《动手学深度学习pytorch》部分学习笔记,仅用作自己复习。
如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不一定更准确。
训练误差和泛化误差
在解释上述现象之前,我们需要区分训练误差(training error)和泛化误差(generalization error)。通俗来讲,前者指模型在训练数据集上表现出的误差,后者指模型在任意⼀个测试数据样本上表现出的误差的期望,并常通过测试数据集上的误差来近似。计算训练误差和泛化误差可以使用之前介绍过的损失函数,例如线性回归⽤到的平方损失函数和softmax回归用到的交叉熵损失函数。
机器学习模型应关注降低泛化误差。
模型选择
在机器学习中,通常需要评估若干候选模型的表现并从中选择模型。这⼀过程称为模型选择(model selection)。可供选择的候选模型可以是有着不同超参数的同类模型。
验证数据集
从严格意义上讲,测试集只能在所有超参数和模型参数选定后使⽤一次。不可以使⽤测试数据选择模型,如调参。由于无法从训练误差估计泛化误差,因此也不应只依赖训练数据选择模型。鉴于此,我们可以预留一部分在训练数据集和测试数据集以外的数据来进行模型选择。这部分数据被称为验证数据集,简称验证集(validation set)。例如,我们可以从给定的训练集中随机选取⼀小部分作为验证集,⽽将剩余部分作为真正的训练集。
然⽽在实际应用中,由于数据不容易获取,测试数据极少只使⽤一次就丢弃。因此,实践中验证数据集和测试数据集的界限可能比较模糊。从严格意义上讲,除⾮明确说明,实验所使⽤的测试集应为验证集,实验报告的测试结果(如测试准确率)应为验证结果(如验证准确率)。
K折交叉验证
由于验证数据集不参与模型训练,当训练数据不够⽤时,预留大量的验证数据显得太奢侈。
⼀种改善的方法是K折交叉验证(K -fold cross-validation)。在K 折交叉验证中,我们把原始训练数据集分割成个不重合的⼦子数据集,然后我们做K 次模型训练和验证。每一次,我们使⽤一个子数据集验证模型,并使用其他K-1 个⼦数据集来训练模型。在这K 次训练和验证中,每次用来验证模型的⼦数据集都不同。最后,我们对这K 次训练误差和验证误差分别求平均。
欠拟合和过拟合
模型训练中经常出现的两类典型问题:⼀类是模型⽆法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting);另⼀一类是模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)。
重点讨论两个因素:模型复杂度和训练数据集⼤小。
模型复杂度
为了解释模型复杂度,我们以多项式函数拟合为例。给定⼀个由标量数据特征 x和对应的标量标签 y组成的训练数据集,多项式函数拟合的⽬标是找一个K 阶多项式函数来近似y 。w是模型的权重参数,b 是偏差参数。与线性回归相同,多项式函数拟合也使⽤用平方损失函数。特别地,一阶多项式函数拟合⼜叫线性函数拟合。

给定训练数据集,如果模型的复杂度过低,很容易易出现欠拟合;如果模型复杂度过高,很容易出现过拟合。应对欠拟合和过拟合的⼀个办法是针对数据集选择合适复杂度的模型。

训练数据集⼤小
⼀般来说,如果训练数据集中样本数过少,特别是比模型参数数量量(按元素计)更少时,过拟合更容易生。此外,泛化误差不不会随训练数据集⾥样本数量量增加⽽增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集⼤一些,特别是在模型复杂度较⾼时,例如层数较多的深度学习模型。
多项式函数拟合实验
以多项式函数拟合为例来实验。
%matplotlib inline
import torch
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l⽣成数据集
⽣成⼀个⼈工数据集。在训练数据集和测试数据集中,给定样本特征 x,我们使⽤如下的三阶多项式函数来⽣成该样本的标签:
![]()
![]()
# 训练数据集和测试数据集的样本数都设为100。
n_train, n_test, true_w, true_b = 100, 100, [1.2, -3.4, 5.6], 5
# torch.randn(a,b)生成(a,b)维均值为0,方差为1的高斯序列
features = torch.randn((n_train + n_test, 1))
# torch.cat是将两个张量(tensor)拼接在一起,cat是concatnate的意思,即拼接,联系在一起,第二个参数决定按行还是按列拼接 torch.pow()求幂
# 将x的1到3次幂按列叠加
poly_features = torch.cat((features, torch.pow(features, 2),torch.pow(features, 3)), 1)
labels = (true_w[0] * poly_features[:, 0] + true_w[1] *
poly_features[:, 1]
+ true_w[2] * poly_features[:, 2] + true_b)
labels += torch.tensor(np.random.normal(0, 0.01,
size=labels.size()), dtype=torch.float)看⼀看⽣成的数据集的前两个样本。
features[:2], poly_features[:2], labels[:2]输出:
(tensor([[-1.0613],
[-0.8386]]), tensor([[-1.0613, 1.1264, -1.1954],
[-0.8386, 0.7032, -0.5897]]), tensor([-6.8037, -1.7054]))
定义、训练和测试模型
# 我们先定义作图函数 semilogy ,其中 y轴使⽤了对数尺度
# 本函数已保存在d2lzh_pytorch包中⽅便以后使用
def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None,y2_vals=None,legend=None, figsize=(3.5, 2.5)):
d2l.set_figsize(figsize)
d2l.plt.xlabel(x_label)
d2l.plt.ylabel(y_label)
d2l.plt.semilogy(x_vals, y_vals)
if x2_vals and y2_vals:
d2l.plt.semilogy(x2_vals, y2_vals, linestyle=':')
d2l.plt.legend(legend)和线性回归⼀样,多项式函数拟合也使用平方损失函数。因为我们将尝试使⽤不同复杂度的模型来拟合生成的数据集,所以我们把模型定义部分放在 fit_and_plot 函数中。
num_epochs, loss = 100, torch.nn.MSELoss()
def fit_and_plot(train_features, test_features, train_labels,test_labels):
net = torch.nn.Linear(train_features.shape[-1], 1)
# 通过Linear⽂档可知,pytorch已经将参数初始化了,所以我们这里就不手动初始化了
batch_size = min(10, train_labels.shape[0])
# 定义数据集
dataset = torch.utils.data.TensorDataset(train_features,train_labels)
# 训练数据打乱
train_iter = torch.utils.data.DataLoader(dataset, batch_size,shuffle=True)
# 优化器 随机梯度下降SGD
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
# 损失函数 这里通过 view 函数将每张原始图像改成⻓度为 num_inputs 的向量。
l = loss(net(X), y.view(-1, 1))
# 梯度清零
optimizer.zero_grad()
# 反向传播
l.backward()
optimizer.step()
train_labels = train_labels.view(-1, 1)
test_labels = test_labels.view(-1, 1)
train_ls.append(loss(net(train_features),train_labels).item())
test_ls.append(loss(net(test_features),test_labels).item())
print('final epoch: train loss', train_ls[-1], 'test loss',test_ls[-1])
semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('weight:', net.weight.data,'\nbias:', net.bias.data) 三阶多项式函数拟合(正常)
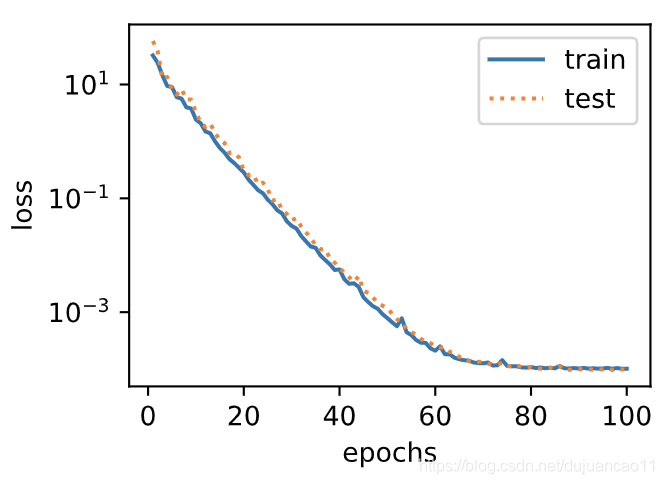
先使⽤与数据生成函数同阶的三阶多项式函数拟合。实验表明,这个模型的训练误差和在测试数据集的误差都较低。训练出的模型参数也接近真实值:![]()
fit_and_plot(poly_features[:n_train, :], poly_features[n_train:, :],labels[:n_train], labels[n_train:])输出:
final epoch: train loss 0.00010175639908993617 test loss 9.790256444830447e-05
weight: tensor([[ 1.1982, -3.3992, 5.6002]])
bias: tensor([5.0014])
线性函数拟合(欠拟合)
我们再试试线性函数拟合。很明显,该模型的训练误差在迭代早期下降后便很难继续降低。在完成最后一次迭代周期后,训练误差依旧很高。线性模型在⾮线性模型(如三阶多项式函数)⽣成的数据集上容易欠拟合。
fit_and_plot(features[:n_train, :], features[n_train:, :],labels[:n_train],labels[n_train:])输出:
final epoch: train loss 249.35157775878906 test loss 168.37705993652344
weight: tensor([[19.4123]])
bias: tensor([0.5805])

训练样本不足(过拟合)
事实上,即便使用与数据生成模型同阶的三阶多项式函数模型,如果训练样本不足,该模型依然容易过拟合。让我们只使⽤两个样本来训练模型。显然,训练样本过少了,甚⾄至少于模型参数的数量量。这使模型显得过于复杂,以⾄于容易被训练数据中的噪声影响。在迭代过程中,尽管训练误差较低,但是测试数据集上的误差却很高。这是典型的过拟合现象。
fit_and_plot(poly_features[0:2, :], poly_features[n_train:, :],labels[0:2],labels[n_train:])输出:
final epoch: train loss 1.198514699935913 test loss 166.037109375 weight: tensor([[1.4741, 2.1198, 2.5674]])
bias: tensor([3.1207])

小结
- 由于⽆法从训练误差估计泛化误差,⼀味地降低训练误差并不意味着泛化误差⼀定会降低。机器学习模型应关注降低泛化误差。
- 可以使用验证数据集来进⾏模型选择。
- 欠拟合指模型⽆法得到较低的训练误差,过拟合指模型的训练误差远小于它在测试数据集上的误差。
- 应选择复杂度合适的模型并避免使用过少的训练样本。