PNAS
这篇文章还是出自Google,进一步改善之前发表在AAAI2019的论文《Regularized Evolution for Image Classifier Architecture Search](http://128.84.4.27/abs/1802.01548)》里所提出的方法的搜索速度,而这篇文章则发表在了ECCV 2018。原文可见Progressive Neural Architecture Search。
摘要
这篇文章提出了一种新的学习CNN架构的方法,比最近基于强化学习和进化算法的SOTA的方法更高效。本文的方法使用了基于序列模型的优化(SMBO)策略,在该策略中,按照增加复杂性的顺序搜索结构,同时学习代理模型以引导结构空间搜索。在相同搜索空间下的直接比较表明,就评估的模型数量而言,本文提出的方法的效率比之前NASNet用到的RL方法高5倍,而就总计算而言则高了8倍。然后搜索到的结构在CIFAR-10和ImageNet上也达到了SOTA的分类精度。
1. 引言
目前NAS所采用的技术通常分为两类:进化算法或强化学习。当使用进化算法(EA)时,每个神经网络结构被编码为一个字符串,在搜索过程中执行字符串的随机突变和重组;然后在验证集上对每个字符串(模型)进行训练和评估,表现最好的模型生成子模型。当使用强化学习(RL)时,代理执行一系列动作,这些动作指定了模型的结构;然后对该模型进行训练,并将其在验证集上的性能作为奖励返回,用于更新RNN控制器。尽管EA和RL方法都能够学习优于手动设计的体系结构的网络结构,但它们需要大量的计算资源。 例如,NASNet中的RL方法用了4天训练和评估了500个P100 GPU上的20,000个神经网络。
本文提出的方法能够学习一个CNN,其在准确性方面与先前的SOTA相匹配,而在架构搜索期间需要的模型评估要少5倍。这篇论文的出发点是NASNet中提出的结构化搜索空间,其中搜索算法的任务是搜索一个好的卷积cell,而不是一个完整的CNN。一个cell包含B个块,其中一个块是应用于两个输入(张量)的组合运算符(例如相加),每个输入(张量)可以在组合之前进行变换(例如使用卷积)。然后,根据训练集的大小和最终CNN所需的运行时间,将这个cell结构堆叠一定次数。这种模块化设计也允许我们轻松地将架构从一个数据集迁移到另一个数据集。
作者建议使用启发式搜索来搜索cell结构空间,从简单(浅层)模型开始,逐步发展到复杂模型,在搜索过程中剪除不可靠的结构。在算法的迭代b处,有一组K个候选cell(每个的大小为b个块),它们在感兴趣的数据集上进行训练和评估。由于此过程很昂贵,因此这里还学习了一个模型或代理函数,用于预测一个结构的性能而无需对其进行训练。然后将大小为b的K个候选扩展为大小为b + 1的 个child。接着应用代理函数对所有 个孩子进行排名,选择前K个,然后对其进行训练和评估。以这种方式继续进行直到b = B,这是要在cell中使用的最大块数。
本文的渐进式(简单到复杂)方法比直接在完全特定的结构空间中进行搜索的其他技术具有多个优势。首先,简单的结构训练速度更快,因此可以快速得到一些初步结果来训练代理。 其次,只要求代理预测与所看到的结构稍有不同(较大)的结构的质量(参见信任区域方法)。 第三,将搜索空间分解为更小的搜索空间的乘积,从而使得可以潜在地搜索具有更多块的模型。在评估的模型数量方面,本文的方法比NASNet的RL方法效率高5倍,而在总计算方面则是8倍。另外本文发现的结构在CIFAR-10和ImageNet上达到了SOTA的分类精度。
2. 相关工作
- 强化学习、RNN、NASNet的结构化搜索空间和PPO
- Q-Learning、策略梯度、网络态射、参数共享
- 进化算法(最近的方法仅使用EA搜索结构,然后使用SGD估计参数)
- 启发式搜索(从简单到复杂的渐进式搜索)
- 蒙特卡罗树搜索(MCTS)
- 基于序列模型的优化(SMBO)
- 代理函数
3. 架构搜索空间
这篇文章使用的神经网络结构搜索空间还是建立在NASNet中提出的分层方法的基础上,即首先学习一个cell结构,然后将这个cell堆叠所需的次数,以创建最终CNN。
3.1 cell拓扑
实际一个cell就是一个完全卷积的网络,它将一个 张量映射到另一个 张量(自然stride=1时 、 、 与 、 、 就是一样的,stride=2时则有 、 、 )。
cell可以由由B个块组成的DAG(有向无环图)表示,每个块是从2个输入张量到1个输出张量的映射。可以将一个cell中的块b指定为5元组 ,其中 指定块的输入, 指定应用于输入 的操作, 指定如何将 和 组合以生成与该块输出相对应的特征图(张量),用 表示。可能的输入的集合 是这个cell中所有先前块的集合 ,加上先前cell的输出 ,加上更先前单元的输出 。算子空间 是以下8个函数的集合(比NASNet的少是因为去掉了一些没用到的函数),每个函数对一个张量进行运算:

至于可能的组合运算符 的空间,NASNet中同时考虑了元素级相加(elementwise addition)和级联(concatenation)。但因为NASNet的结果中并没有使用到级联,所以为了减少搜索空间,总是使用加法作为组合运算符。也就是说一个块可以减少为用一个4元组表示。
让第b个块的可能结构的空间为 ;其大小 ,其中 , 和 。对于b=1,有 ,这是前两个cell的 最终输出,因此有 个可能的块结构。如果允许最多 个块的cell,那么cell结构的总数由 给出。但是,此空间存在一定的对称性,可将其修剪到更合理的大小。事实上cell的总数约为 。这比NASNet中使用的搜索空间( )小得多,但是它仍然是一个非常大的搜索空间,需要高效的优化方法。
3.2 从cell到CNN
要评估一个cell需要将其转换为CNN。 为此使用stride=1或stride=2堆叠预定数量的基本cell(具有相同的结构,但未固定权重),如图1(右)所示。然后相应地调整stride=2的cell之间的stride=1的cell的数量,最多重复N次。 在网络的顶部使用全局平均池,然后使用softmax分类层。 然后在数据集上训练堆叠模型。
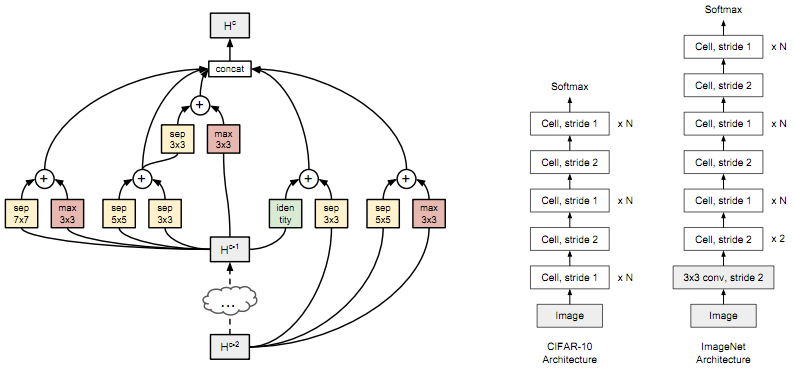
CNN的整体构建过程与NASNet相同,只是这里只使用一种cell类型(不区分Normal Cell和Reduction Cell,而是通过使用stride为2的Normal Cell来模拟Reduction Cell),cell搜索空间稍小(因为使用较少的算子和合并操作)。
4. 方法
4.1 渐进式神经结构搜索
许多先前的方法直接在完整cell或更糟糕的是完整的CNN的空间中搜索。但作者认为,在指数级的大搜索空间中直接搜索是困难的,特别是在一开始并不知道什么是好模型的时候。因此作者建议按先搜索最简单模型的递进顺序搜索空间。首先从 开始构造所有可能的cell结构(即由1个块组成),然后将它们添加到队列中。接着训练并评估队列中的所有模型(并行方式),然后通过添加 中所有可能的块结构来扩展每个模型;这生成了一组 个深度为2的候选cell。因为负担不起训练和评估所有这些子网络的代价,所以这里用了一个学习到的预测函数(根据迄今为止访问过的cell的性能对其训练,且其训练和应用所需的时间可以忽略不计)。然后使用这个预测函数来评估所有候选cell,并选择K个最有希望的cell。将它们添加到队列中,并重复该过程,直到找到具有足够数量的块(B个)的cell。伪代码参见算法1,图2是一个示例。

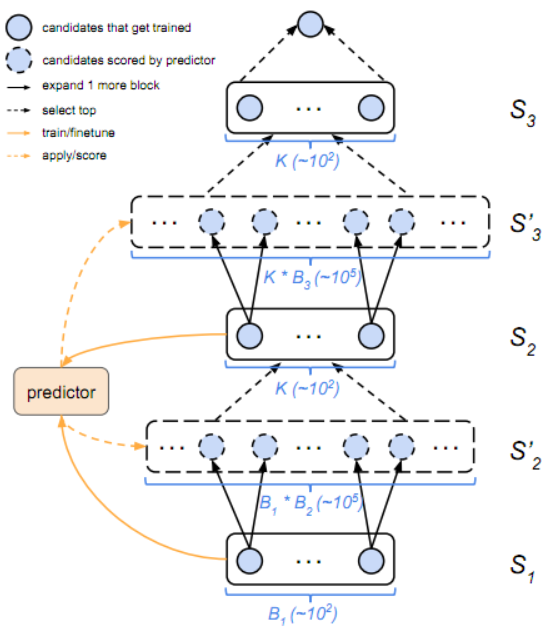
4.2 基于代理模型的性能预测
如上所述需要一种机制来预测cell的最终性能,然后才能真正训练它。这种预测器至少有三个期望的特性:
- 处理可变大小的输入:即需要预测器来处理可变长度的输入字符串。特别是,它应该能够预测任何具有b+1个块的cell的性能,即使它只在具有最多b个块的cell上训练过。
- 与真实性能相关:事实上不一定要求低MSE,只需要预测器按照与真实性能值大致相同的顺序排列模型即可。
- 样本效率:希望训练和评估尽可能少的cell,这意味着预测器的训练数据将是稀缺的。
要求预测器能够立即处理可变大小的字符串,RNN就可以。这里作者使用了LSTM读取长度为4b的序列(表示每个块的 、 、 和 ),每个步骤的输入是大小为 或 的一个one-hot向量,然后是嵌入查找(embedding lookup)。对tokens 使用维度D的共享嵌入,而对 使用另一个共享嵌入。最终的LSTM隐藏状态通过一个全连接层和sigmoid来回归验证精度。作者还尝试了一个更简单的MLP基线,如下所示将cell转换为一个固定长度的向量:将每个token嵌入到一个D维向量中,concat每个块的嵌入以获得一个4D维的向量,然后对块进行平均。
训练预测器时,一种方法是使用新的数据,通过几步SGD来更新预测器的参数。 但是,由于样本量很小,因此作者将5个预测器合为一组,每个预测器(从头开始)拟合搜索过程每一步可用数据的4/5。作者声称这减少了预测的方差。最后作者认为未来可以研究其他类型的预测器,例如具有字符串核的高斯过程,这可能可以更有效地训练和产生具有不确定性估计的预测。
5. 实验和结果
5.1 实验细节
实验设置包括训练策略基本还是跟NASNet一样。
5.2 代理预测器的性能
在PNAS的步骤b中,训练预测器关于观察到的具有最多b个块的cell的性能,但这里将其应用于具有b + 1个块的cell。因此,对于具有以前见过的大小(但尚未经过训练)的cell以及比训练数据大一个块的cell,这里都考虑了预测精度。
更准确地说,让 是一组随机选择的具有b个块的单元,其中 。将每一个转换为CNN后再训练 个epoch(因此总共训练了20个epoch的约 个模型)。现在使用这个随机数据集,使用算法2中的伪代码来评估预测器的性能,其中 返回某个集合 中模型的真实验证集精度。特别是,对于每个大小 和每个试验 (使用 ),做如下操作:从 中随机选择 个模型(每个的大小为b)以生成训练集 ;在训练集上拟合预测器;在训练集上评估预测器;最后,在所有大小为b+1的未观测随机模型集合上评估预测器。

图3的第一行显示了训练集中模型的真实精度 与预测精度 的散点图。最下一行绘制了较大模型集的真实准确度 与预测准确度 。可以发现预测器在训练集的模型上表现良好,但在预测较大模型时表现不太好。然而,随着预测器在更多(和更大)的cell上训练,性能确实会提高。
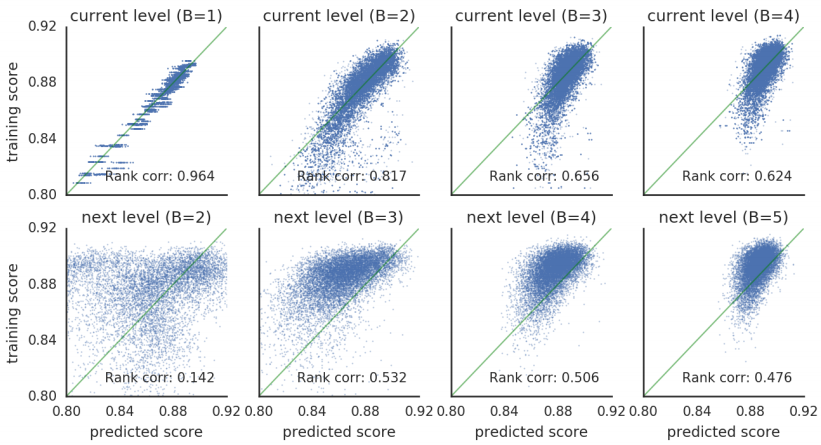
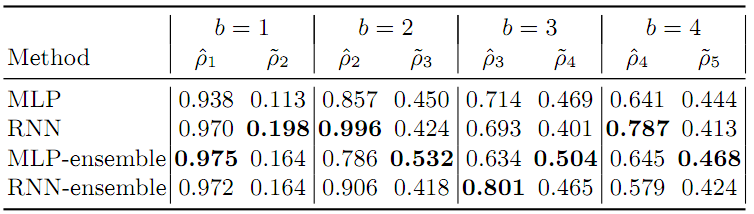
可以用Spearman秩相关系数来总结图3中的每个散点图。令 以及 。表1汇总了不同级别的这些统计信息。可以看到,对于预测训练集,RNN比MLP做得更好,但是对于预测未观测的较大模型(这是实际上所关心的)的性能,MLP似乎做得稍微好一些。同时也可以看到对于外推任务,ensembling似乎有帮助。
5.3 搜索效率
主要就是跟另外两个方法:随机搜索和NAS比较,如图4所示。可以看到随着搜索更大的模型,最好的 个模型的平均性能稳步提高。此外,当使用MLP-ensemble(如图4所示)而不是RNN-ensemble(见补充图1)时,性能更好,这与表1一致。与随机搜索相比,PNAS明显更优。至于NAS,其平均性能稳步提高,但速度比PNAS慢。
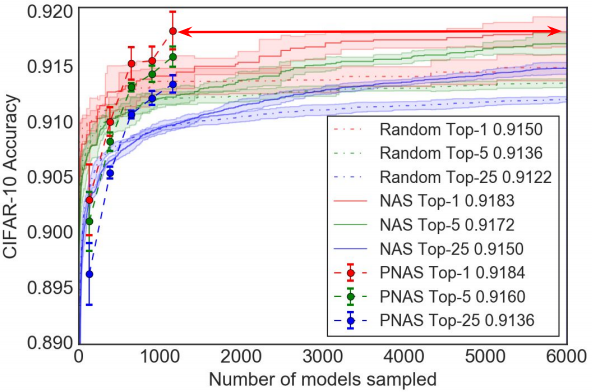
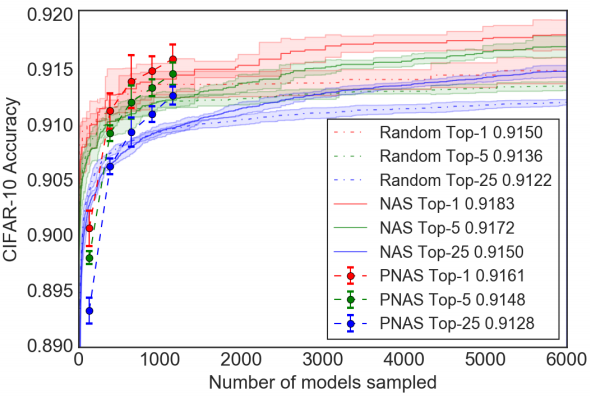
为了量化与NAS相比的加速因子,作者又计算了使得PNAS和NAS的平均性能相等所需要的训练和评估的模型数量。结果如表2所示。可以看到PNAS在训练和评估的模型数量方面比NAS快了最多5倍。

比较架构搜索期间探索的模型数量是衡量效率的一个指标。然而,如NAS的一些方法使用一个二次重排序阶段来确定最佳模型;PNAS不执行重排序阶段,而是直接使用来自搜索的最好模型。因此,更公平的比较是计算整个搜索过程中通过SGD处理的样本总数。设 为搜索期间训练的模型数, 为用于训练每个模型的样本数,则总样本数为 。然而,对于具有额外重新排序阶段的方法,在返回最佳值之前,将使用 个样本对搜索过程中排名靠前的 个模型进行训练,因此总成本为 。在PNAS和NAS中,为达到相同的top-1精度而搜索的模型数量分别为 和 。在第二阶段,NAS在挑选最佳模型之前,先对 的最好模型进行 个epoch的训练。因此,考虑到总成本,PNAS的速度大约是NAS的8倍。
5.4 CIFAR-10图像分类任务上的结果
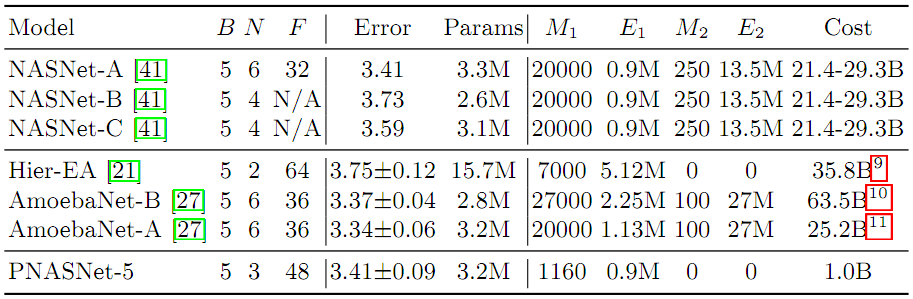
让PNASNet-5表示使用PNAS在CIFAR上发现的最好的CNN,如图1(左)所示。结果如表3所示。可以看到PNAS可以找到一个与NAS同样精确的模型,但是使用的计算量要少21倍。PNAS的性能也优于层次EA方法,同时使用的计算量减少了36倍。尽管“AmoebaNets”的EA方法目前具有最高的精确度,但它也需要最多的计算,占用的资源是PNAS的63倍。但是,由于这些方法在不同的空间中进行搜索,因此必须对这些结果的比较只能半信半疑。
5.5 ImageNet图像分类任务上的结果
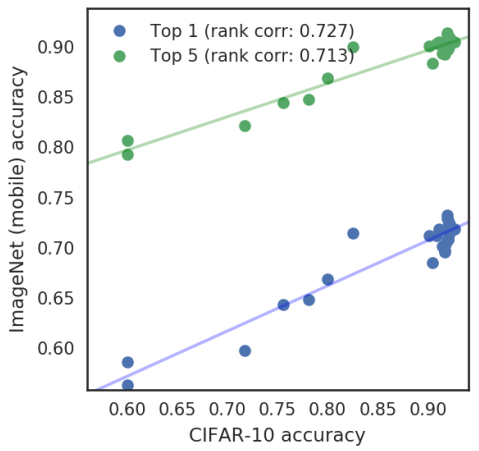
实验表明,CIFAR精度和ImageNet精度是强相关的( ,如附图4所示,证明使用CIFAR-10精度作为ImageNet精度的快速代理来搜索模型是合理的)。
这里和其他模型的比较是在以下两种情况进行的:
- Mobile:这里限制CNN的表征能力。输入图像大小为 ,乘法加法运算次数小于600M。
- Large:这里将PNASNet-5与ImageNet上的SOTA模型进行比较。输入图像大小为 。
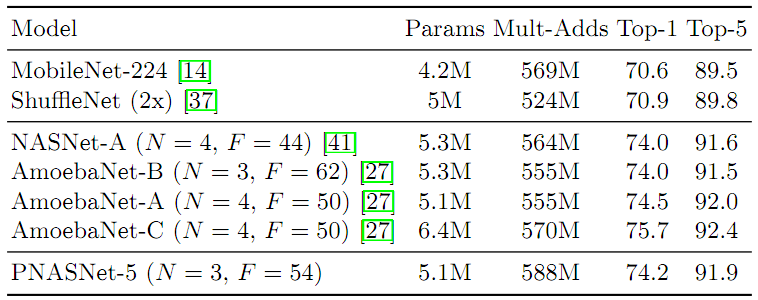
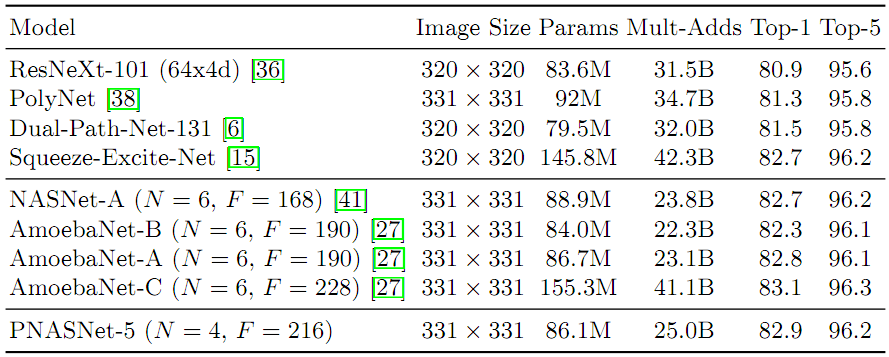
表4总结了Mobile的结果。PNASNet-5的性能略优于NASNet-A,而且这两种方法也都大大超过了先前的SOTA,包括人工设计的MobileNet和ShuffleNet。AmoebaNet-C表现最佳,但需要注意的是这是与表现最佳的CIFAR-10模型不同的模型。表5显示,在Large的情况下,PNASNet-5比以前的SOTA(包括相同模型容量下的SENet、NASNet-A和AmoebaNets)获得更高的性能。
6. 讨论及未来工作
这项工作的主要贡献是展示如何通过在越来越复杂的图形空间中使用渐进式搜索,结合学习的预测函数,有效地识别出最有希望探索的模型,从而加快搜索良好CNN结构的速度。所得到的模型与之前的工作达到了相同的性能水平,但计算成本很小。
未来的工作有很多可能的方向,包括:
- 使用更好的代理预测器,例如带字符串核的高斯过程
- 使用基于模型的早停,这样就可以在到达 个epoch之前停止“无希望”模型的训练
- 使用“温启动”,从较小的父模型初始化较大的b+1大小的模型的训练
- 使用贝叶斯优化,其中使用一个获取函数,例如预期改进或上置信界,对候选模型进行排序,而不是贪婪地选择前K个
- 自适应地改变在每个步骤中评估的模型的数量K(例如,随着时间的推移减少)
- 速度-精度权衡的自动探索
个人看法
本文的PNAS还是基于前一篇的NASNet,然后速度上的改进主要基于两点,一点是搜索方法的改进即PNAS以及缩小搜索空间,另一点是利用了一个预测器对模型的精度进行预测,从而免去大量用于训练模型的时间。不过,还是需要大约225个GPU days,依旧劝退平民玩家。。。接下来会开始讲一些平民化的NAS了。
