版权声明:zhiyu https://blog.csdn.net/ichglauben/article/details/82559310
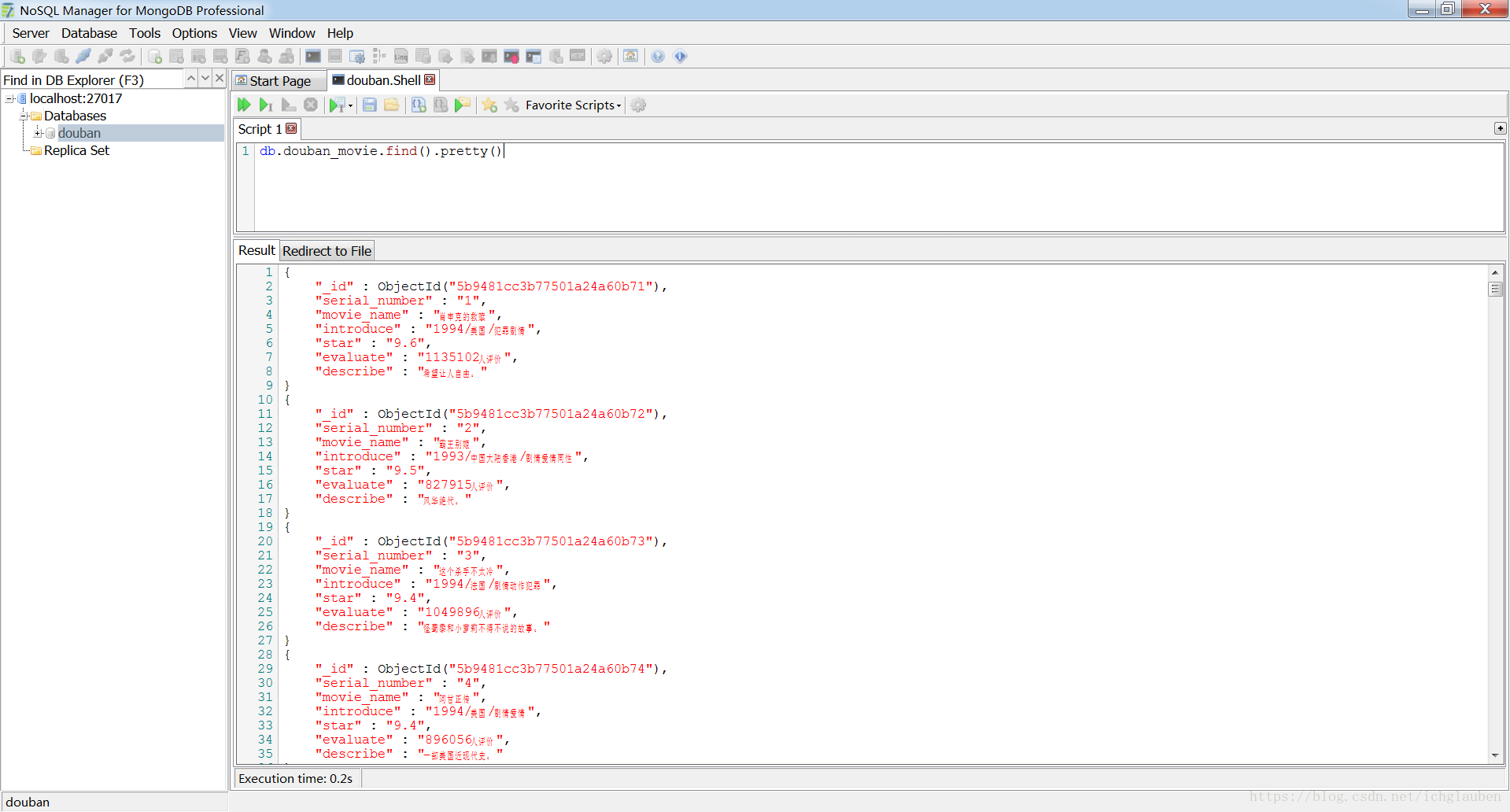
存到mongodb中
环境
windows7
mongodb4.0mongodb安装教程
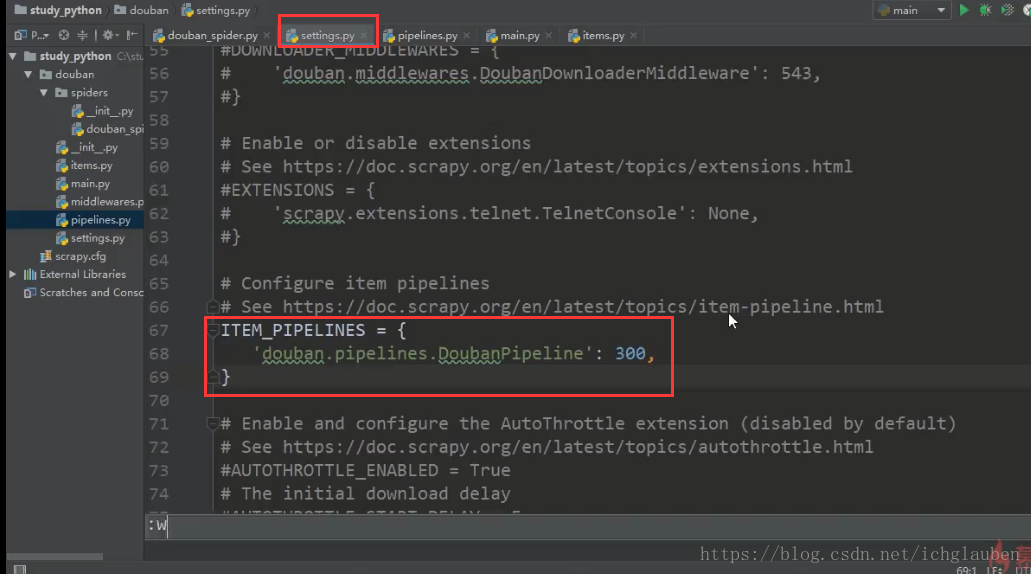
设置具体参数
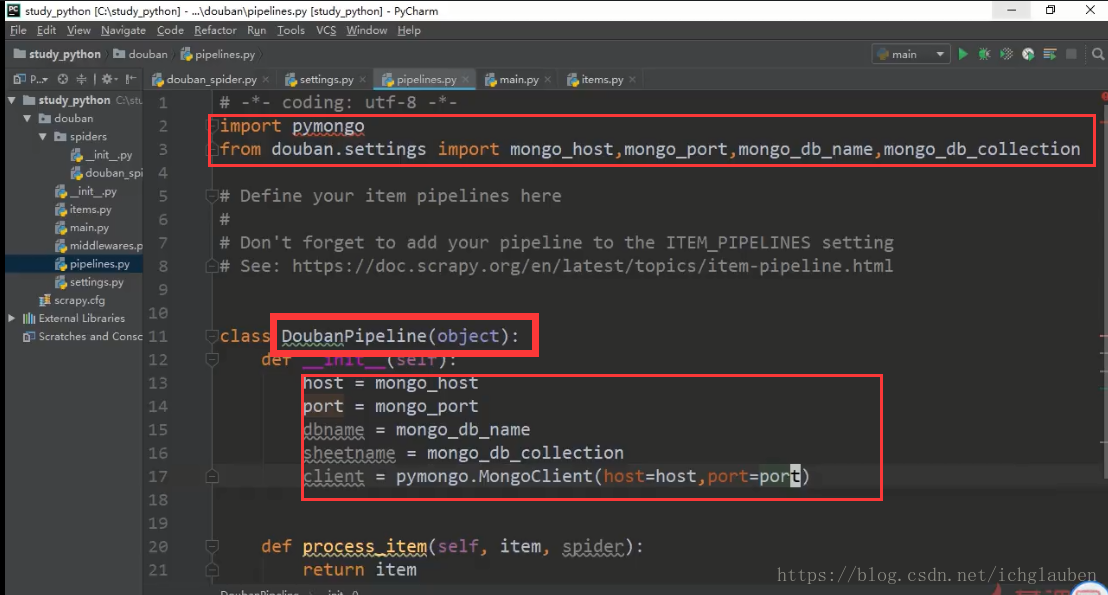
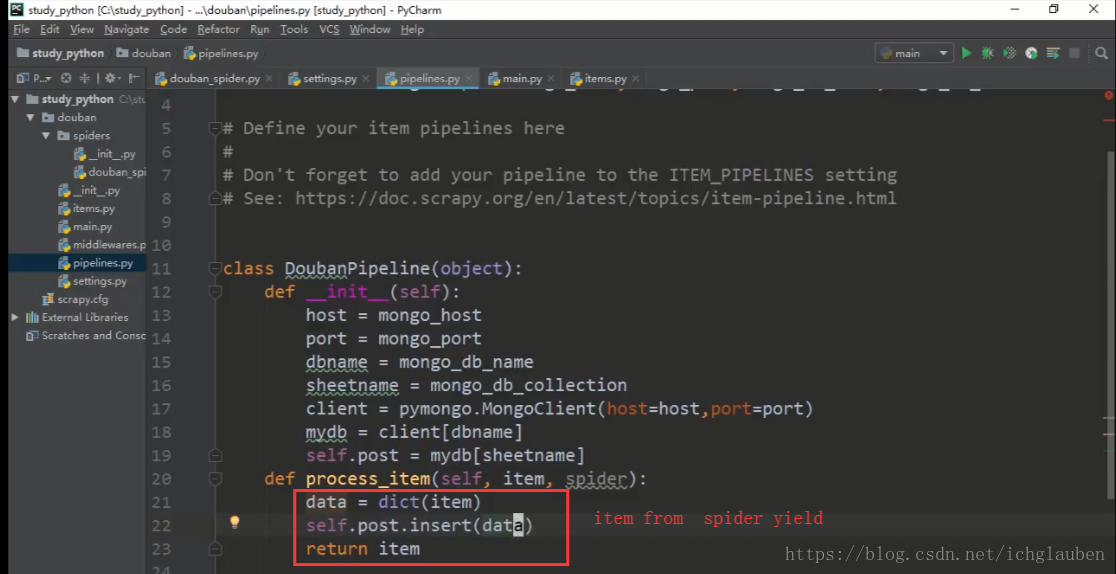
在管道里面写具体参数
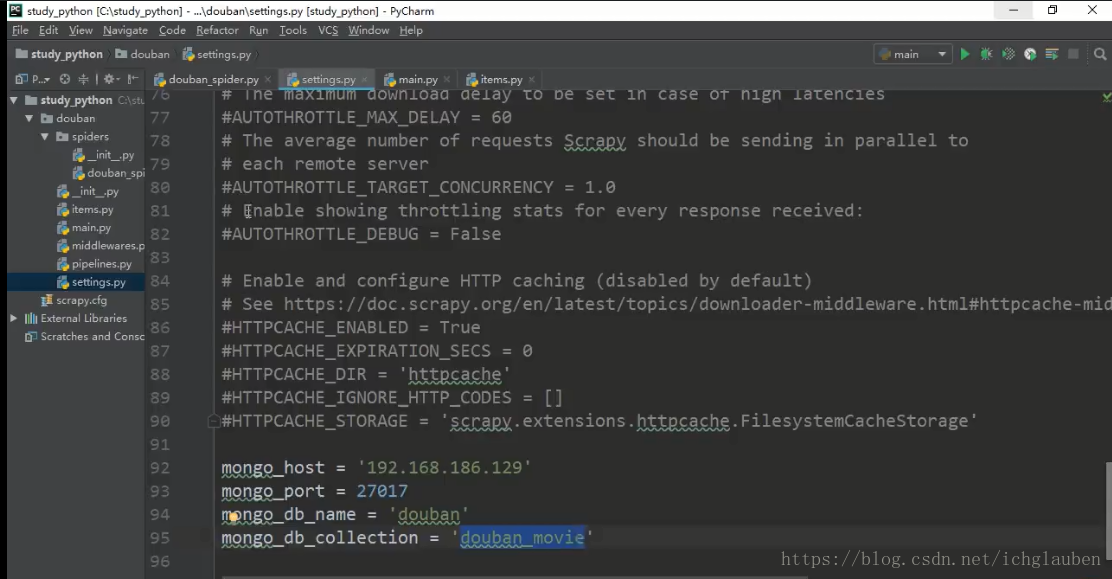
打开settings 设置参数
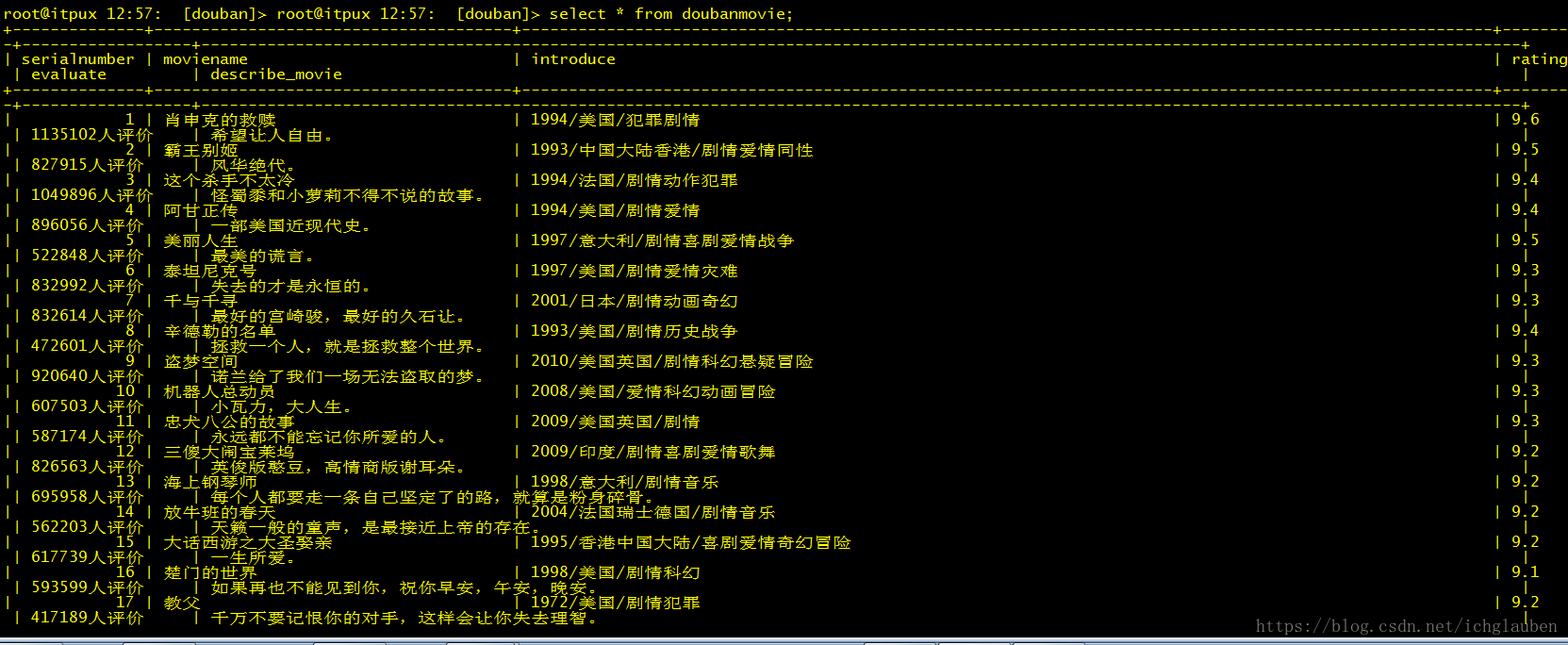
测试开始–结果
代码
import pymongo
from douban.settings import mongo_host,mongo_port,mongo_db_name,mongo_db_collection
class DoubanPipeline(object):
def __init__(self):
host = mongo_host
port = mongo_port
dbname = mongo_db_name
sheetname = mongo_db_collection
client = pymongo.MongoClient(host=host,port=port)
mydb = client[dbname]
self.post = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
self.post.insert(data)
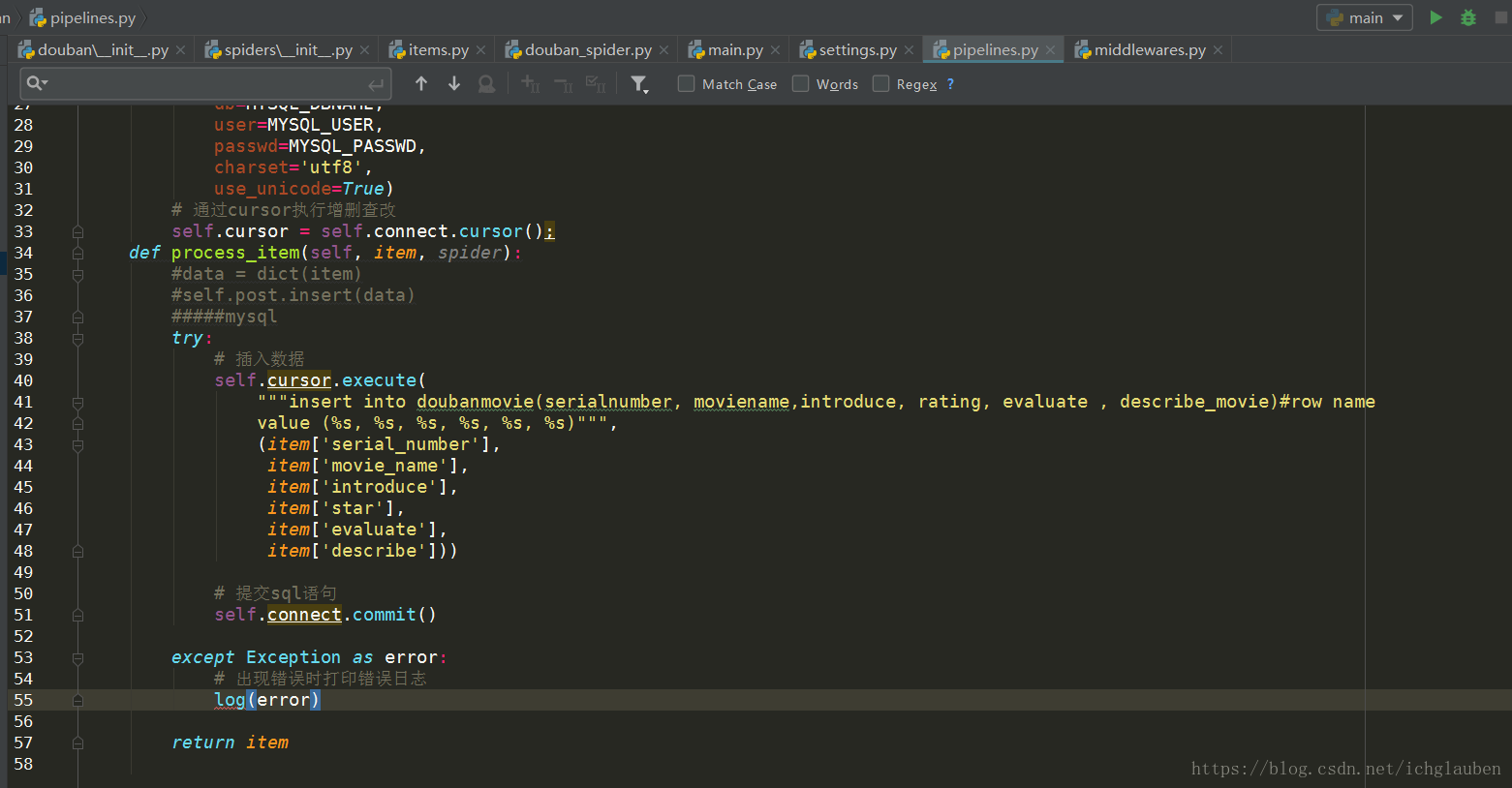
return item存到mysql中
大致步骤类似 不过先要建表
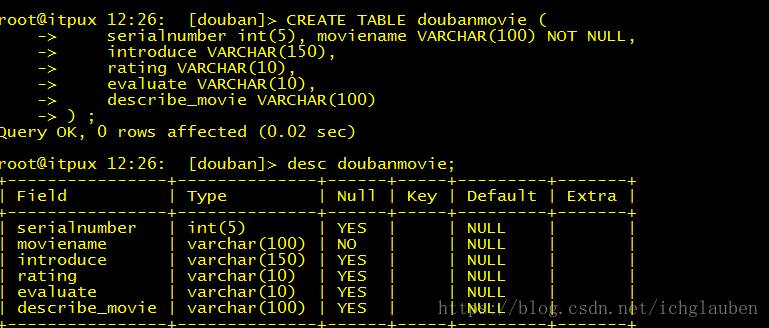
create database douban DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
use douban;
CREATE TABLE doubanmovie (
serialnumber int(5), moviename VARCHAR(100) NOT NULL,
introduce VARCHAR(150),
rating VARCHAR(10),
evaluate VARCHAR(10),
describe_movie VARCHAR(100)
) ;setttings设置
MYSQL_HOST = '192.168.1.117'
MYSQL_DBNAME = 'douban'
MYSQL_USER = 'root'
MYSQL_PASSWD = 'root'
在管道里面写参数
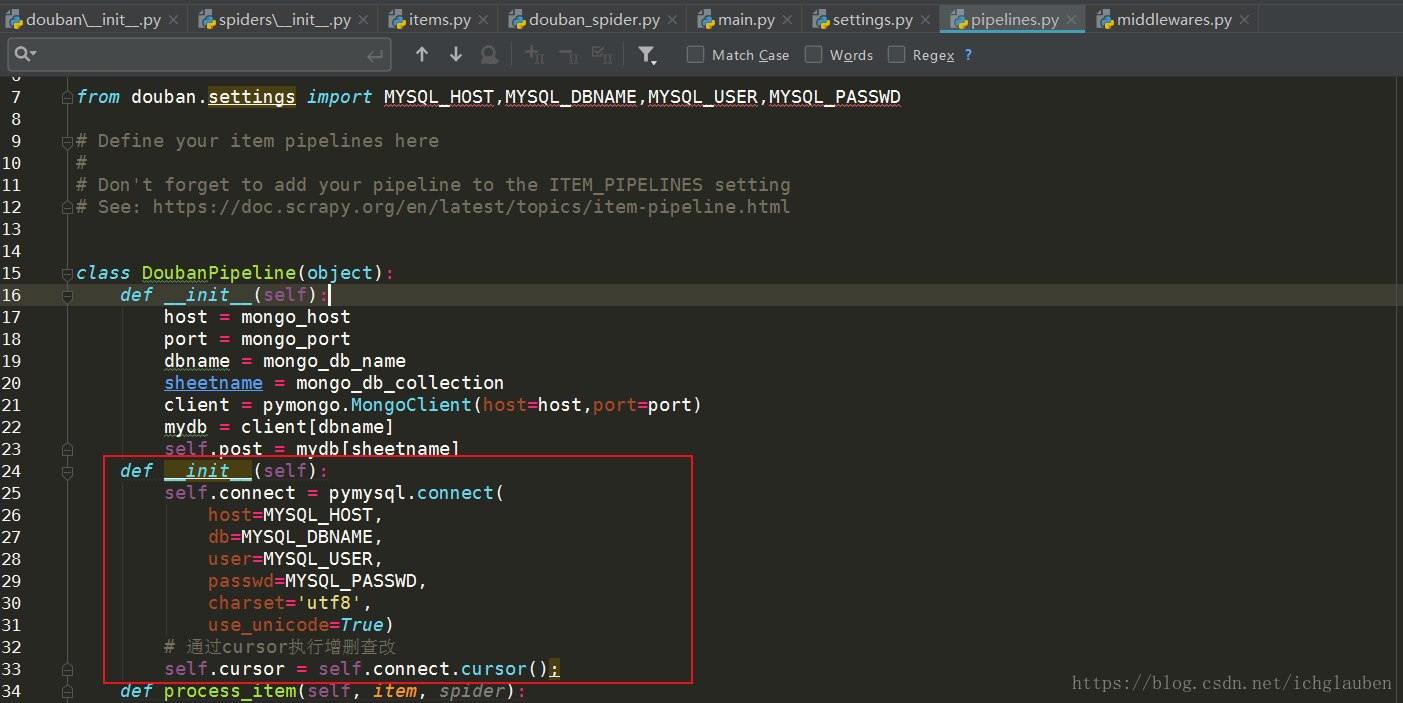
def __init__(self):
self.connect = pymysql.connect(
host=MYSQL_HOST,
db=MYSQL_DBNAME,
user=MYSQL_USER,
passwd=MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
# 通过cursor执行增删查改
self.cursor = self.connect.cursor();
def process_item(self, item, spider):
#data = dict(item)
#self.post.insert(data)
#####mysql
try:
# 插入数据
self.cursor.execute(
"""insert into doubanmovie(serialnumber, moviename,introduce, rating, evaluate , describe_movie)#row name
value (%s, %s, %s, %s, %s, %s)""",
(item['serial_number'],
item['movie_name'],
item['introduce'],
item['star'],
item['evaluate'],
item['describe']))
# 提交sql语句
self.connect.commit()
except Exception as error:
# 出现错误时打印错误日志
log(error)
return item