过拟合与欠拟合概念
之前,我们介绍过拟合的概念。拟合指的是构建的模型能够符合样本数据的特征。与拟合相关的两个概念是欠拟合与过拟合。
- 欠拟合:模型过于简单,未能充分捕获样本数据的特征。表现为模型在训练集上的效果不好。
- 过拟合:模型过于复杂,过分捕获样本数据的特征,从而将样本数据中一些特殊特征当成了共性特征。表现为模型在训练集上的效果非常好,但是在未知数据上的表现效果不好。
概念进一步解释
欠拟合
数据集里很多能影响到的因素没有考虑到。
eg. 房屋面积和房价,y_hat = wx + b可以说是欠拟合,有很多因素能影响房价,除了面积。
过拟合
如果每一个细节都纳入,每一个特征都不放过,不是训练起来很完美吗?
eg. 建筑年代,材料,楼层,考虑到很多因素,很可能需要100元线性回归。就算在训练集的表现很不错,但是太过于考虑训练集特征,导致很可能在测试集上表现的不好,过拟合就是太过于复杂,对特征过分依赖。
表现就是:训练集表现好,测试集不是那么好。
eg. 判断人的性别是男还是女?
举过拟合的例子,只要是有胡子,就是男人。这就是贻笑大方了。
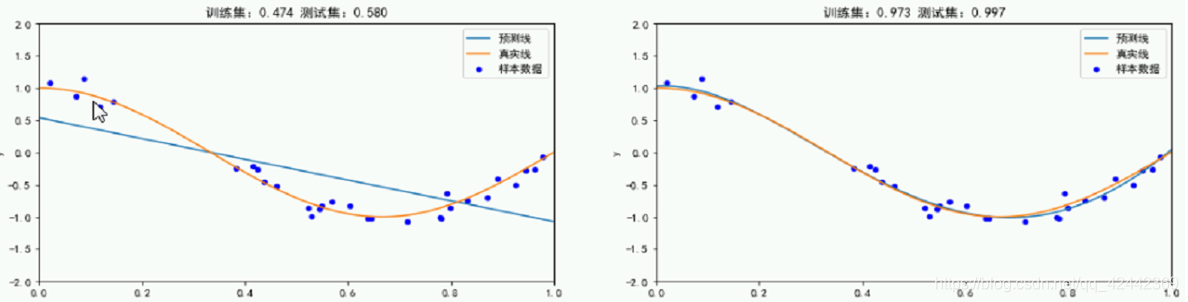
左图,欠拟合。
why 真实值和样本数据没有完全重合 ?
现实数据中,因为有噪声。
真实值是曲线,而用直线来进行预测,就是一种欠拟合。
看图,
只有0.474 效果并不是很好。
就像预测房屋价格,只考虑面积因素,就是欠拟合。
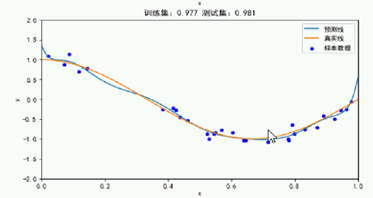
该图训练集和测试集都表示的不错。
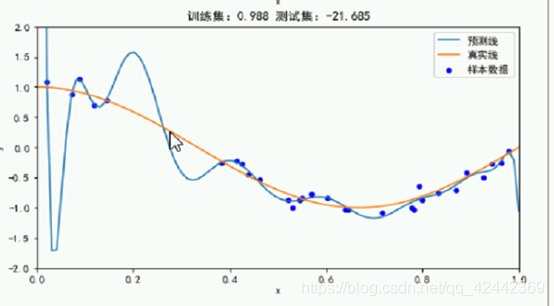
上图穿过去,趋势大, 在训练集上表现好,都传过去了。
但是在未知数据上表现不好, 测试集上,
都是负的了,和真实值差别大。
eg. 图像的话,抓的太详细了,穿过每个点;判断男女性别的话好像有个汗毛就是男的了。**why ?**因为训练集只是样本的一部分。
解决方案
如果产生欠拟合,可以采用如下方式,来达到更好的拟合效果。
- 增加迭代次数
- 增加模型复杂度(例如,引入新的特征)
- 通过多项式扩展
- 使用更复杂的模型(例如非线性模型)
如果产生过拟合,可以采用如下方式,来降低过拟合的程度。
- 收集更多的数据
- 正则化
- 降低模型的复杂度
- 减少迭代次数
- 选择简单的模型
现在,我们来介绍下多项式扩展与正则化。
并不是每一种方法都是有效,要去做实验,分别解释。
概念进一步解释
如果欠拟合,怎么解决?
eg. 走楼梯,100个台阶,50步,没达到极值点,误差还是比较大,欠拟合。

1. 增加迭代次数,就能达到
多次进行循环就能达到,而欠拟合,就是过于简单。
2. 增加模型复杂度
eg. 就像房价,用 y = wx + b
3. 多项式扩展
扩展到多维度;维度增加,拟合能力变强。
一个线变成曲线,变成平面。
eg. 以前是直的,现在可以打弯。
4. 更换模型
换个模型,找个其他的模型尝试。
eg. 线性模型处理不好的话,找个非线性的模型。
相比较增加复杂度,不换模型。
如果过拟合,怎么解决?
1. 数据收集
数据集分成4个部分,左上角的数据特别多,其他少。将其他部分的数据多收集些,再放到数据集中。这样就能捕获更多特征。
但是,现实中收集数据可能很麻烦。

2. 正则化
3. 降低模型的复杂度
看这个线的复杂度,咱们将多项式的阶数下降。
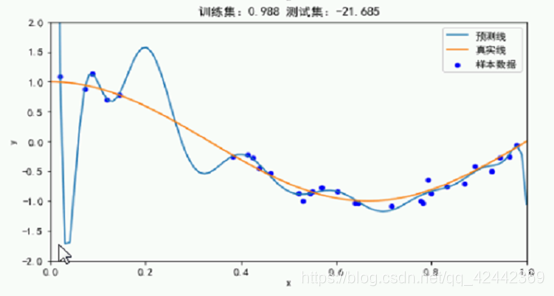
4. 减少迭代次数
迭代多了 过拟合
迭代少了 欠拟合