因为最近在做的chatbot实验效果不太好,总是会出现一些没有营养的回复,如我不知道等等。所以查了一些资料,发现李纪为大神的篇文章是提供了处理这个问题的方法,所以借鉴了一下,顺便写一下博客记录。
文章主要的贡献是使用了最大互信息MMI代替常用的最大后验概率MLE等作为目标函数。MLE这个目标函数最常用在机器翻译任务上,最大的优势在于可以产生最自然的语言,但是多样性不好。对话任务和翻译任务还是有区别的,对话任务的回复往往是开放性的,选择范围更广,这样是用MLE很容易在最高票上产生“我不知道”这种安全并且符合语法的回复。尽管使用MLE在decoding昌盛的大量的N-best list的话,也是有很多不错的回复,但都排名很靠后。
作者认为产生这种结果的原因在于,我们只考虑了输入对输出的影响,但是没有考虑输出对输入的影响,所以选择了使用MMI这个目标函数作为优化对象。
MMI指标
先看一下标准的seq2seq目标函数是对数似然函数,如下:
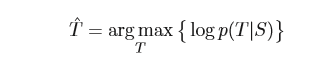
S是输入源语句,T是输出target语句。目标就是最大化两者之间的对数似然函数。
对于互信息:

上式进行简单的推导,可以化为:
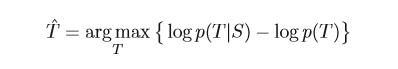
p(T)其实是一个语言模型,为了在目标中控制reply的多样性,添加一个惩罚系数lambda,上式转化为下式:
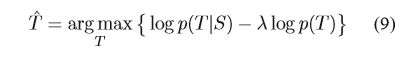
然后利用贝叶斯公式:
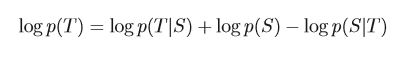
将(10)化为:
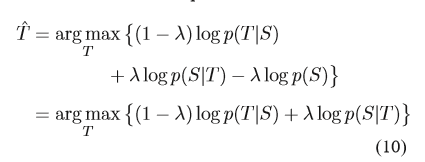
从这个式子我们来看,MMI实际上是在给出S得出T和给出T得到S之间做权衡取舍。
对应式子(9)和(10)训练两种模型,分别是MMI-antiLM和MMI-bidi。下面的章节我们会介绍这两个模型以及如何实现。