爬取时间:2020-03-13
爬取难度:★★☆☆☆☆
这次采用的存储方式是sql数据库存储
爬取豆瓣Top250
一、循环爬取网页模板
打开豆瓣电影top榜单,请求地址为:https://movie.douban.com/top250
通关观察,我们可以发现每页展示25条电影信息,多次翻页我们可以观察到url的变化:
第一页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
通过以上我们可以看到每一页的“start= ”后面的数字跟随每一页的具体数值而改变。 电影总共有250部,以此类推,我们可以知道共10页。那么这10页要如何跳转呢?我么可以看下面的代码:
url = 'https://movie.douban.com/top250?start=%d&filter='
......
# 页面的跳转
def start_download(self):
while self.dstart < self.dtotal:
durl = self.durl%self.dstart
# print(durl)
self.load_page(durl)
self.dstart += self.dstep
break # 如果爬取全部可以直接放开
根据上面的url链接,再通过下面的自定义函数,实现页面跳转的功能。
二、解析与处理模块
再定义解析函数之前,我们需要添加一个并定义一个报错函数:
from urllib import error
def req_page(self,url):
# 请求异常处理
pass
详细看下这个函数req_page(),首先我们打开网页,如果出现错误,会打印出来,好让你可以根据错误修改程序,如果正常,就会跳转至下面的自定义功能函数:
def req_page(self,url):
try:
req=urllib.request.Request(url=url,headers=headers)
req = urlopen(req)
except error.HTTPError as e:
print('catch e:',e)
return None
except:
print('url request error:',url)
return None
if req.code!=200:
return
pageinfo = req.read().decode('utf-8')
return pageinfo
1、BeautifulSoup解析电影名称,评分信息和评论人数
首先我们需要再网页中查看电影名称,评分信息和评论人数等信息:
①电影名称
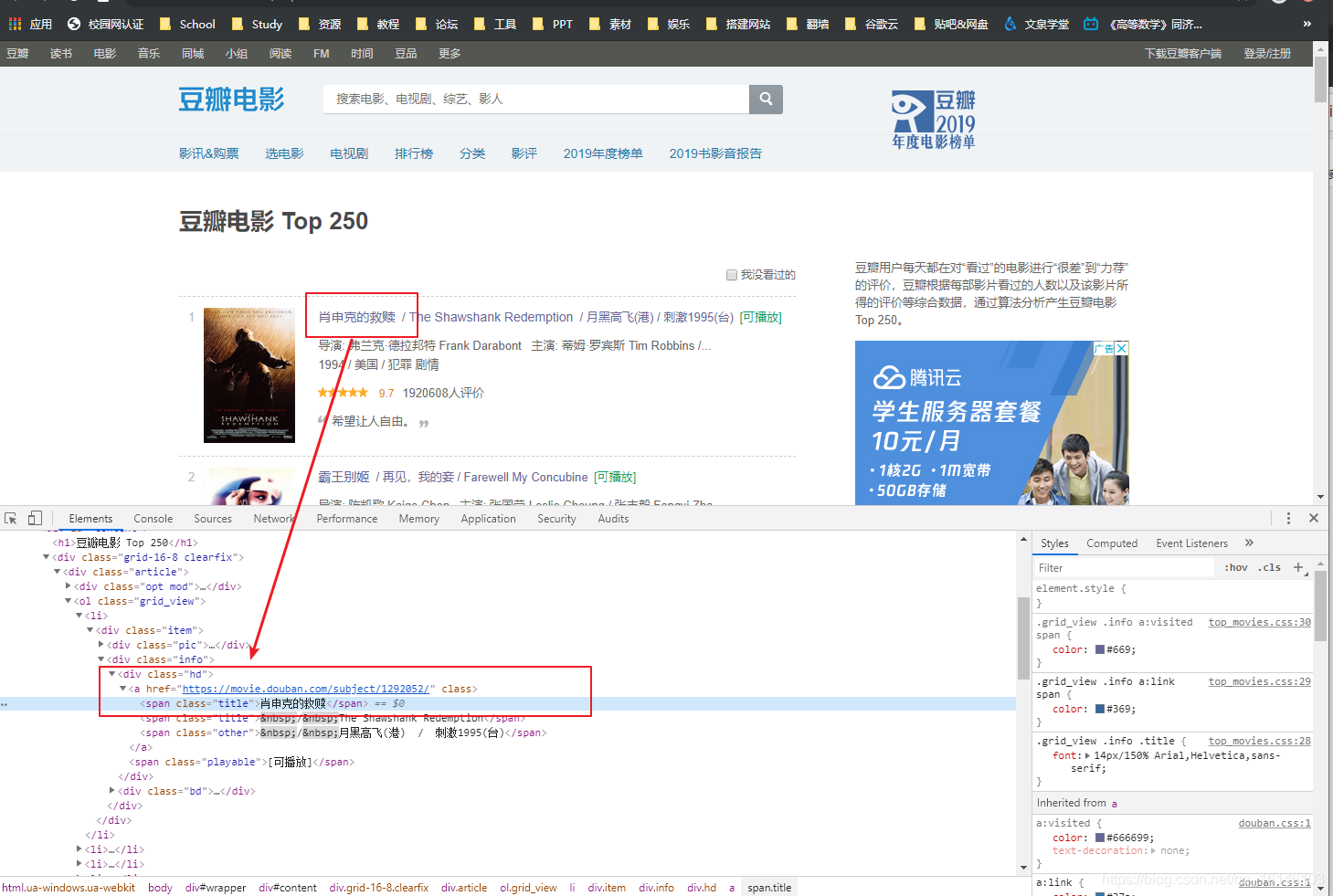
通过上面的图片我们知道,爬取的内容很简单,只需爬取span标签下的title就行了,代码如下:
listdiv = obj.find_all('div',class_='hd')
for div in listdiv:
# print(div)
murl = div.find('a').get('href')
mname = div.find('span',class_='title').get_text()
print(mname)
②评分信息
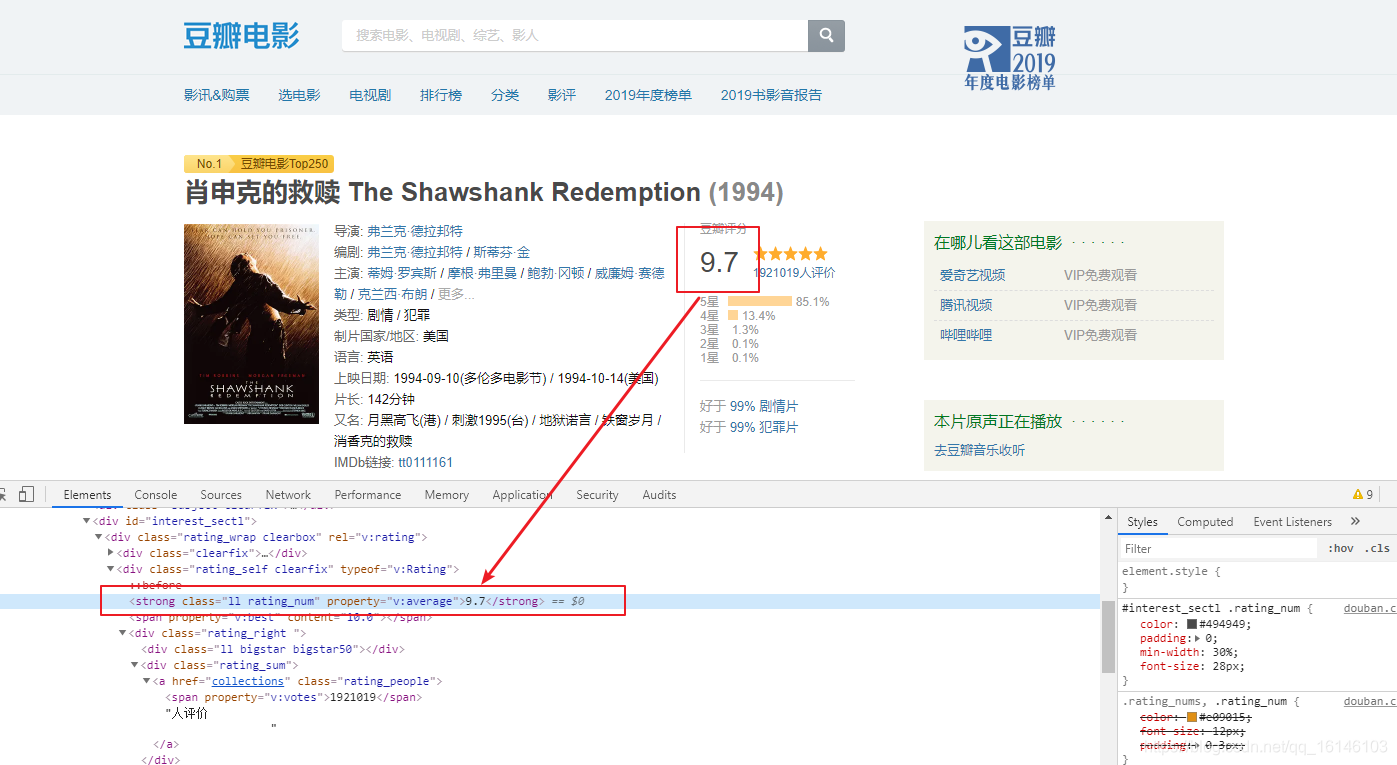
分析页面我们知道评分在<strong class="ll rating_num" property="v:average">9.7</strong>这个标签内,我们只需查找标签为property="v:average"就可以了,代码如下:
mscore = obj.find('div',class_="rating_self clearfix")
score = mscore.find(property="v:average").get_text()
③评论人数
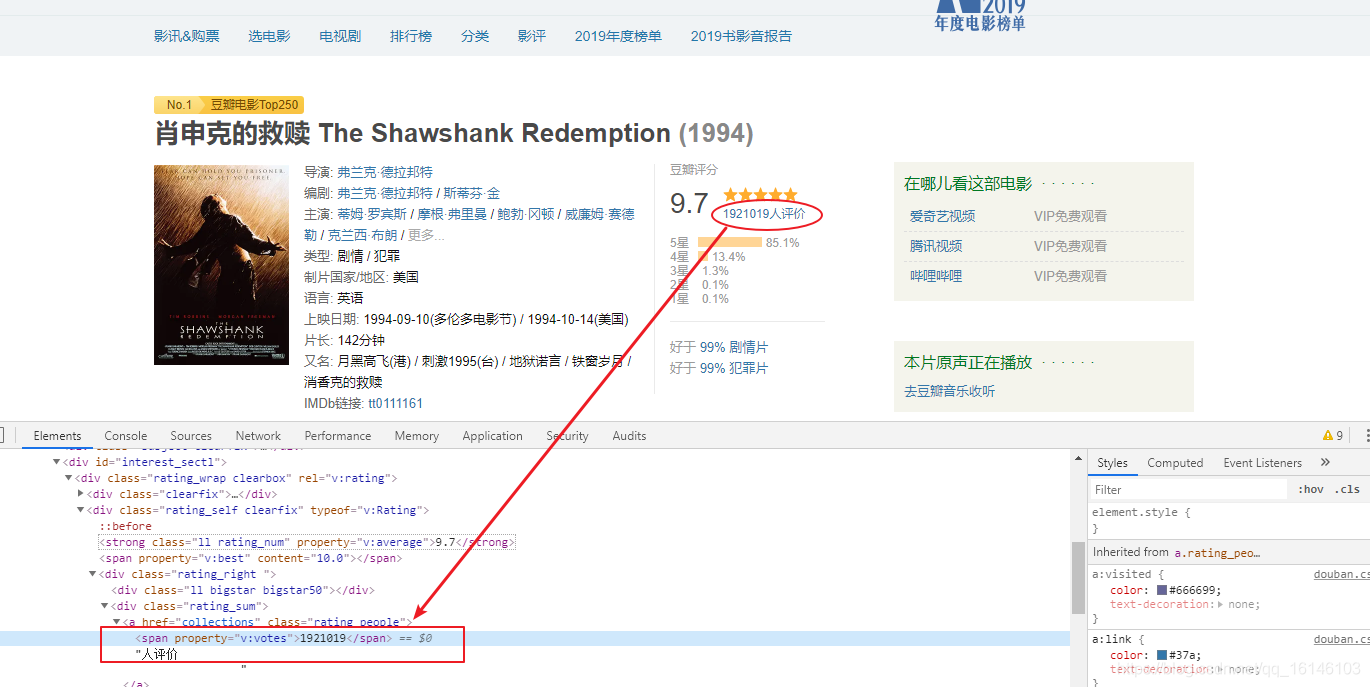
分析页面我们知道评分在<span property="v:votes">1921019</span>这个标签内,我们只需查找标签为property="v:votes"就可以了,代码如下:
votes = mscore.find(property="v:votes").get_text()
2、BeautifulSoup解析其他详细信息
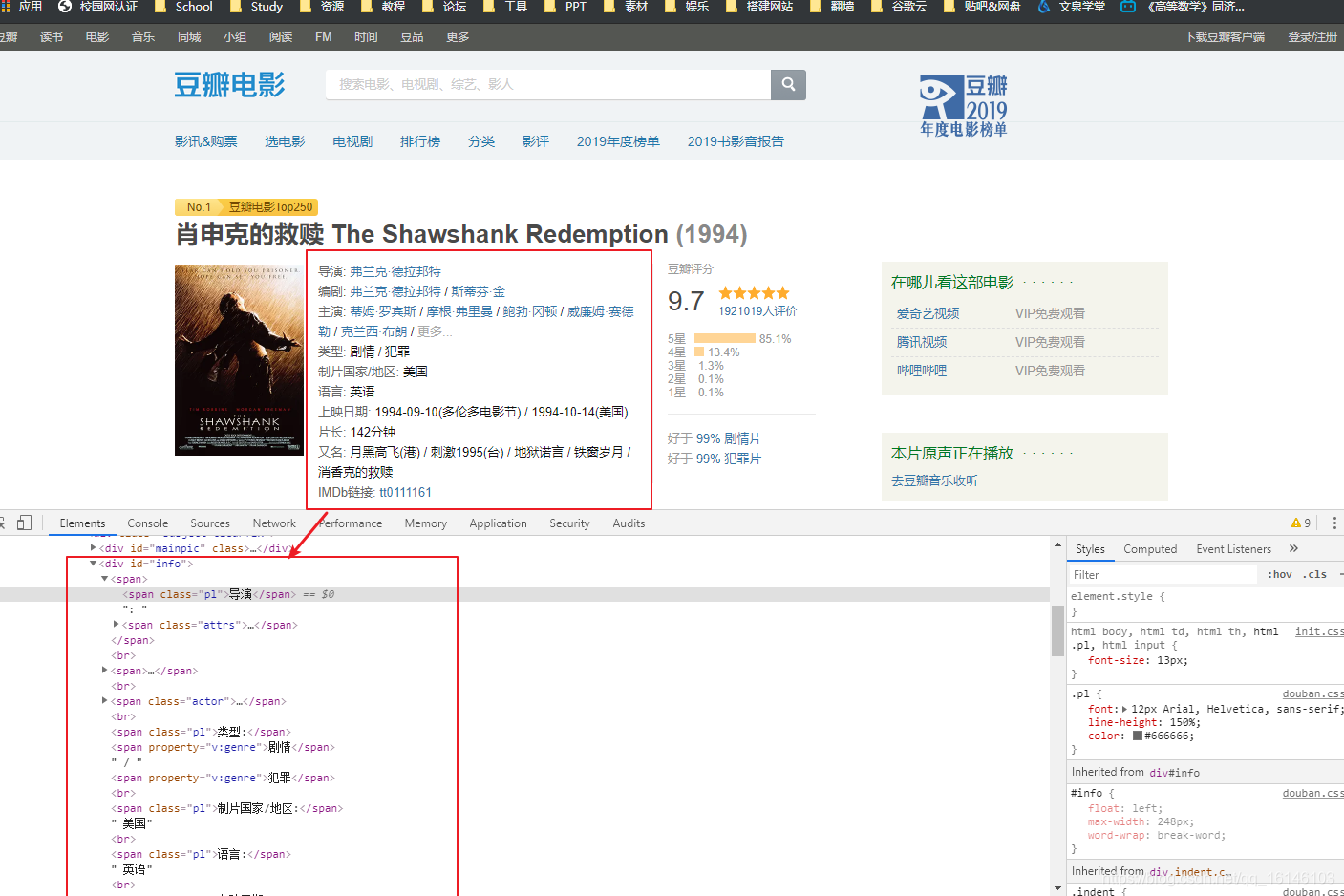
通过上面的网页分析,我们可以发现,这些详细信息都存放在<div id = "info">中,下面我们要做的就是将这些文字提取出来:
def parse_minfo(self,url,mname):
pinfo = self.req_page(url)
if not pinfo:
return
obj = BeautifulSoup(pinfo,'html5lib')
minfo = obj.find('div',id='info')
tinfo = minfo.get_text()
3、整合
上面的工作做完以后,我们需要把爬取的列表切割成字典,代码如下:
# 把列表切割成字典
def parse_text(self,minfo):
# listt = minfo.split('\n') # 切分
listt = [item.strip()for item in minfo.split('\n') if item.strip(' ')]
# # print(listt) # 此种打印有点问题
listt = [item.split(':') for item in listt]
listt = [items for items in listt if len(items) == 2 and items[0].strip() and items[1].strip()]
print(listt)
dinfo = dict(listt)
return dinfo
这是我们就可以把这部分的代码完整实现:
def parse_minfo(self,url,mname):
pinfo = self.req_page(url)
if not pinfo:
return
obj = BeautifulSoup(pinfo,'html5lib')
minfo = obj.find('div',id='info')
tinfo = minfo.get_text()
dinfo = self.parse_text(tinfo)
mscore = obj.find('div',class_="rating_self clearfix")
score = mscore.find(property="v:average").get_text()
votes = mscore.find(property="v:votes").get_text()
dinfo['评分'] = score
dinfo['评论人数'] = votes
dinfo['片名'] = mname
print(dinfo.keys())
for item in dinfo.items():
print(item)
三、保存文本内容以及图片
如果完成上面的操作,这时候我们就需要对他们进行保存了。保存之前我们还要对这些进行一些规范与调试,这些暂时不做细讲,直接上代码:
# 保存文本内容
def load_page(self,url):
pinfo = self.req_page(url)
if not pinfo:
return
obj = BeautifulSoup(pinfo,'html5lib')
listdiv = obj.find_all('div',class_='hd')
for div in listdiv:
# print(div)
murl = div.find('a').get('href')
mname = div.find('span',class_='title').get_text()
print(murl,mname)
minfo = self.parse_minfo(murl,mname)
if minfo:
keys = [ '片名','导演','编剧', '主演', '类型', '制片国家/地区',
'语言', '上映日期', '片长', '又名',
'评分', '评论人数']
self.infohd.write(keys,minfo)
break
# 保存图片
def load_img(self,info):
print("callhere load img:",info)
req=urllib.request.Request(url=info[1],headers=headers)
imgreq = urlopen(req)
img_c = imgreq.read()
path = r'D:\\test\\'+ info[0]+'.jpg'
print('path:', path)
imgf = open(path,'wb')
imgf.write(img_c)
imgf.close()
四、数据存储
数据存储一般情况下,单独写在一起比较好,这是我们创建一个minfo_save的文件,并定义一个 mysqlHandler的类型:
import pymysql
class mysqlHandler(object):
def __init__():
pass
def write():
pass
def close():
pass
在这个函数中,我们我们指定编码类型,以及key和所爬取内容的对应关系。
代码如下:
def __init__(self,host='localhost',user='root',passwd='',dbname='',tbname=''):
self.dbcon = pymysql.connect(host,user,passwd,dbname,charset = 'utf8')
self.cur = self.dbcon.cursor()
self.tname = tbname
self.id = 1 # 默认值
# 编写sql语句
def write(self,keys,info):
sql = 'insert into %s values'%self.tname
values = '(%s)'%(('%s,'*(len(keys)+1))[:-1])
sql += values
rowinfo = [info.get(key, ' ') for key in keys]
rowinfo.insert(0,self.id)
self.id += 1
self.cur.execute(sql,rowinfo)
self.dbcon.commit() # 入库
def close(self):
self.dbcon.close()
五、在mysql中创建表格
1、建立连接
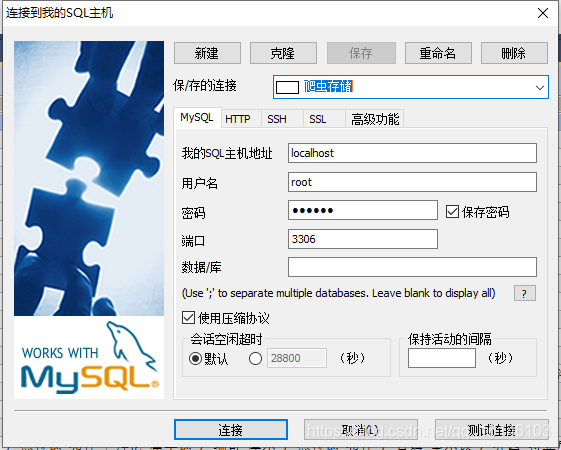
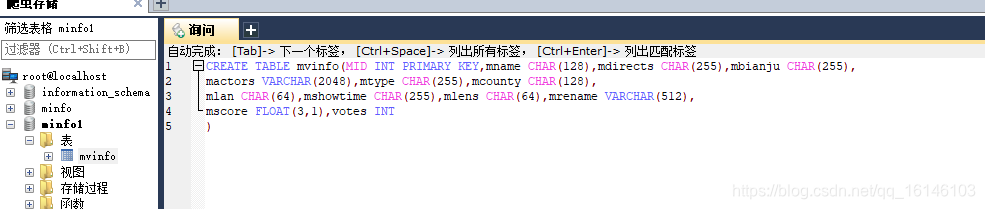
2、创建表格
六、完整代码
①minfo_spider
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2020-03-16
# @Author : 李华鑫
# @CSDN : https://blog.csdn.net/qq_16146103
# @FileName: douban250.py
# @Software: PyCharm
# =============================================
from urllib.request import urlopen
import urllib
from bs4 import BeautifulSoup
from urllib import error
from minfo_save import mysqlHandler
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Cookie':'bid=wjbgW95-3Po; douban-fav-remind=1; __gads=ID=f44317af32574b60:T=1563323120:S=ALNI_Mb4JL8QlSQPmt0MdlZqPmwzWxVvnw; __yadk_uid=hwbnNUvhSSk1g7uvfCrKmCPDbPTclx9b; ll="108288"; _vwo_uuid_v2=D5473510F988F78E248AD90E6B29E476A|f4279380144650467e3ec3c0f649921e; trc_cookie_storage=taboola%2520global%253Auser-id%3Dff1b4d9b-cc03-4cbd-bd8e-1f56bb076864-tuct427f071; viewed="26437066"; gr_user_id=7281cfee-c4d0-4c28-b233-5fc175fee92a; dbcl2="158217797:78albFFVRw4"; ck=4CNe; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1583798461%2C%22https%3A%2F%2Faccounts.douban.com%2Fpassport%2Flogin%3Fredir%3Dhttps%253A%252F%252Fmovie.douban.com%252Ftop250%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.1583974348.1563323123.1572242065.1583798461.8; __utmb=30149280.0.10.1583798461; __utmc=30149280; __utmz=30149280.1583798461.8.7.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login; __utma=223695111.424744929.1563344208.1572242065.1583798461.4; __utmb=223695111.0.10.1583798461; __utmc=223695111; __utmz=223695111.1583798461.4.4.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login; push_noty_num=0; push_doumail_num=0; _pk_id.100001.4cf6=06303e97d36c6c15.1563344208.4.1583798687.1572242284.'}
url = 'https://movie.douban.com/top250?start=%d&filter='
class spider_douban250(object):
# 页面初始化
def __init__(self,url = None, start = 0, step = 25 , total = 250,savehd=None):
self.durl = url
self.dstart = start
self.dstep =step
self.dtotal = total
self.infohd = savehd
# 页面的跳转
def start_download(self):
while self.dstart < self.dtotal:
durl = self.durl%self.dstart
# print(durl)
self.load_page(durl)
self.dstart += self.dstep
break # 如果爬取全部可以直接放开
def req_page(self,url):
# 请求异常处理
try:
req=urllib.request.Request(url=url,headers=headers)
req = urlopen(req)
except error.HTTPError as e:
print('catch e:',e)
return None
except:
print('url request error:',url)
return None
if req.code!=200:
return
pageinfo = req.read().decode('utf-8')
return pageinfo
# 把列表切割成字典
def parse_text(self,minfo):
# listt = minfo.split('\n') # 切分
listt = [item.strip()for item in minfo.split('\n') if item.strip(' ')]
# # print(listt) # 此种打印有点问题
listt = [item.split(':') for item in listt]
listt = [items for items in listt if len(items) == 2 and items[0].strip() and items[1].strip()]
print(listt)
dinfo = dict(listt)
return dinfo
# 对返回值进行处理
def parse_minfo(self,url,mname):
pinfo = self.req_page(url)
if not pinfo:
return
obj = BeautifulSoup(pinfo,'html5lib')
minfo = obj.find('div',id='info')
tinfo = minfo.get_text()
dinfo = self.parse_text(tinfo)
mscore = obj.find('div',class_="rating_self clearfix")
score = mscore.find(property="v:average").get_text()
votes = mscore.find(property="v:votes").get_text()
dinfo['评分'] = score
dinfo['评论人数'] = votes
dinfo['片名'] = mname
print(dinfo.keys())
for item in dinfo.items():
print(item)
return dinfo
# 保存文本内容
def load_page(self,url):
pinfo = self.req_page(url)
if not pinfo:
return
obj = BeautifulSoup(pinfo,'html5lib')
listdiv = obj.find_all('div',class_='hd')
for div in listdiv:
# print(div)
murl = div.find('a').get('href')
mname = div.find('span',class_='title').get_text()
print(murl,mname)
minfo = self.parse_minfo(murl,mname)
if minfo:
keys = [ '片名','导演','编剧', '主演', '类型', '制片国家/地区',
'语言', '上映日期', '片长', '又名',
'评分', '评论人数']
self.infohd.write(keys,minfo)
break
# 保存图片
def load_img(self,info):
print("callhere load img:",info)
req=urllib.request.Request(url=info[1],headers=headers)
imgreq = urlopen(req)
img_c = imgreq.read()
path = r'D:\\test\\'+ info[0]+'.jpg'
print('path:', path)
imgf = open(path,'wb')
imgf.write(img_c)
imgf.close()
sql = mysqlHandler('localhost','root','199712','minfo1','mvinfo') # 此处这些都要记住自己的,每个人都不一样的
spider = spider_douban250(url,start=0,step=25,total=10,savehd=sql)
spider.start_download()
②minfo_save
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2020-03-16
# @Author : 李华鑫
# @CSDN : https://blog.csdn.net/qq_16146103
# @FileName: douban250.py
# @Software: PyCharm
# =============================================
import pymysql
class mysqlHandler(object):
def __init__(self,host='localhost',user='root',passwd='',dbname='',tbname=''):
self.dbcon = pymysql.connect(host,user,passwd,dbname,charset = 'utf8')
self.cur = self.dbcon.cursor()
self.tname = tbname
self.id = 1 # 默认值
# 编写sql语句
def write(self,keys,info):
sql = 'insert into %s values'%self.tname
values = '(%s)'%(('%s,'*(len(keys)+1))[:-1])
sql += values
rowinfo = [info.get(key, ' ') for key in keys]
rowinfo.insert(0,self.id)
self.id += 1
self.cur.execute(sql,rowinfo)
self.dbcon.commit() # 入库
def close(self):
self.dbcon.close()
if __name__ == '__main__':
sql = mysqlHandler('localhost','root','199712','minfo1','mvinfo')
sql.write([],[])
sql.close()
七、数据截图
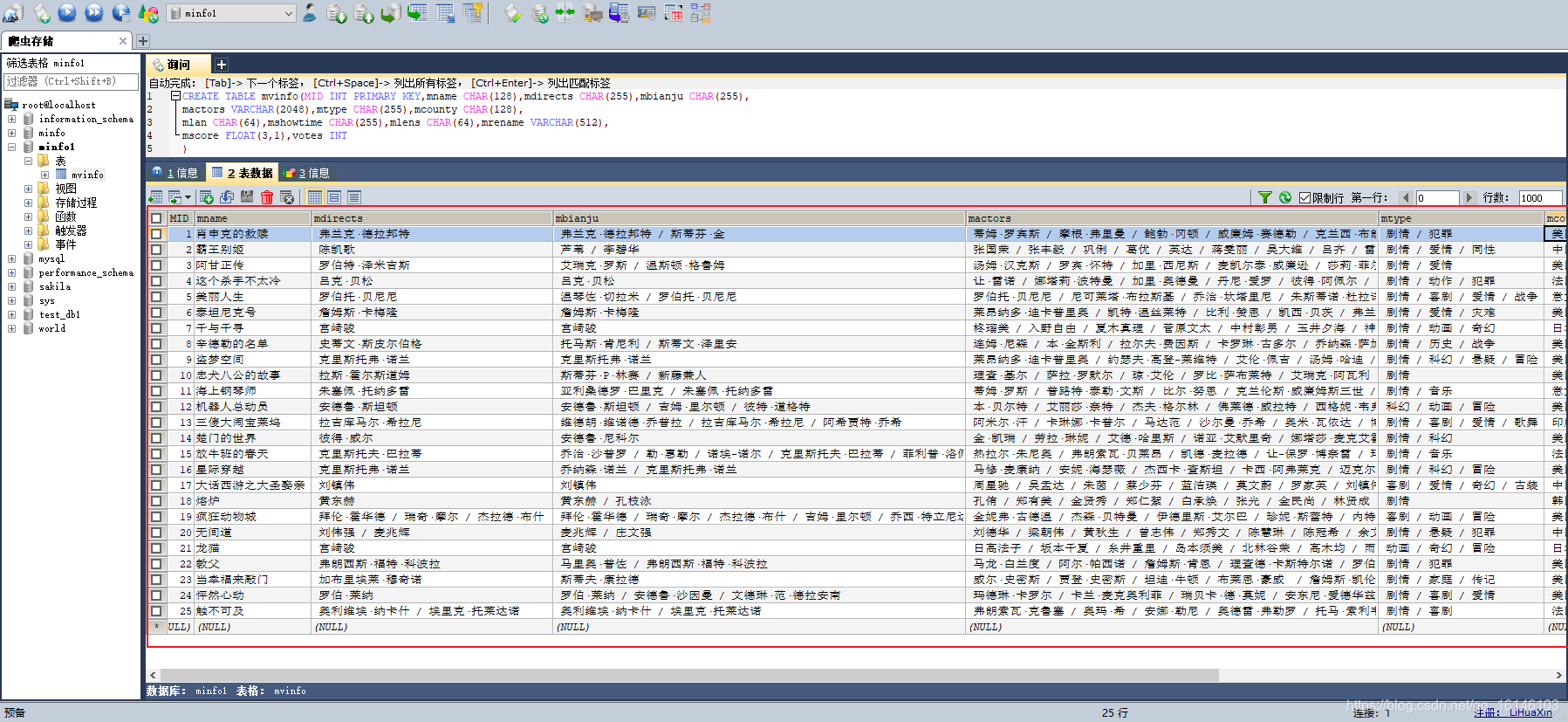
八、程序的不足之处
程序不足的地方:豆瓣电影有反爬机制,由于没有添加时间间隔,以及IP代理池没有构建以及多线程的使用,在爬取一百多条数据的时候,IP会被封禁,第二天才会解封。如果有能力的可以添加多个User—Agent、添加时间间隔以及使用多个代理IP进行完善代码。
除此之外,由于此代码没有用较为常用的requests库,可以考虑使用此库。
