经过一个多星期的学习,对python3的语法有了一定了解,马上动手做了一个爬虫,检验学习效果
目标
- 爬取豆瓣电影top250中每一部电影的名称、排名、链接、名言、评分
准备工作
- 运行平台:windows10
- IDE:PyCharm
- requests、BeautifulSoup库(使用pip进行安装)
第一步:向服务器发送请求,获得响应
由于豆瓣电影top250上信息均在html源码中,故需获取其源码,使用requests库。代码如下:
import requests
def get_html(url):
response = requests.get(url) # 发送get请求
if response.status_code == 200: # 如果服务器响应成功,返回网页源代码
return response.text
else:
print("访问失败")
第二步:对源码进行解析,提取
-
单页分析
- 首先分析原网页代码:
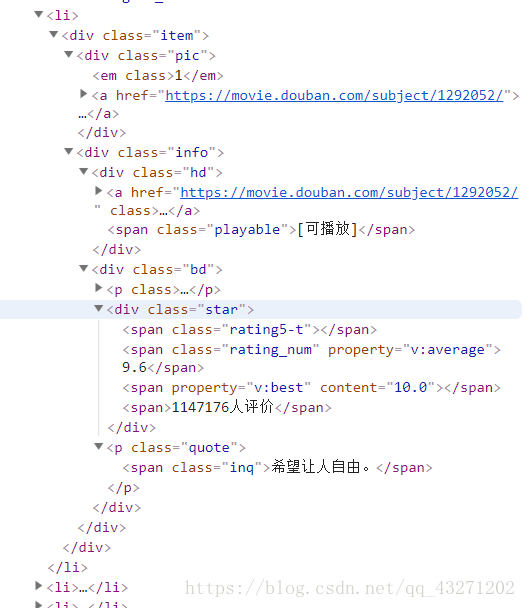
发现我们所需要的信息都在 li 标签中,所以我们需要定位在li标签中提取信息
但是,我们又发现:在真正含有我们所需要的信息的li 标签前,还有19个不含我们所需信息的li标签:
所以,在提取信息的时候需要将前19个 li 标签排除在外
再对含有我们所需内容的 li 标签进行分析:
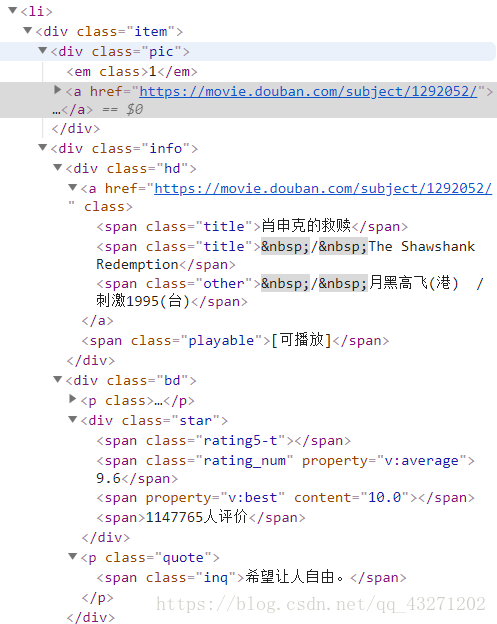
可以看到:影片名为<span class="title"标签的文本内容;排名为<em的文本内容;链接是<a 标签中href属性对应的值;名言为标签<span class=“inq” 的文本内容;评分为<span class=“rating_num” property=“v:average” 的文本内容;
利用这些信息就可以利用find()函数定位信息,进行提取
代码如下:
from bs4 import BeautifulSoup def parse_html(html): soup = BeautifulSoup(html, 'lxml') # 创建BeautifulSoup对象,使用lxml解析库 items = soup.find_all(name='li') # 查询名称为li的元素,以列表形式输出 for item in items[19:]: # 注意这里的[19:],对网页源码分析后发现前19个li标签中并没有我们需要的数据,所以将其排除在外 yield { # 利用find()函数定位我们需要的数据,并作为生成器元素 'title': item.span.get_text(), # 影片名 'index': item.find(name='em').text, # 影片排名 'image': item.find(name='a')['href'], # 影片链接 'quote': item.find(class_="inq").text, # 影片名言 'score': item.find(class_="rating_num").text # 影片评分 } # 构造生成器,作为函数的返回结果 # 获取Tag对象的文本信息有三种方法,.string、.text、.get_text()以上完成了对豆瓣电影一页源代码的解析,接下来进行多页的解析,将250部电影的信息全部爬取下来:
- 首先分析原网页代码:
多页爬取
在换页的时候,我们发现网页的URL发生了改变:
第二页的URL:https://movie.douban.com/top250?start=25&filter=
第三页的URL:https://movie.douban.com/top250?start=50&filter=
我们发现,每跳一页,URL中参数start的值就增加25,所以可将start作为偏移量,来定位每一页网址.
代码如下:
# 解析源码
def main(start):
url = 'https://movie.douban.com/top250?start=' + str(start) + '&filter' # 定位top250的url
html = get_html(url) # 获取源码
for item in parse_html(html):
print(item)
if __name__ == '__main__':
for page in range(10):
main(page * 25) # 遍历10页,250部电影
将爬取到的信息写入txt文件:
定义如下函数,实现将数据写入txt文件的操作
def write_to_file(content):
with open("movies.txt", 'a', encoding='utf-8') as file: # 以追加的权限打开文件movies.txt
file.write(json.dumps(content, ensure_ascii=False) + '\n') # ensure_ascii设为False,保证输出是中文形式,而不是ASCII编码
# json.dumps()序列化时默认对中文使用ascii编码
这样就实现了豆瓣电影top250的爬取;
全部代码:
# 爬取豆瓣top250
import requests
import json
from bs4 import BeautifulSoup
# 获取源码
def get_html(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
print("访问失败")
# 解析源码
def parse_html(html):
soup = BeautifulSoup(html, 'lxml') # 创建BeautifulSoup对象,使用lxml解析库
items = soup.find_all(name='li') # 查询名称为li的元素,以列表形式输出
for item in items[19:]:
# 注意这里的[19:],对网页源码分析后发现前19个li标签中并没有我们需要的数据,所以将其排除在外
yield {
# 利用find()定位我们需要的数据,并作为生成器元素
'title': item.span.get_text(),
'index': item.find(name='em').text,
'image': item.find(name='a')['href'],
'quote': item.find(class_="inq").text,
'score': item.find(class_="rating_num").text
}
# 构造生成器,作为函数的返回结果
# 将数据转化为json字符串并写入到文件中
def write_to_file(content):
with open("movies.txt", 'a', encoding='utf-8') as file: # 以追加的权限打开文件movies.txt
file.write(json.dumps(content, ensure_ascii=False) + '\n') # ensure_ascii设为False,保证输出是中文形式,而不是ASCII编码
# json.dumps()序列化时默认对中文使用ascii编码
def main(start):
url = 'https://movie.douban.com/top250?start=' + str(start) + '&filter' # 定位top250的url
html = get_html(url)
for item in parse_html(html):
print(item)
write_to_file(item)
# 执行函数,完成爬取
if __name__ == '__main__':
for i in range(10):
main(i * 25)
从中的感觉就是,基本的语法、函数的使用是比较简单的;关键之处在于对网页源码的分析,找到合适的提取信息的方式。