过拟合:指模型对于训练数据拟合呈过当的情况,反映到评估指标上,是模型在训练集上表现很好,但在测试集和新数据上表现较差,在模型训练过程中,表现为训练误差持续下降,同时测试误差出现持续增长的情况。
欠拟合:指模型对于训练数据拟合不足的情况,表现为模型在训练集和测试集表现都不好。
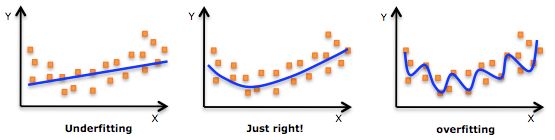
如上图所示,从左至右,依次为欠拟合、正常模型、过拟合情况,欠拟合情况中,拟合蓝线没有很好地捕捉到数据的特征,不能很好地拟合数据;过拟合的模型过于复杂,把噪声数据的特征也学习到模型中,导致模型泛化能力下降。
1 降低“过拟合”风险策略
1.1 获取更多的训练数据
使用更多的训练数据是解决过拟合问题的最有效手段,因为更多的样本能够让模型学习到更多更有效的特征,减小噪声的影响,一般通过以下3个手段获取更多数据:
1.1.1 增加实验数据
增加实验数据来扩充训练数据,例如,图像分类问题,多拍几张物体的照片,但是在大多数情况下,大幅增加实验数据很困难,而且我们不清楚多少数据才能足够。
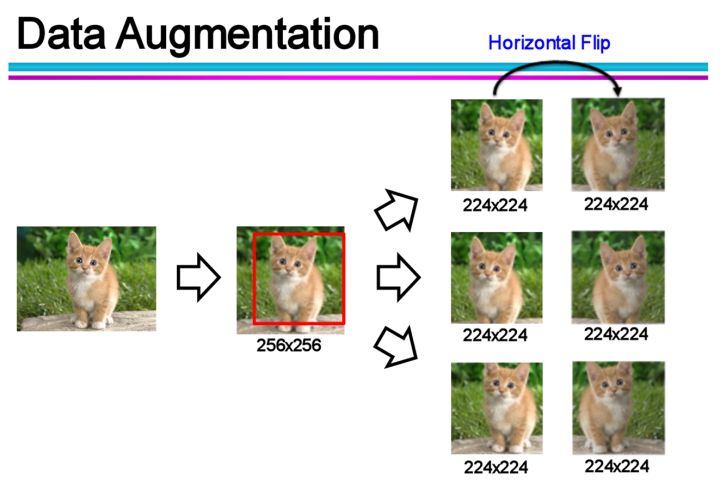
1.1.2 数据增广(Data Augmentation)
通过一定规则扩充数据,例如,图像分类问题,可以通过对现有图像进行平移、旋转、缩放等方式生成新的图片,以扩充训练数据。
1.1.3 合成数据
使用生成对抗网络(Generative Adversarial Network,GAN)来合成大量的新训练数据。
1.2 调整模型
在数据较少时,模型过于复杂是产生过拟合的主要因素,适当降低模型复杂度可以避免模型拟合过多的采样噪声。
1.2.1 调整模型结构
神经网络模型:减少网络层数、隐层神经元数量等;
决策树模型:降低树的深度、进行剪枝等。
1.2.2 早停(Early stopping)
将数据分成训练集和验证集,训练集用来计算梯度、更新超参数,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练。
1.2.3 正则化(regularzation)
基本思想为,在损失函数中一个用于描述网络复杂度的部分,即结构风险项,在模型训练过程中限制权重增大。以L2正则化为例:
其中, 为经验风险,即实际输出与样本之间的误差, 为网络权重, 为零本数量, 为正则化系数,用于对经验风险与结构风险这两项进行折中。
1.3 增加噪声
1.3.1 在输入中加噪声
噪声会随着网络传播,按照权值的平方放大,并传播到输出层,对误差(经验风险)产生影响。

在输入中加高斯噪声,会在输出中生成 的干扰项。训练时,减小误差,同时也会对噪声产生的干扰项进行惩罚,达到减小权值的平方的目的,与L2正则效果类似。
1.3.2 在权值上加噪声
在初始化网络的时候,用0均值的高斯分布作为初始化。Alex Graves 的手写识别 RNN 就是用了这个方法《A novel connectionist system for unconstrained handwriting recognition》。
1.3.3 对网络的响应加噪声
如在前向传播过程中,让部分神经元输出变为binary或random,这种做法会打乱网络的训练过程,让训练更慢,但据Hinton说,在测试集上效果会有显著提升。
1.4 集成学习
把多个模型集成在一起,来降低单一模型的过拟合风险。
1.4.1 Boosting
Boosting的工作机制如下:
- 从初始训练集训练出一个基学习器;
- 根据基学习器的表现对训练样本分布进行调整,使先前基学习器做错的训练样本在后续受到更多的关注;
- 基于调整后的样本分布来训练下一个基学习器;
- 如此重复,直至基学习器数目达到事先指定的值 ;
- 最终,将这 个基学习器进行加权结合。
1.4.2 Bagging
Bagging的工作机制如下:
- 使用自助采样法,生成 个训练样本集;
- 基于每个采样集训练出一个基学习器;
- 最后,将这些基学习器的预测结果进行结合,例如,对于分类问题,使用简单投票法进行结合,对于回归问题,使用简单平均法进行结合;
1.5 Dropout
以神经网络模型为例,在训练过程中,每次以一定概率随机忽略的部分隐层节点,这是一种非常高效的方法。
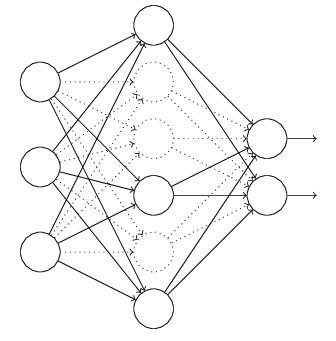
1.6 Batch Normalization
以神经网络为例,在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层。
Batch Normalization可以加快网络收敛速度,降低过拟合风险,具体实现如下图所示:

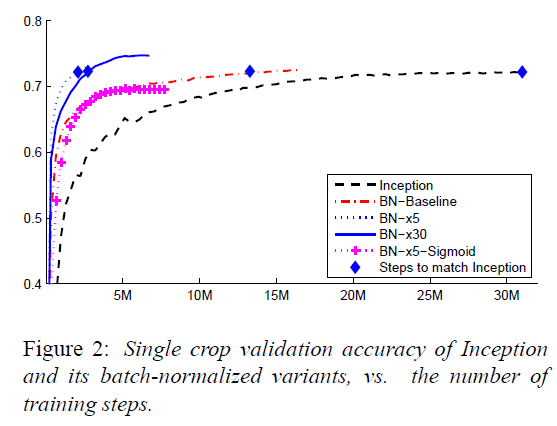

可以看出,使用Batch Normalization之后,模型收敛速度提升非常明显,同时,测试正确率也有所提升。
2 降低“欠拟合”风险策略
2.1 添加新特征
当特征不足或现有特征与样本标签的相关性不强时,模型容易出现欠拟合。
- 可以通过挖掘“上下文特征”、“ID类特征”、“组合特征”等新的特征;
- 利用一些模型帮助完成特征工程,如因子分解机、梯度提升决策树、Deep-crossing等。
2.2 增加模型复杂度
简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更加强大的拟合能力。
2.2.1 调整模型结构
对于线性模型,添加高次项;
对于神经网络模型,增加网络层数或神经元数量。
2.2.2 减小正则化系数
对于有正则化项的模型,可以通过减小正则化系数,来降低对模型复杂度的惩罚力度,进而提升模型的拟合能力。