1.爬取网址:https://movie.douban.com/top250?start=0
通过scrapy startproject douban创建项目
通过scrapy genspider doubanmovie "douban"创建spider

在settings.py文件中设置管道文件和mongodb的基本信息:


打开延迟
items.py

doubanmovie.py文件:
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem
class DoubanmovieSpider(scrapy.Spider):
name = 'doubanmovie'
allowed_domains = ['douban.com']
# https://movie.douban.com/top250?start=25&filter=
offset = 0
url = "http://movie.douban.com/top250?start="
start_urls = [url + str(offset)]
def parse(self, response):
item = DoubanItem()
movies = response.xpath("//div[@class='info']")
for each in movies:
# 标题
item['title'] = each.xpath(".//span[@class='title'][1]/text()").extract()[0]
# 信息
item['bd'] = each.xpath(".//div[@class='bd']/p/text()").extract()[0]
# 评分
item['star'] = each.xpath(".//div[@class='star']/span[@class='rating_num']/text()").extract()[0]
# 简介
quote = each.xpath(".//p[@class='quote']/span/text()").extract()
if len(quote) != 0:
item['quote'] = quote[0]
yield item
if self.offset < 225:
self.offset += 25
scrapy.Request(self.url + str(self.offset), callback=self.parse)
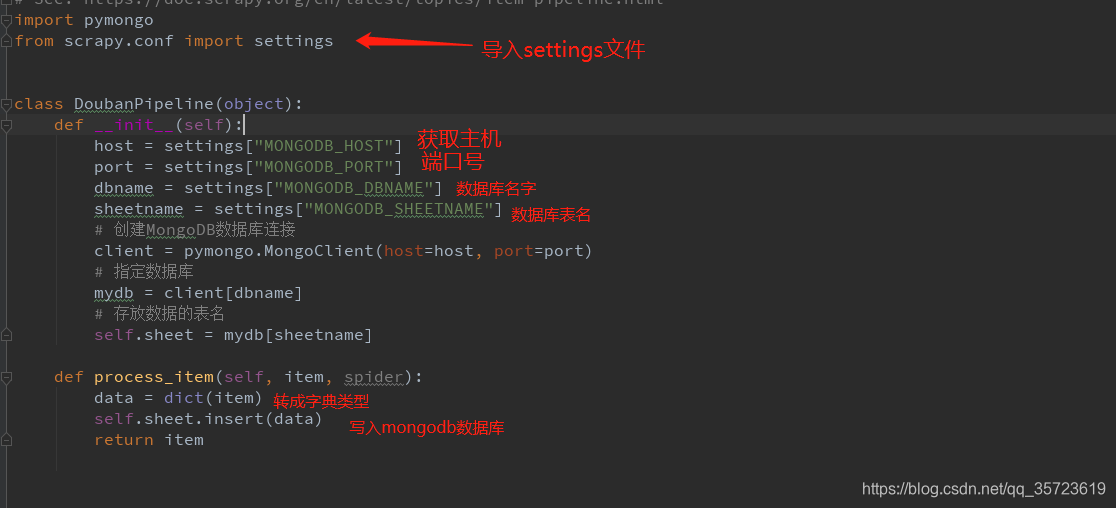
管道文件:
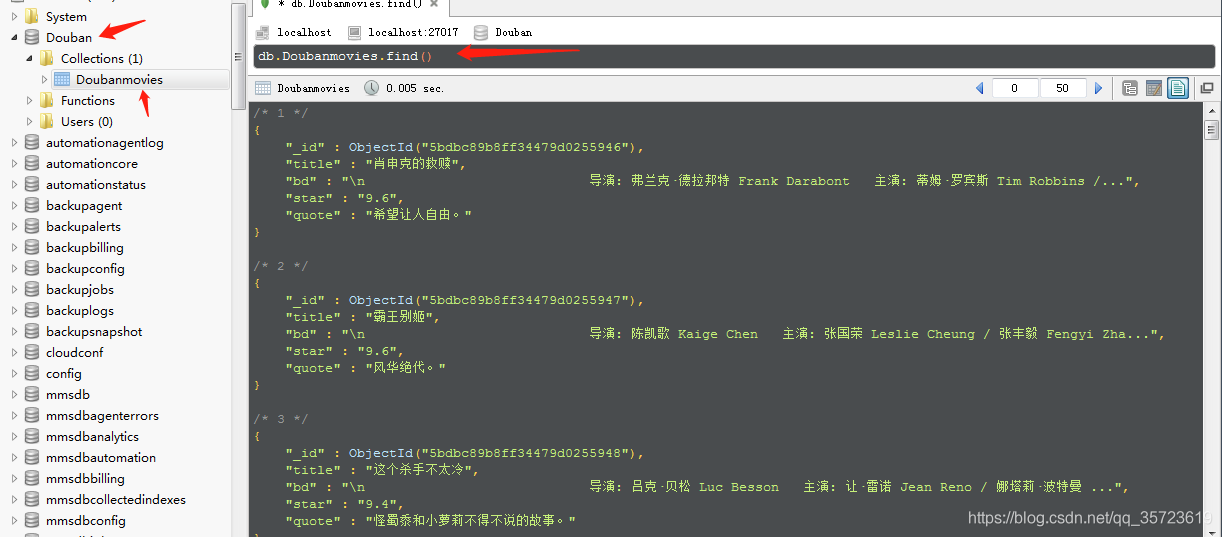
通过robo 3T查看: