0.5, 2.0), per_channel=0.5), # improve or worsen the contrast
#iaa.Grayscale(alpha=(0.0, 1.0)),
#sometimes(iaa.ElasticTransformation(alpha=(0.5, 3.5), sigma=0.25)), # move pixels locally around (with random strengths)
#sometimes(iaa.PiecewiseAffine(scale=(0.01, 0.05))) # sometimes move parts of the image around
],
random_order=True
)
],
random_order=True
)
if shuffle: np.random.shuffle(self.images)
def __len__(self):
return int(np.ceil(float(len(self.images))/self.config['BATCH_SIZE']))
def num_classes(self):
return len(self.config['LABELS'])
def size(self):
return len(self.images)
def load_annotation(self, i):
annots = []
for obj in self.images[i]['object']:
annot = [obj['xmin'], obj['ymin'], obj['xmax'], obj['ymax'], self.config['LABELS'].index(obj['name'])]
annots += [annot]
if len(annots) == 0: annots = [[]]
return np.array(annots)
def load_image(self, i):
return cv2.imread(self.images[i]['filename'])
def __getitem__(self, idx):
l_bound = idx*self.config['BATCH_SIZE']
r_bound = (idx+1)*self.config['BATCH_SIZE']
if r_bound > len(self.images):
r_bound = len(self.images)
l_bound = r_bound - self.config['BATCH_SIZE']
instance_count = 0
x_batch = np.zeros((r_bound - l_bound, self.config['IMAGE_H'], self.config['IMAGE_W'], 3)) # input images
b_batch = np.zeros((r_bound - l_bound, 1 , 1 , 1 , self.config['TRUE_BOX_BUFFER'], 4)) # list of self.config['TRUE_self.config['BOX']_BUFFER'] GT boxes
y_batch = np.zeros((r_bound - l_bound, self.config['GRID_H'], self.config['GRID_W'], self.config['BOX'], 4+1+len(self.config['LABELS']))) # desired network output
for train_instance in self.images[l_bound:r_bound]:
# augment input image and fix object's position and size
img, all_objs = self.aug_image(train_instance, jitter=self.jitter)
# construct output from object's x, y, w, h
true_box_index = 0
for obj in all_objs:
if obj['xmax'] > obj['xmin'] and obj['ymax'] > obj['ymin'] and obj['name'] in self.config['LABELS']:
center_x = .5*(obj['xmin'] + obj['xmax'])
center_x = center_x / (float(self.config['IMAGE_W']) / self.config['GRID_W'])
center_y = .5*(obj['ymin'] + obj['ymax'])
center_y = center_y / (float(self.config['IMAGE_H']) / self.config['GRID_H'])
grid_x = int(np.floor(center_x))
grid_y = int(np.floor(center_y))
if grid_x < self.config['GRID_W'] and grid_y < self.config['GRID_H']:
obj_indx = self.config['LABELS'].index(obj['name'])
center_w = (obj['xmax'] - obj['xmin']) / (float(self.config['IMAGE_W']) / self.config['GRID_W']) # unit: grid cell
center_h = (obj['ymax'] - obj['ymin']) / (float(self.config['IMAGE_H']) / self.config['GRID_H']) # unit: grid cell
######################################################################
box = [center_x, center_y, center_w, center_h]
# find the anchor that best predicts this box
best_anchor = -1
max_iou = -1
shifted_box = BoundBox(0,
0,
center_w,
center_h)
for i in range(len(self.anchors)):
anchor = self.anchors[i]
iou = bbox_iou(shifted_box, anchor)
if max_iou < iou:
best_anchor = i
max_iou = iou
# assign ground truth x, y, w, h, confidence and class probs to y_batch
y_batch[instance_count, grid_y, grid_x, best_anchor, 0:4] = box
y_batch[instance_count, grid_y, grid_x, best_anchor, 4 ] = 1.
y_batch[instance_count, grid_y, grid_x, best_anchor, 5+obj_indx] = 1
# assign the true box to b_batch
b_batch[instance_count, 0, 0, 0, true_box_index] = box
true_box_index += 1
true_box_index = true_box_index % self.config['TRUE_BOX_BUFFER']
# assign input image to x_batch
if self.norm != None:
x_batch[instance_count] = self.norm(img)
else:
# plot image and bounding boxes for sanity check
for obj in all_objs:
if obj['xmax'] > obj['xmin'] and obj['ymax'] > obj['ymin']:
cv2.rectangle(img[:,:,::-1], (obj['xmin'],obj['ymin']), (obj['xmax'],obj['ymax']), (255,0,0), 3)
cv2.putText(img[:,:,::-1], obj['name'],
(obj['xmin']+2, obj['ymin']+12),
0, 1.2e-3 * img.shape[0],
(0,255,0), 2)
x_batch[instance_count] = img
# increase instance counter in current batch
instance_count += 1
#print(' new batch created', idx)
return [x_batch, b_batch], y_batch
def on_epoch_end(self):
if self.shuffle: np.random.shuffle(self.images)
def aug_image(self, train_instance, jitter):
image_name = train_instance['filename']
image = cv2.imread(image_name)
if image is None: print('Cannot find ', image_name)
h, w, c = image.shape
all_objs = copy.deepcopy(train_instance['object'])
if jitter:
### scale the image
scale = np.random.uniform() / 10. + 1.
image = cv2.resize(image, (0,0), fx = scale, fy = scale)
### translate the image
max_offx = (scale-1.) * w
max_offy = (scale-1.) * h
offx = int(np.random.uniform() * max_offx)
offy = int(np.random.uniform() * max_offy)
image = image[offy : (offy + h), offx : (offx + w)]
### flip the image
flip = np.random.binomial(1, .5)
if flip > 0.5: image = cv2.flip(image, 1)
image = self.aug_pipe.augment_image(image)
# resize the image to standard size
image = cv2.resize(image, (self.config['IMAGE_H'], self.config['IMAGE_W']))
image = image[:,:,::-1]
# fix object's position and size
for obj in all_objs:
for attr in ['xmin', 'xmax']:
if jitter: obj[attr] = int(obj[attr] * scale - offx)
obj[attr] = int(obj[attr] * float(self.config['IMAGE_W']) / w)
obj[attr] = max(min(obj[attr], self.config['IMAGE_W']), 0)
for attr in ['ymin', 'ymax']:
if jitter: obj[attr] = int(obj[attr] * scale - offy)
obj[attr] = int(obj[attr] * float(self.config['IMAGE_H']) / h)
obj[attr] = max(min(obj[attr], self.config['IMAGE_H']), 0)
if jitter and flip > 0.5:
xmin = obj['xmin']
obj['xmin'] = self.config['IMAGE_W'] - obj['xmax']
obj['xmax'] = self.config['IMAGE_W'] - xmin
return image, all_objs
def train_ex_generator(batch_size = 2, box_buffer_size = 10):
train_annot_folder = r"C:\tempCodingUsage\python\kangaroo-master\annots"
train_image_folder = r"C:\tempCodingUsage\python\kangaroo-master\images"
labels = ["kangaroo"]
train_imgs, train_labels = parse_annotation(train_annot_folder,
train_image_folder,
labels)
generator_config = {
'IMAGE_H' : 448,
'IMAGE_W' : 448,
'GRID_H' : 7,
'GRID_W' : 7,
'BOX' : 2,
'LABELS' : labels,
'CLASS' : 20,
'ANCHORS' : [0.57273, 0.677385, 1.87446, 2.06253],
'BATCH_SIZE' : batch_size,
'TRUE_BOX_BUFFER' : box_buffer_size,
}
def normalize(image):
image = image[..., ::-1]
image = image.astype('float')
image[..., 0] -= 103.939
image[..., 1] -= 116.779
image[..., 2] -= 123.68
return image
train_generator = BatchGenerator(train_imgs,
generator_config,
norm=normalize)
while True:
for i in range(len(train_generator)):
[x_batch, b_batch], y_batch = train_generator[i]
# [batch, 448, 448, 3] [batch, 10, 4]
yield x_batch, np.squeeze(b_batch, axis=(1, 2, 3))
print("epoch yield end !")
yield None
if __name__ == "__main__":
pass
在网上找一些袋鼠测试图片,并用如下脚本做测试集导出:
import cv2
from PIL import Image
from imgaug import augmenters as iaa
import glob
import numpy as np
import random
aug_pipe = iaa.Sequential(
[
# apply the following augmenters to most images
#iaa.Fliplr(0.5), # horizontally flip 50% of all images
#iaa.Flipud(0.2), # vertically flip 20% of all images
#sometimes(iaa.Crop(percent=(0, 0.1))), # crop images by 0-10% of their height/width
iaa.Affine(
#scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # scale images to 80-120% of their size, individually per axis
#translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)}, # translate by -20 to +20 percent (per axis)
#rotate=(-5, 5), # rotate by -45 to +45 degrees
#shear=(-5, 5), # shear by -16 to +16 degrees
#order=[0, 1], # use nearest neighbour or bilinear interpolation (fast)
#cval=(0, 255), # if mode is constant, use a cval between 0 and 255
#mode=ia.ALL # use any of scikit-image's warping modes (see 2nd image from the top for examples)
),
# execute 0 to 5 of the following (less important) augmenters per image
# don't execute all of them, as that would often be way too strong
iaa.SomeOf((0, 5),
[
#sometimes(iaa.Superpixels(p_replace=(0, 1.0), n_segments=(20, 200))), # convert images into their superpixel representation
iaa.OneOf([
iaa.GaussianBlur((0, 3.0)), # blur images with a sigma between 0 and 3.0
iaa.AverageBlur(k=(2, 7)), # blur image using local means with kernel sizes between 2 and 7
iaa.MedianBlur(k=(3, 11)), # blur image using local medians with kernel sizes between 2 and 7
]),
iaa.Sharpen(alpha=(0, 1.0), lightness=(0.75, 1.5)), # sharpen images
#iaa.Emboss(alpha=(0, 1.0), strength=(0, 2.0)), # emboss images
# search either for all edges or for directed edges
#sometimes(iaa.OneOf([
# iaa.EdgeDetect(alpha=(0, 0.7)),
# iaa.DirectedEdgeDetect(alpha=(0, 0.7), direction=(0.0, 1.0)),
#])),
iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.05*255), per_channel=0.5), # add gaussian noise to images
iaa.OneOf([
iaa.Dropout((0.01, 0.1), per_channel=0.5), # randomly remove up to 10% of the pixels
#iaa.CoarseDropout((0.03, 0.15), size_percent=(0.02, 0.05), per_channel=0.2),
]),
#iaa.Invert(0.05, per_channel=True), # invert color channels
iaa.Add((-10, 10), per_channel=0.5), # change brightness of images (by -10 to 10 of original value)
iaa.Multiply((0.5, 1.5), per_channel=0.5), # change brightness of images (50-150% of original value)
iaa.ContrastNormalization((0.5, 2.0), per_channel=0.5), # improve or worsen the contrast
#iaa.Grayscale(alpha=(0.0, 1.0)),
#sometimes(iaa.ElasticTransformation(alpha=(0.5, 3.5), sigma=0.25)), # move pixels locally around (with random strengths)
#sometimes(iaa.PiecewiseAffine(scale=(0.01, 0.05))) # sometimes move parts of the image around
],
random_order=True
)
],
random_order=True
)
def normalize(image):
image = image[..., ::-1]
image = image.astype('float')
image[..., 0] -= 103.939
image[..., 1] -= 116.779
image[..., 2] -= 123.68
return image
def single_img_process(img_path ,resize = (448, 448)):
img = np.array(Image.open(img_path))
img = cv2.resize(img, resize)
img = aug_pipe.augment_image(img)
img = normalize(img)
return img
def pic_loader(test_pic_path = r"C:\tempCodingUsage\python\kangaroo-master\test",
batch_size = 1):
batch_list = []
while True:
path_list = list(glob.glob(test_pic_path + "\\*"))
path_list = random.sample(path_list, len(path_list))
for pic_path in path_list:
aug_img = single_img_process(pic_path)
batch_list.append(aug_img)
if len(batch_list) == batch_size:
yield np.array(batch_list).astype(np.float32)
batch_list = []
if __name__ == "__main__":
pass
结果记录函数:
import os
import numpy as np
gt_path = r"C:\tempCodingUsage\python\study_yolo\YOLOStudy\ground_truth"
det_path = r"C:\tempCodingUsage\python\study_yolo\YOLOStudy\detection"
def write_conclusion_to_file(file_name, input_construct, input_type = "gt"):
# input_construct [? ,4 or 5]
assert input_type in ["gt", "det"]
input_construct = np.array(input_construct)
if input_type == "gt":
input_construct = input_construct[:, :4]
else:
input_construct = input_construct[:, :5]
if type(input_construct) != type([]):
input_construct = input_construct.tolist()
all_lines = "\n".join(map(lambda x: "object {}".format(" ".join(map(str ,x))), input_construct))
if input_type == "gt":
path = r"{}".format(gt_path) + "\\" + file_name
else:
path = r"{}".format(det_path) + "\\" + file_name
with open(path, "w", encoding="utf-8") as f:
f.write(all_lines)
IOU计算函数:
def tf_xyhw_iou_func(truth_t4, pred_t4):
x1_x, x1_y, x1_h, x1_w = truth_t4[0], truth_t4[1], truth_t4[2], truth_t4[3]
x2_x, x2_y, x2_h, x2_w = pred_t4[0], pred_t4[1], pred_t4[2], pred_t4[3]
x1_t, x2_t, y1_t, y2_t = x1_x - x1_w / 2., x1_x + x1_w / 2., x1_y - x1_h / 2., x1_y + x1_h / 2.
x1_p, x2_p, y1_p, y2_p = x2_x - x2_w / 2., x2_x + x2_w / 2., x2_y - x2_h / 2., x2_y + x2_h / 2.
intersection = tf.cond(tf.logical_not(tf.logical_or(x2_t < x1_p, y2_t < y1_p)), true_fn=lambda : tf.cond(tf.logical_not (tf.logical_or(x2_p < x1_t, y2_p < y1_t)),
true_fn=lambda :(tf.reduce_min([x2_t, x2_p]) -
tf.reduce_max([x1_t, x1_p])) * (tf.reduce_min([y2_t, y2_p]) - tf.reduce_max([y1_t, y1_p])),
false_fn=lambda : tf.constant(0.0)
), false_fn=lambda : tf.constant(0.0))
union = (x2_t - x1_t) * (y2_t - y1_t) + (x2_p - x1_p) * (y2_p - y1_p) - intersection
iou = intersection / union
return iou
网络结构如下:(encode_construct_full为YOLO对应编码结构,仅仅给出并未使用)
import tensorflow as tf
from util import tf_xyhw_iou_func
def conv2d(inputs, filters, kernel_size, strides,
name = None, is_training = tf.constant(True)):
assert name is not None
req = tf.layers.conv2d(inputs, filters, kernel_size, strides,
padding="SAME", name=name,
kernel_initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.0001
))
req = tf.layers.batch_normalization(req, training = is_training,
name="{}_norm".format(name))
req = tf.nn.leaky_relu(req)
return req
def max_pool(inputs, pool_size=(2, 2), strides = 2,
name = None):
assert name is not None
req = tf.layers.max_pooling2d(inputs, pool_size, strides,
padding="SAME", name = name)
return req
class FAST_YOLO(object):
def __init__(self, S = 7, B = 2, C = 20, height = 448,
width = 448,
box_buffer_size = 10,
batch_size = 3,
lambda_coord = 5.0,
lambda_noobj = 0.5):
'''
:param S:
:param B:
:param C:
predict encoder into [batch, S, S, (B * 5 + C)]
B construct by [x, y, w, h, p]
'''
self.S = S
self.B = B
self.C = C
# box_biffer_size indicate the max num of possible box
self.box_buffer_size = box_buffer_size
self.batch_size = batch_size
self.lambda_coord = lambda_coord
self.lambda_noobj = lambda_noobj
self.is_training = tf.placeholder(tf.bool, [])
self.img_input = tf.placeholder(tf.float32, [None, height, width, 3])
self.true_box_input = tf.placeholder(tf.float32, [None, box_buffer_size, 4])
self.true_box_buffer_mask = tf.placeholder(tf.int32, [None])
self.anchor_input = tf.placeholder(tf.float32, [7, 7, self.B, 2])
self.model_construct()
def model_construct(self):
self.img_encoded = self.encode_construct()
self.decode_construct(self.img_encoded, self.true_box_input)
self.train_op = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(self.total_loss)
def encode_construct_full(self):
conv_1_output = conv2d(self.img_input, 64, 7, 2, name="conv_1", is_training=self.is_training)
norm_1_output = max_pool(conv_1_output, name="norm_1")
conv_2_output = conv2d(norm_1_output, 192, 3, 1, name="conv_2", is_training=self.is_training)
norm_2_output = max_pool(conv_2_output, name="norm_2")
conv_3_output = conv2d(norm_2_output, 128, 1, 1, name="conv_3", is_training=self.is_training)
conv_4_output = conv2d(conv_3_output, 256, 3, 1, name="conv_4", is_training=self.is_training)
conv_5_output = conv2d(conv_4_output, 256, 1, 1, name="conv_5", is_training=self.is_training)
conv_6_output = conv2d(conv_5_output, 512, 3, 1, name="conv_6", is_training=self.is_training)
norm_3_output = max_pool(conv_6_output, name="norm_3")
conv_7_output = conv2d(norm_3_output, 256, 1, 1, name="conv_7", is_training=self.is_training)
conv_8_output = conv2d(conv_7_output, 512, 3, 1, name="conv_8", is_training=self.is_training)
conv_9_output = conv2d(conv_8_output, 256, 1, 1, name="conv_9", is_training=self.is_training)
conv_10_output = conv2d(conv_9_output, 512, 3, 1, name="conv_10", is_training=self.is_training)
conv_11_output = conv2d(conv_10_output, 256, 1, 1, name="conv_11", is_training=self.is_training)
conv_12_output = conv2d(conv_11_output, 512, 3, 1, name="conv_12", is_training=self.is_training)
conv_13_output = conv2d(conv_12_output, 256, 1, 1, name="conv_13", is_training=self.is_training)
conv_14_output = conv2d(conv_13_output, 512, 3, 1, name="conv_14", is_training=self.is_training)
conv_15_output = conv2d(conv_14_output, 512, 1, 1, name="conv_15", is_training=self.is_training)
conv_16_output = conv2d(conv_15_output, 1024, 3, 1, name="conv_16", is_training=self.is_training)
norm_4_output = max_pool(conv_16_output, name="norm_4")
conv_17_output = conv2d(norm_4_output, 512, 1, 1, name="conv_17", is_training=self.is_training)
conv_18_output = conv2d(conv_17_output, 1024, 3, 1, name="conv_18", is_training=self.is_training)
conv_19_output = conv2d(conv_18_output, 512, 1, 1, name="conv_19", is_training=self.is_training)
conv_20_output = conv2d(conv_19_output, 1024, 3, 1, name="conv_20", is_training=self.is_training)
conv_21_output = conv2d(conv_20_output, 1024, 3, 1, name="conv_21", is_training=self.is_training)
conv_22_output = conv2d(conv_21_output, 1024, 3, 2, name="conv_22", is_training=self.is_training)
conv_23_output = conv2d(conv_22_output, 1024, 3, 1, name="conv_23", is_training=self.is_training)
conv_24_output = conv2d(conv_23_output, 1024, 3, 1, name="conv_24", is_training=self.is_training)
conv_flatten = tf.reshape(conv_24_output, [-1, 7 * 7 * 1024])
flatten_layer = tf.layers.dense(conv_flatten, units=4096, name="flatten_mapper")
reconstruct_layer = tf.layers.dense(flatten_layer, units=7*7*30, name="reconstruct_mapper")
reconstruct_nn = tf.reshape(reconstruct_layer, [-1, 7, 7, 30])
return reconstruct_nn
def encode_construct(self):
conv_1_output = conv2d(self.img_input, 64, 7, 2, name="conv_1", is_training=self.is_training)
norm_1_output = max_pool(conv_1_output, name="norm_1")
conv_2_output = conv2d(norm_1_output, 192, 3, 1, name="conv_2", is_training=self.is_training)
norm_2_output = max_pool(conv_2_output, name="norm_2")
conv_6_output = conv2d(norm_2_output, 512, 3, 1, name="conv_6", is_training=self.is_training)
norm_3_output = max_pool(conv_6_output, name="norm_3")
conv_7_output = conv2d(norm_3_output, 256, 1, 1, name="conv_7", is_training=self.is_training)
conv_8_output = conv2d(conv_7_output, 512, 3, 1, name="conv_8", is_training=self.is_training)
conv_16_output = conv2d(conv_8_output, 1024, 3, 1, name="conv_16", is_training=self.is_training)
norm_4_output = max_pool(conv_16_output, name="norm_4")
conv_22_output = conv2d(norm_4_output, 1024, 3, 2, name="conv_22", is_training=self.is_training)
conv_23_output = conv2d(conv_22_output, 1024, 3, 1, name="conv_23", is_training=self.is_training)
conv_24_output = conv2d(conv_23_output, 1024, 3, 1, name="conv_24", is_training=self.is_training)
conv_flatten = tf.reshape(conv_24_output, [-1, 7 * 7 * 1024])
# add sigmoid activation for numerical stable.
flatten_layer = tf.layers.dense(conv_flatten, units=4096, name="flatten_mapper",
activation=tf.nn.sigmoid)
reconstruct_layer = tf.layers.dense(flatten_layer, units=7*7*30, name="reconstruct_mapper")
reconstruct_nn = tf.reshape(reconstruct_layer, [-1, 7, 7, 30])
return reconstruct_nn
def calculate_iou(self, pred_box, true_box):
pred_part = tf.reshape(pred_box[...,:4], [7 * 7 * self.B, -1])
x_y_part = pred_part[...,:2]
# [7, 1, 1]
x_corr = tf.expand_dims(tf.expand_dims(tf.range(7), -1), -1)
x_corr = tf.expand_dims(tf.tile(x_corr, [1, 7, self.B]), -1)
y_corr = tf.expand_dims(tf.expand_dims(tf.range(7), -1), -1)
y_corr = tf.expand_dims(tf.tile(tf.transpose(y_corr, [1, 0, 2]), [7, 1, self.B]), -1)
x_y_corr = tf.cast(tf.concat([tf.reshape(x_corr, [7 * 7 * self.B,1]), tf.reshape(y_corr, [7*7*self.B,1])], -1), dtype=tf.float32)
x_y_part = tf.nn.sigmoid(x_y_part) + x_y_corr
h_w_part = tf.exp(pred_part[..., 2:4]) * tf.reshape(self.anchor_input, [7 * 7 * self.B, 2])
used_pred_part = tf.concat([x_y_part, h_w_part], axis=-1)
def calculate_iou_inner(array_4):
req = []
for pred_idx in range(7*7*self.B):
pred_req = used_pred_part[pred_idx]
temp_val = tf_xyhw_iou_func(array_4, pred_req)
req.append(temp_val)
return tf.stack(req, -1)
conclusion = tf.map_fn(calculate_iou_inner, true_box)
# [7*7*self.B]
req_flatten_val_t = tf.reduce_max(conclusion, 0)
# iou_array [7, 7, self.B]
iou_t = tf.reshape(req_flatten_val_t, [7, 7, self.B])
max_conclusion = tf.reduce_max(conclusion, axis=-1)
def max_index_findding(input):
# input [7 * 7 * self.B + 1] 1: indicate max_val
head = tf.reshape(input[:7 * 7 * self.B], [7, 7, self.B])
val = input[-1]
max_index_array = tf.equal(tf.cast(head, tf.float32) ,tf.cast(tf.fill([7, 7, self.B], val), tf.float32))
max_index_array = tf.cast(max_index_array, tf.int32)
first = tf.argmax(tf.reduce_sum(tf.reduce_sum(max_index_array, -1), -1))
second = tf.argmax(tf.reduce_sum(tf.reduce_sum(max_index_array, 0), -1))
third = tf.argmax(tf.reduce_sum(tf.reduce_sum(max_index_array, 0), 0))
return tf.cast(tf.stack([first, second, third], axis=-1), tf.int32)
indice_construct = tf.map_fn(max_index_findding, tf.concat([conclusion, tf.expand_dims(max_conclusion, -1)], axis=-1),
dtype=tf.int32)
# [buffer_num, 7 * 7 * self.B]
first, second, third = indice_construct[:, 0], indice_construct[:, 1], indice_construct[:, 2]
return first, second, third, iou_t
def index_element(self, single_box_part_cat_c, first, second, third,
single_true_box_input, iou_t):
# single_box_part_cat_c [7, 7, (self.B * 5) + class_prob_dim]
# single_box_part [7, 7, self.B, 5]
# single_true_box_input [buffer_num, 4]
# first, second, third, [buffer_num]
# iou_t [7, 7, 2]
single_box_part = tf.reshape(single_box_part_cat_c[...,self.C:], [7, 7, self.B, 5])
x_y_part = single_box_part[...,:2]
# [7, 1, 1]
x_corr = tf.expand_dims(tf.expand_dims(tf.range(7), -1), -1)
x_corr = tf.expand_dims(tf.tile(x_corr, [1, 7, self.B]), -1)
y_corr = tf.expand_dims(tf.expand_dims(tf.range(7), -1), -1)
y_corr = tf.expand_dims(tf.tile(tf.transpose(y_corr, [1, 0, 2]), [7, 1, self.B]), -1)
x_y_corr = tf.cast(tf.concat([x_corr, y_corr], -1), dtype=tf.float32)
x_y_part = tf.nn.sigmoid(x_y_part) + x_y_corr
h_w_part = tf.exp(single_box_part[...,2:4]) * self.anchor_input
single_box_part = tf.concat([x_y_part, h_w_part, tf.expand_dims(tf.nn.sigmoid(single_box_part[...,-1]), -1)], axis=-1)
fst = tf.stack([first, second, third], axis=-1)
t5 = tf.gather_nd(single_box_part, fst)
# used to construct ground truth
self.t5 = t5
iou_t_gathered = tf.gather_nd(iou_t, fst)
self.iou_t_gathered = iou_t_gathered
c_gathered = tf.gather_nd(tf.nn.sigmoid(single_box_part_cat_c[...,:self.C]), fst)
single_true_box_input_cat_t5 = tf.concat([single_true_box_input, t5, tf.expand_dims(iou_t_gathered, -1), tf.expand_dims(c_gathered, -1)], axis=-1)
false_c_list = []
for f_idx in range(7):
for s_idx in range(7):
for t_idx in range(2):
p_hat = single_box_part[f_idx][s_idx][t_idx][4]
iou_truth_pred = iou_t[f_idx][s_idx][t_idx]
p_object_iou_truth_pred = p_hat * iou_truth_pred
p_object_iou_truth_pred_ll = tf.zeros_like(p_hat) * iou_truth_pred
false_c_list.append(tf.nn.l2_loss(p_object_iou_truth_pred - p_object_iou_truth_pred_ll))
false_scalar = tf.reduce_sum(tf.convert_to_tensor(false_c_list))
def calculate_inner(input):
x, y, w, h, x_hat, y_hat, w_hat, h_hat, p_hat, iou_truth_pred, c_class_prob_distribution = input[0], input[1], input[2], input[3], input[4], input[5], input[6], input[7],input[8], \
input[9], input[10:]
# [1]
p_object_iou_truth_pred = p_hat * iou_truth_pred
p_object_iou_truth_pred_l = tf.ones_like(p_hat, dtype=tf.float32) * iou_truth_pred
p_object_iou_truth_pred_ll = tf.zeros_like(p_hat, dtype=tf.float32) * iou_truth_pred
# [self.C]
p_class_dist_iou_truth_pred = c_class_prob_distribution * iou_truth_pred
p_class_dist_iou_truth_pred_l = tf.ones_like(c_class_prob_distribution, dtype=tf.float32) * iou_truth_pred
return tf.stack([tf.nn.l2_loss(x - x_hat),
tf.nn.l2_loss(y - y_hat),
tf.nn.l2_loss(h ** 0.5 - h_hat ** 0.5), tf.nn.l2_loss(w ** 0.5 - w_hat ** 0.5),
tf.nn.l2_loss(p_object_iou_truth_pred - p_object_iou_truth_pred_l), tf.nn.l2_loss(p_class_dist_iou_truth_pred - p_class_dist_iou_truth_pred_l),
-1 * tf.nn.l2_loss(p_object_iou_truth_pred - p_object_iou_truth_pred_ll + false_scalar)], -1)
# [buffer_num, 7]
xyhwcpf = tf.map_fn(calculate_inner, single_true_box_input_cat_t5)
return xyhwcpf
def decode_construct(self, img_encoded, true_box_input):
# true_box_input : [batch, box_buffer_size, 4] 4:[x1, x2, y1, y2]
# in the procedure rescale w h and add corrdinate to [x, y, w, h] part
# 30 = self.C + self.B * 5 construct in order 5: [x1, x2, y1, y2, p]
# [batch, 7, 7, 2, 5]
box_part = tf.reshape(img_encoded[...,self.C:], [-1, 7, 7, self.B, 5])
box_part_cat_c = img_encoded
x_loss_list, y_loss_list, h_loss_list, w_loss_list, c_loss_list, p_loss_list, false_c_loss_list = [], [], [], [], [], [], []
for batch_idx in range(self.batch_size):
single_box_part = box_part[batch_idx]
single_true_box_input = true_box_input[batch_idx][:self.true_box_buffer_mask[batch_idx]]
first, second, third, iou_t = self.calculate_iou(single_box_part, single_true_box_input)
single_box_part_cat_c = box_part_cat_c[batch_idx]
tensor_7 = self.index_element(single_box_part_cat_c, first, second, third,
single_true_box_input, iou_t)
x_loss, y_loss, h_loss, w_loss, c_loss, p_loss, false_c_loss = tensor_7[:,0], tensor_7[:,1], tensor_7[:,2], tensor_7[:, 3], \
tensor_7[:, 4], tensor_7[:, 5], tensor_7[:, 6]
x_loss_list.append(tf.reduce_sum(x_loss))
y_loss_list.append(tf.reduce_sum(y_loss))
h_loss_list.append(tf.reduce_sum(h_loss))
w_loss_list.append(tf.reduce_sum(w_loss))
c_loss_list.append(tf.reduce_sum(c_loss))
p_loss_list.append(tf.reduce_sum(p_loss))
false_c_loss_list.append(tf.reduce_sum(false_c_loss))
self.x_loss_list = x_loss_list
self.y_loss_list = y_loss_list
self.h_loss_list = h_loss_list
self.w_loss_list = w_loss_list
self.c_loss_list = c_loss_list
self.p_loss_list = p_loss_list
self.false_c_loss_list = false_c_loss_list
x_loss = tf.reduce_sum(x_loss_list)
y_loss = tf.reduce_sum(y_loss_list)
h_loss = tf.reduce_sum(h_loss_list)
w_loss = tf.reduce_sum(w_loss_list)
c_loss = tf.reduce_sum(c_loss_list)
p_loss = tf.reduce_sum(p_loss_list)
false_c_loss = tf.reduce_sum(false_c_loss_list)
self.total_loss = self.lambda_coord * (x_loss + y_loss + h_loss + w_loss) + c_loss + self.lambda_noobj * false_c_loss + p_loss
@staticmethod
def update_model(sess ,model ,feed_dict):
_, total_loss = sess.run([model.train_op, model.total_loss,
],
feed_dict = feed_dict)
@staticmethod
def train():
import cv2
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
import uuid
import os
from data_generator.test_pic_preprocess import pic_loader
from valid_conclusion import write_conclusion_to_file
font_path = r"C:\Windows\WinSxS\amd64_microsoft-windows-font-truetype-simsunb_31bf3856ad364e35_10.0.17134.1_none_767b164d851a3a00\simsunb.ttf"
font = ImageFont.truetype(font_path, 20)
import numpy as np
from preprocessing import train_ex_generator, ANCHORS
batch_size = 1
box_buffer_size = 3
train_gen = train_ex_generator(batch_size = batch_size,
box_buffer_size=box_buffer_size)
test_gen = pic_loader(batch_size = 1)
yolo_model = FAST_YOLO(batch_size=batch_size,
box_buffer_size= box_buffer_size)
saver = tf.train.Saver()
with tf.Session() as sess:
if os.path.exists(r"C:\tempCodingUsage\python\study_yolo\YOLOStudy\model_ss.index"):
saver.restore(sess, save_path=r"C:\tempCodingUsage\python\study_yolo\YOLOStudy\model_ss")
print("model restore end !")
else:
sess.run(tf.global_variables_initializer())
print("model init end !")
epoch = 0
step = 0
save_every_step = 100
log_every_step = 10
save_weight = True
while True:
train_sample = train_gen.__next__()
if train_sample is None:
epoch += 1
continue
img_input, true_box_input = train_sample
true_box_buffer_mask = np.min(np.concatenate((np.sum((np.sum(true_box_input, axis=-1) > 0).astype(np.int32), -1).astype(np.int32)[:, np.newaxis], np.array([box_buffer_size] * batch_size)[:, np.newaxis]), axis=-1),
axis= -1)
anchor_input = np.array([[ANCHORS] * 7] * 7).reshape([7, 7, 2, 2])
if step % save_every_step == 0:
print("train valid pic save")
t5, iou_t_gathered = sess.run(
[yolo_model.t5, yolo_model.iou_t_gathered], feed_dict={
yolo_model.img_input: img_input,
yolo_model.true_box_input: true_box_input,
yolo_model.true_box_buffer_mask: true_box_buffer_mask,
yolo_model.anchor_input: anchor_input,
yolo_model.is_training: False,
})
x, y, w, h = t5[0][:4]
x, y, w, h = np.array([x * 2, y * 2, w, h]) * (448. / 7.)
x1, x2, y1, y2 = map(int ,np.array([(x - w) / 2 , (x + w) / 2., (y - h) / 2., (y + h) / 2.]))
img_sample = img_input[0]
MAX, MIN = np.max(img_sample), np.min(img_sample)
img_sample = ((img_sample - MIN) / (MAX - MIN) * 255).astype(np.uint8)
img_sample = cv2.cvtColor(img_sample, cv2.COLOR_BGR2LAB)
# predict rect
cv2.rectangle(img_sample, (x1, y1), (y2, y2), color=(255, 255, 0), thickness = 1)
########################## save pic annotations and ground truth
write_conclusion_to_file("{}.txt".format(step), [[t5[0][-1] ,x1, y2, x2, y1]], input_type="det")
true_box_buffer_mask = np.min(np.concatenate((np.sum((np.sum(true_box_input, axis=-1) > 0).astype(np.int32), -1).astype(np.int32)[:, np.newaxis], np.array([box_buffer_size] * batch_size)[:, np.newaxis]), axis=-1),
axis= -1)
buffer_num = true_box_buffer_mask[0]
need_list = []
for i in range(buffer_num):
x, y, w, h = true_box_input[0][i]
x, y, w, h = np.array([x * 2, y * 2, w, h]) * (448. / 7.)
x1, x2, y1, y2 = map(int ,np.array([(x - w) / 2 , (x + w) / 2., (y - h) / 2., (y + h) / 2.]))
# ground truth rect
cv2.rectangle(img_sample, (x1, y1), (y2, y2), color=(0, 255, 0), thickness = 1)
need_list.append([x1, y2, x2, y1])
img = Image.fromarray(img_sample.astype(np.uint8))
draw = ImageDraw.Draw(img)
draw.text((0, 20),"{}".format(iou_t_gathered[0]),(255, 255, 0), font=font)
img.save(r"C:\tempCodingUsage\python\study_yolo\yolo_conclusion\{}.jpg".format(str(uuid.uuid1())))
write_conclusion_to_file("{}.txt".format(step), need_list, input_type="gt")
test_sample = test_gen.__next__()
t5 = sess.run(
yolo_model.t5, feed_dict={
yolo_model.img_input: test_sample,
yolo_model.true_box_input: true_box_input,
yolo_model.true_box_buffer_mask: true_box_buffer_mask,
yolo_model.anchor_input: anchor_input,
yolo_model.is_training: False,
})
x, y, w, h = t5[0][:4]
x, y, w, h = np.array([x * 2, y * 2, w, h]) * (448. / 7.)
x1, x2, y1, y2 = map(int ,np.array([(x - w) / 2 , (x + w) / 2., (y - h) / 2., (y + h) / 2.]))
img_sample = test_sample[0]
MAX, MIN = np.max(img_sample), np.min(img_sample)
img_sample = ((img_sample - MIN) / (MAX - MIN) * 255).astype(np.uint8)
img_sample = cv2.cvtColor(img_sample, cv2.COLOR_BGR2LAB)
cv2.rectangle(img_sample, (x1, y1), (y2, y2), color=(255, 255, 0), thickness=1)
img = Image.fromarray(img_sample.astype(np.uint8))
img.save(r"C:\tempCodingUsage\python\study_yolo\test_conclusion\{}.jpg".format(str(uuid.uuid1())))
if save_weight:
saver.save(sess, save_path=r"C:\tempCodingUsage\python\study_yolo\YOLOStudy\model_ss")
_ ,total_loss, \
x_loss_list,y_loss_list, h_loss_list, w_loss_list,c_loss_list,p_loss_list,false_c_loss_list, \
\
= sess.run([yolo_model.train_op, \
\
yolo_model.total_loss,
yolo_model.x_loss_list,
yolo_model.y_loss_list,
yolo_model.h_loss_list,
yolo_model.w_loss_list,
yolo_model.c_loss_list,
yolo_model.p_loss_list,
yolo_model.false_c_loss_list,
], feed_dict={
yolo_model.img_input: img_input,
yolo_model.true_box_input: true_box_input,
yolo_model.true_box_buffer_mask: true_box_buffer_mask,
yolo_model.anchor_input: anchor_input,
yolo_model.is_training: True,
})
if step % log_every_step == 0:
print("epoch :{}, step :{}, total_loss :{}".format(epoch, step ,total_loss))
print("*" * 100)
step += 1
if __name__ == "__main__":
FAST_YOLO.train()
训练会生成效果图,黄色的框对应最大置信度的估计边框,绿色的框对应ground truth边框,训练集给出黄色的IOU值。下面先给出训练集的生成图示:




一般单个的识别效果好于多个,样本量有限。
下面给出测试集效果图:



这里在图片保存前用了cv2.COLOR_BGR2LAB做特征变换(可以看作与Sobel算子保留边界“正交”),使得输出上更多地突出色彩的区别,这种将LAB 空间某种程度上可以看成RGB空间的“极坐标表示”,亮度为一个维度,而将色彩降为“二维”(相当于在纹理特征上“降维”),较多保留了不同物体的区别信息,能更好的显示目标识别的结果。可以从结果上看到于语义分割的近似程度,所以有一些非监督语义分割算法就是变换到LAB空间后进行聚类。