过拟合(over-fitting):
其实就是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测 试数据集中表现不佳。
举个例子:假设有一个看照片识别物种的模型,训练时,你把你的大量照片输入进去进行训练。然后测试时,当输入你的照片,无论什么姿势什么造型,模型都能准确识别,咦,这是个人。当你把好朋友的照片输进去,满心等待输出人时,结果很意外,输出的不是个人。这种情况下就是模型把你所有的特征都进行学习,测试别人时有特征偏差就得不到正确结果,差不多除了你之外就识别不出人来了。这就是缺乏泛化能力,模型出现过拟合。模型过拟合,虽然在训练集上表现得很好,但是在测试集中表现得恰好相反
欠拟合(under-fitting):
相对过拟合,欠拟合还是比较容易理解。还是拿刚才的模型来说,可能模型学习的特征较少,你输入一张猴子的照片,输出也是人。 这种情况下导致训练出来的模型不能很好地匹配
过拟合:在训练数据上表现良好,在未知数据上表现差。欠拟合:在训练数据和未知数据上表现都很差。
避免过拟合的方式:
early stop, 数据集的扩增,正则化,dropout
early stop: 在发生过拟合之前提前结束训练。理论上是可以的,但是这个点不好把握
数据集的扩增: 就是让模型见到更多的的情况, 可以最大化的满足全样本, 但实际应用中对于未来的事件预测却显得鞭长莫及正则化(regularization): 就是通过引入范数概念, 增强模型的范湖能力, 包括L1、l2(l2 regularization也叫weight decay)
dropout:是网络模型中的一种方法,每次训练时舍去一些节点来增强泛化能力。
下面主要介绍 正则化 和dropout
正则化(regularization):
就是在神经网络计算损失值的过程中,在损失之后再加一项。这样损失值所代表的输出与标准结果间的误差就会受到干扰,导致学习参数无法按照目标方向来调整,实现模型无法与样本完全拟合的结果,从而达到防止过拟合的效果。
那么如何加干扰项:1)当欠拟合时,希望他对模型误差的影响越小越好,以便让模型快速拟合实际
2)过拟合时,希望他对模型误差的影响越大越好,以便让模型不要产生过拟合的效果
由此引入了两个范数:
L1:所有学习参数w的绝对值的和
L2:所有学习参数w的平方和然后求平方根
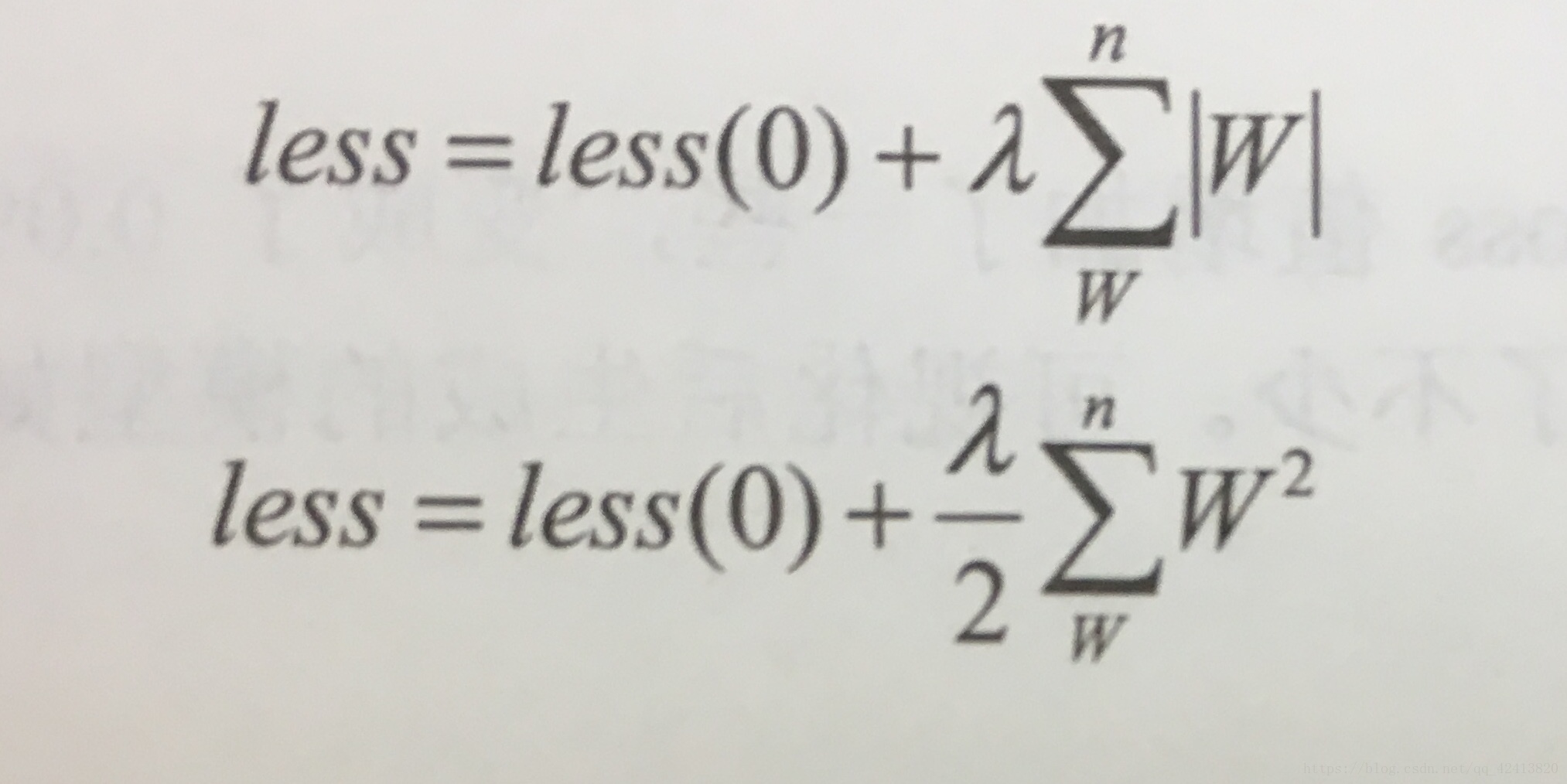
loss(0)代表真实的loss值,loss(0)后面的那一项就代表正则化了。入为一个可以调节的参数,用来控制正则化对loss的影响。
对于L2,将其乘以1/2是为了方向传播时对其求导正好可以将数据规整。
dropout:
dropout意思就是每次训练过程中,随机选择一部分节点不去学习。看一下这样做的原理:从样本数据来看,数据本身不可能是纯净的,即任何一个模型不能100%把数据完全分开,在某一类中一定会有一些异常的数据,过拟合的问题的问题恰恰是把这些异常数据当成规律来学习了,对于模型来说,我们希望他是有点'智商'的,把异常数据过滤掉,只关心有用的规律数据。异常数据的特点是,他与主流样本中的规律不同,但是量非常少,相当于在一个样本中出现的概率比主流数据出现的概率低的多。就利用这个特性,通过在每次模型中忽略一些节点的数据学习,将概率的异常数据获得的学习机会降低,这样这些数据对模型的影响就会更小了
tensorflow中的dropout的函数原型:
def dropout(x, keep_prob, noise_shape=None, seed=None, name=None)参数: x: 输入的模型节点 keep_prob:保持率。如果为1,则代表全部进行学习,如果为0.8,则代表丢弃0.2 noise_shape:代表指定的x中,哪些维度可以使用dropout技术,为None时,表示所有维度都是用dropout技术,也可以将某个 维度标志为1,来表示该维度使用dropout技术,例如shape为[n, len, w, ch],使用noise_shape为[n,1,1,ch],这表明 会对x中的第二维度len和第三维度w进行dropout seed:随机选取节点的过程中随机数的种子值 dropout改变了神经网络的网络结构,他仅仅是属于训练时的方法,所以一般在进行测试时要将keep_prob变为1