目标检测是一个直到最近才开始逐渐被征服的挑战。解决这个问题对于自动化和自动驾驶来说是至关重要的。对解决办法的追求导致了各种方法的发展。我想要描述一些主要的方法,在过去的21目标检测已经被使用,然后讨论 Yolov3的实现。
讨论方法
引言
虽然深度学习通常被归类为机器学习的一个分支,但是两者之间应该有明确的区别。机器学习是指在前深度学习时代发展起来的算法和方法。前深度学习时代通常被称为2011/2012年之前的时期。这些算法和方法是当时计算能力所允许的最大值。图形处理器的出现和 AlexNet 与大数据相结合的发展,使得经典的机器学习算法变得无效,使得深度学习占据主导地位。这就是为什么许多机器学习算法很少被使用的原因。它们的确有助于提供不同的方法来理解问题和进行比较的基线算法。
经典的机器学习方法
三个经典的机器学习算法是 Viola-Jones 检测框架、尺度不变特征转换分类(SIFT)和方向梯度直方图分类(HOG)。Viola-Jones 是一种非常流行和公认的用于面部检测的算法。该算法是基于 Haar 特征的高效算法,各种各样的实现都可以从网上快速获得。SIFT 是一个有趣的算法,它试图描述图像中的局部特征。这种算法在21世纪初非常流行。最快和最流行的迭代是SURF实现。HOG 是一个更复杂的算法,它试图计算图像局部区域中梯度方向的出现次数。这个算法的一个新的高级版本最近作为机器人学中的深度学习算法的验证卷土重来。
深度学习方法
三种经典的深度学习算法是 Region proposal (R-CNN)、 Single Shot Multibox Detector (SSD)、 You Only Look Once (YOLO)和 Single Shot refining Neural Network for Detection (RefineDet)。
R-CNN
该 R-CNN 算法选择了一些区域(最初是2000个) ,然后使用卷积神经网络网络(CNN)分别提取每个区域的特征。

然后,该算法继续在测试图像中搜索这些区域的混合。这种算法有时被称为双镜头算法,因为它用一个镜头生成区域建议,另一个镜头检测每个建议的对象。这个算法已经发展成为更快更简单的实现,我将在以后的文章中讨论。
SSD
SSD 是一个有趣的算法,但在社区中没有得到太多的关注。这个网络背后的主要思想是,CNN 逐渐缩小特征地图的大小,并增加深度,因为它移动到更深的层次。
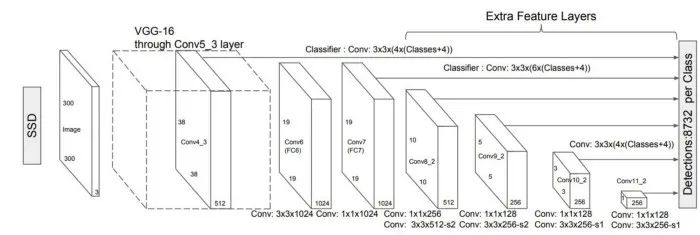
深层覆盖大的感受野,构建更抽象的表征,浅层覆盖小的感受野。根据这个逻辑,我们可以简单地说,浅层预测小物体,深层预测大物体。这个简单的逻辑意味着我们只需要一个镜头来检测图像中的多个物体,而 R-CNN 方法需要两个镜头。显然,这是非常有益的。
YOLO
在我看来,YOLO 算法确实是一个革命性的算法,因为它考虑到了整个图像,因此充分利用了 CNN 的能力。该算法利用单卷积网络预测 bounding boxes 和 bounding boxes 的类别概率。
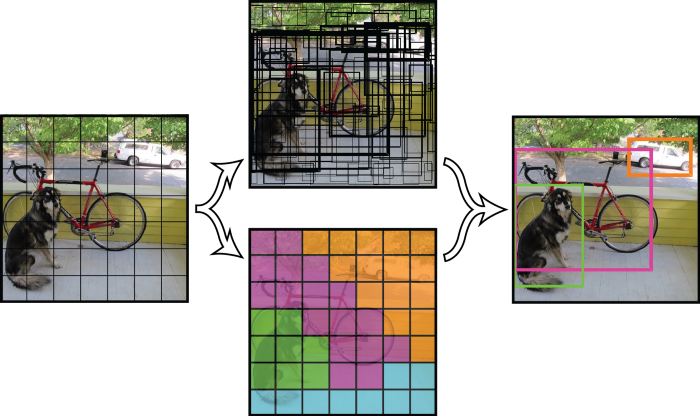
选择分类概率大于阈值的 bounding boxes,并用于定位图像中的对象。最初提出的算法是 Darknet,但是自从它被使用以来,各种不同的算法被提出。
RefineDet
Single-Shot Refinement 神经网络是一种尝试将 R-CNN 和 SSD 方法结合起来的新型目标检测。
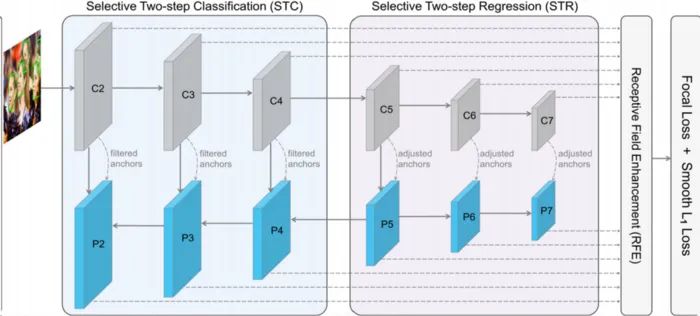
该网络由两个相互连接的模块组成:anchor refinement 和 object detection 模块。作者公开了这个模型的代码,我将在接下来的几周内发布这个代码的一个简单实现。
YOLO 实现
环境配置
为了完成我的 YOLOv3实现,你需要一个适当的计算环境。首先,您需要在 shell 模式下运行 conda 虚拟环境。我建议您使用一个新的干净的 conda 环境,您可以手动安装必要的库。所需的主要库包括:
OpenCV
Numpy
PyTorch
CUDA
可能有1-2个未列出的次要库。在谷歌上快速搜索一下,你就会找到 一些安装命令来安装它们。
CUDA is a hardware accelerator that any modern computer should be able to utilize. I do not recommend the installation of the CUDA ToolKit manually. Instead, I recommend that you proceed to install it through Consta forge simultaneously with PyTorch to avoid problems.
CUDA 是一个硬件加速器,任何现代计算机都应该能够利用。我不建议手动安装 CUDA 工具包。相反,我建议您通过以下网址: https://pytorch.org/get-started/locally/提供的安装方式进行安装,以避免出现问题。
在本节中,我假设您熟悉 conda 虚拟环境。
下载代码
在建立了虚拟环境之后,下一步是到我的 GitHub 下载代码。链接到我的 GitHub 的链接是:https://github.com/FranciscoReveriano/YOLOV3-Tutorial
您可以通过命令行直接下载它,也可以下载 zip 文件。当然,如果下载,记得解压缩(解压缩)文件夹。
该代码必须通过 Anaconda 命令行运行。请确保将代码放入可以通过命令行轻松访问的目录中。
下载预训练模型
下一步是确保你有预先训练好的模型。这个 Yolov3模型使用 COCO 训练的 DarkNet 模型。因此,这意味着必须在这里下载:
https://pjreddie.com/media/files/yolov3.weights
下载完成之后,你需要将它们移动到你从我的 GitHub 下载的主目录/文件夹中。此时,您的目录文件夹应该如下所示。
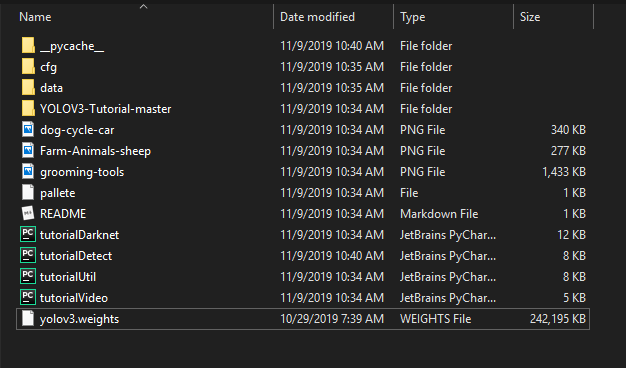
运行代码
现在,我假设您能够下载代码并将其保存在目录中。我还假设您的 conda 环境已经设置好,并且所有必需的库都已下载。
您应该继续激活 conda 环境,并前往代码所在的目录。我们将首先尝试测试经典的测试图像(dog-cycle-car.png)。你需要在命令行中输入以下命令:
python tutorialDetect.py — images dog-cycle-car.png — det det如果一切都已成功设置,并且您的环境具有所有必要的库。你应该可以在命令提示符上看到下面的命令:

更重要的是,如果转到主文件夹中的子目录 /det,您将看到一个新界面。
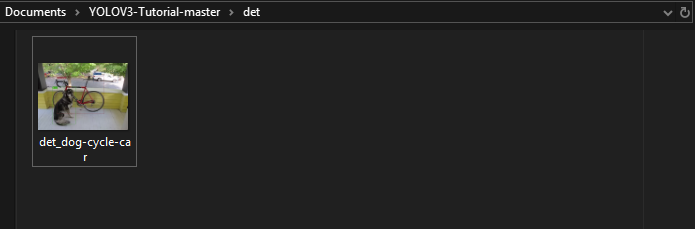
如果你点击图片,你会看到 YOLOVv3能够成功地检测和分类所有三个对象。

你可以继续上传任何你想要的图片,然后让 YOLOv3对它们进行分类。这个实现非常健壮,对于大多数分类应该没有什么问题。
YOLOv3 视频实现
现在的图像是伟大的,但让我们诚实地说,我们的数字媒体越来越多的视频格式。幸运的是,YOLOv3可以很容易地被用来检测视频中的对象。请注意,这是一项非常繁重的计算任务,需要一台带有图形/视频卡的计算机。
理论上,你可以用任何你想要的视频来测试这一点。只要确保你有 .avi 格式的视频就行了。为了测试我个人建议你下载以下视频:
https://www.robots.ox.ac.uk/ActiveVision/Research/Projects/2009bbenfold_headpose/Datasets/TownCentreXVID.avi
下载视频后,请将其移动到 YOLOv3主目录。您的目录应该如下所示:
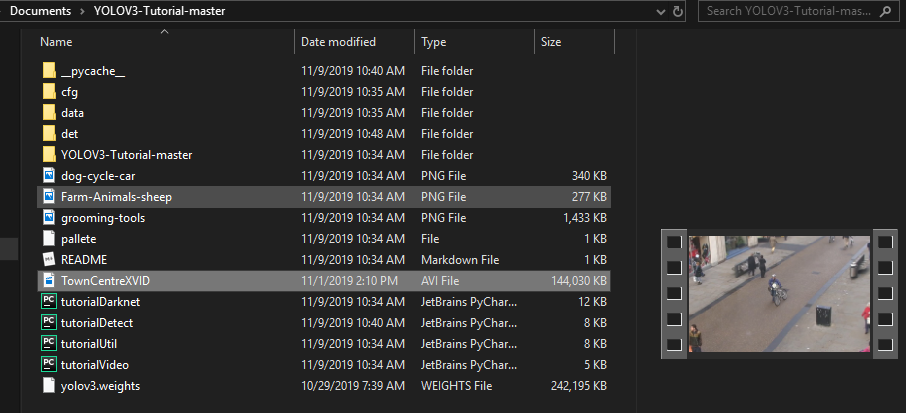
运行视频的命令类似于 image 命令。我提供的实现非常简单,并且易于使用。运行视频的命令是:
python tutorialVideo.py — video TownCentreXVID.avi运行这个命令应该会打开一个显示视频的窗口。在视频中,您将看到 YOLOv3正在积极地检测和绘制 bounding box。

这是一个结果截屏。
总结
现在,您的计算机上应该有一个正常工作的 YOLOv3模型。您可以继续将此模型合并到进一步的项目中。或者只是继续玩它,并用它来检测对象。
· END ·
HAPPY LIFE
