Hierarchical Attention Networks for Document Classification 模型理解篇
本文借鉴了大神的博客,链接:https://blog.csdn.net/liuchonge/article/details/73610734
最近看了HAN用在文本分类的这篇文章。提出的模型使用了分层的注意力机制,对应了文本在字词和句子两个层面的结构。也就是分别在字词层面和句子层面使用注意力机制。这样做的好处有两个:1.模型可以给与不同主要性的字词或者句子不同的关注度,最终的任务效果因此会更好。2.注意力机制的可视化可以帮助我们更好的解释模型。
模型结构
下面是这篇文章提出的模型结构:

我们结合这张图对模型进行讲解。
模型分为4部分:Word encoder, Word attention, sentence encoder 以及 sentence attention
在Word encoder部分,使用双向的GRU对embedding后的句子进行编码,得到编码向量
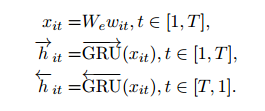
在Word attention部分,首先使用一个单层的MLP对编码向量
得到一个隐层向量
,然后用这个隐层向量经过softmax得到权重alpha,最终一个句子的表示就是权重alpha与编码向量
的和,也就是
,他的维度与编码向量一致。另外,在进行softmax时使用的上下文向量
随机初始化,并且在驯良过程中不断改变。
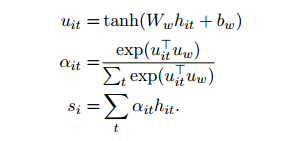
sentence encoder 和 sentence attention与上面提到的两层本质一样,只不过将单词换成了句子,直接上公式,不多做解释了。
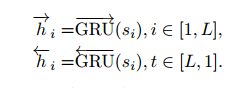
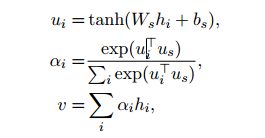
实验结果分析
为了分析注意力机制模型的效果,文章选取了两个单词的例子,good和bad在影评句子中的所占权重。如图下图所示

上图是对于单词“good”的权重分布情况,其中(a)是总体的分布情况,(b)-(f)分别是在由差评逐渐到好评的过度的过程中“good”的权重的变化情况。从图中可以看出,随着好评程度的不断上升,“good”所获得的权重越大,这说明,网络能够自动的将“注意力”放在和好评更相关的词汇上。

作者同样对单词“bad”做了测试,测试结果如上图所示。显示出了和前一张一样的实验结果,即网络会在差评的时候更加将“注意力”放在“bad”词汇上。
可视化
为了进一步说明的注意力机制的作用,同时方便模型解释。作者对attention下的单词和句子权重做了可视化,如下图

其中,蓝色颜色越深说明单词在句子中的权重越大,粉色颜色越深说明句子文本中的权重越大。可以看出,对整体语义贡更大的单词或者句子有更高的权重。
好了,对这篇文章的模型介绍就到这里。下一篇blog我们将对代码的实现进行讲解。