1 拟合
是指机器学习模型在训练的过程中,通过更新参数,使得模型不断契合可观测数据的过程
数据集:比萨饼直径和价格数据
通过线性回归模型,2次多项式回归模型,4次多项式回归模型的预测性能分析,来理解拟合过程;并针对所存在的问题,使用L1范数正则化,L2范数正则化进行改进后的性能测试。
2 实验代码及结果截图
#coding:utf-8
#比萨饼价格预测
#输入训练样本的特征及目标值
x_train=[[6],[8],[10],[14],[18]]
y_train=[[7],[9],[13],[17.5],[18]]
#导入线性回归模型
from sklearn.linear_model import LinearRegression
#初始化
regressor=LinearRegression()
#以比萨的直径作为特征训练模型
regressor.fit(x_train, y_train)
import numpy as np
#在X轴上0-25均匀采样100个数据点
xx=np.linspace(0,26,100)
xx=xx.reshape(xx.shape[0],1)
#预测回归直线
yy=regressor.predict(xx)
#输出线性回归模型在训练样本上的R-squared值
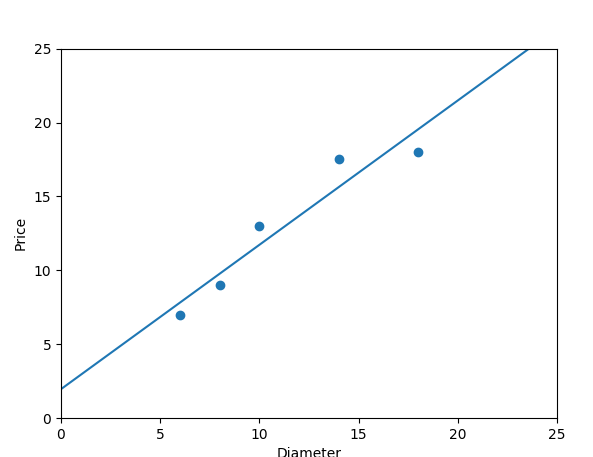
print '线性回归-R-squared:',regressor.score(x_train,y_train)
#回归直线作图
import matplotlib.pyplot as plt
plt.scatter(x_train, y_train)
plt1=plt.plot(xx,yy,label="Degree=1")
plt.axis([0,25,0,25])
plt.xlabel('Diameter')
plt.ylabel("Price")
plt.show()
#使用2次多项式回归模型在样本上进行拟合
#导入多项式特征产生器
from sklearn.preprocessing import PolynomialFeatures
#映射出2次多项式特征
poly2=PolynomialFeatures(degree=2)
x_train_poly2=poly2.fit_transform(x_train)
#初始化
regressor_poly2=LinearRegression()
#训练
regressor_poly2.fit(x_train_poly2, y_train)
#采样数据
xx_poly2=poly2.transform(xx)
#回归预测
yy_poly2=regressor_poly2.predict(xx_poly2)

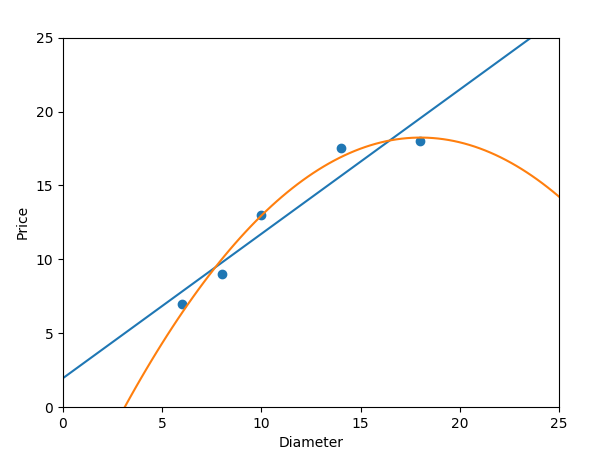
print '2次多项式回归-R-squared:',regressor_poly2.score(x_train_poly2,y_train)

#作图
plt.scatter(x_train, y_train)
plt1=plt.plot(xx,yy,label='Degree=1')
plt2=plt.plot(xx,yy_poly2,label='Degree=2')
plt.axis([0,25,0,25])
plt.xlabel('Diameter')
plt.ylabel('Price')
plt.show()
#使用4次多项式回归模型进行拟合
poly4=PolynomialFeatures(degree=4)
x_train_poly4=poly4.fit_transform(x_train)
#初始化
regressor_poly4=LinearRegression()
#训练
regressor_poly4.fit(x_train_poly4, y_train)
#采样数据
xx_poly4=poly4.transform(xx)
#回归预测
yy_poly4=regressor_poly4.predict(xx_poly4)
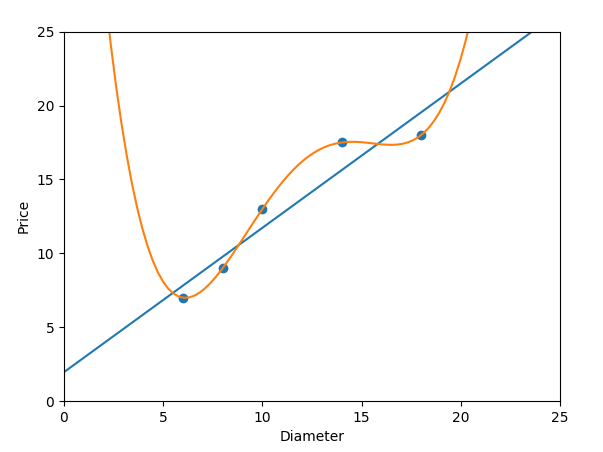
print '4次多项式回归-R-squared:',regressor_poly4.score(x_train_poly4,y_train)


#作图
plt.scatter(x_train, y_train)
plt1=plt.plot(xx,yy,label='Degree=1')
plt4=plt.plot(xx,yy_poly4,label='Degree=4')
plt.axis([0,25,0,25])
plt.xlabel('Diameter')
plt.ylabel('Price')
plt.show()
print '×××××××三种回归模型的性能评价×××××××××'
#评价3种回归模型的性能
x_test=[[6],[8],[11],[16]]
y_test=[[8],[12],[15],[18]]
#线性回归模型的分析
print '线性回归模型:',regressor.score(x_test,y_test)
#2次多项式回归模型
x_test_poly2=poly2.transform(x_test)
print '2次多项式回归模型:',regressor_poly2.score(x_test_poly2,y_test)
#4次多项式回归模型
x_test_poly4=poly4.transform(x_test)
print '4次多项式回归模型:',regressor_poly4.score(x_test_poly4,y_test)
#L1范数正则化:正则化的目的在于提高模型在未知测试数据上的泛化力,避免参数过拟合
"""正则化常见的方法是在原模型优化目标的基础上,增加对参数的惩罚项"""
#Lasso:让有效特征变得稀疏;使用四次多项式特征验证Lasso模型的性能和参数
from sklearn.linear_model import Lasso
#初始化
lasso_poly4=Lasso()
#进行拟合
lasso_poly4.fit(x_train_poly4, y_train)
#评估
print 'Lasso-4次多项式回归模型:',lasso_poly4.score(x_test_poly4,y_test)
#输出Lasso模型的参数列表
print lasso_poly4.coef_
#比较
print '普通4次多项式回归模型:',regressor_poly4.score(x_test_poly4,y_test)
print regressor_poly4.coef_
#L2范数正则化:在原优化目标的基础上,增加了参数向量的L2范数的惩罚项
#Ridge:压制参数之间差异的L2正则化模型
#输出普通4次多项式回归模型采纳数的平方和,验证参数之间的巨大差异
print '普通4次多项式回归模型参数的平方和:',np.sum(regressor_poly4.coef_**2)
from sklearn.linear_model import Ridge
#初始化
ridge_poly4=Ridge()
#进行拟合
ridge_poly4.fit(x_train_poly4, y_train)
#性能
print 'Ridge-4次多项式回归模型:',regressor_poly4.score(x_test_poly4,y_test)
print ridge_poly4.coef_
print '拟合后参数的平方和:',np.sum(ridge_poly4.coef_**2)