摘要
情感是人类固有的,因此,情感理解是人工智能(AI)的关键部分。对话中的情感识别(ERC)作为自然语言处理(NLP)的新研究前沿正变得越来越受欢迎,这是由于它具有从Facebook,Youtube,Reddit,Twitter等平台上大量公开可用的对话数据中挖掘舆情的能力。此外,它在医疗保健系统(心理分析诊断工具),教育(了解学生的挫败感)等方面具有潜在的应用。此外,ERC对于生成需要了解用户情绪的情绪感知对话也非常重要。满足这些需求需要有效且可扩展的会话式情感识别算法。然而,ERC是当前较难解决的问题,面临着研究上的挑战。在本文中,我们讨论了这些挑战,并为该领域的最新研究提供了启示。我们还将描述这些方法的缺点,并讨论它们未能成功克服ERC中的研究挑战的原因。
简介
与普通的句子/话语情感识别不同,ERC在理想情况下需要对单个话语进行上下文建模。相比较之前的工作,不管是基于词汇的方法还是建模的深度学习方法,都很难在ERC数据集上有好的表现,因为这些工作忽略了对话的特定因素 ,比如上下文线索、说话人说话的时间性、说话人特定信息。
研究挑战
情绪的类别
情绪被定义为两种模型:分类模型和维度模型。分类模型是将情绪分为离散的几个类别,而维度模型是将情绪看做连续空间的一个点。
情绪标注基础
要做到独立于标注者视角,客观地情绪标注,是很有挑战的事情。让说话人自我评价似乎是最好的方法,然而这不可行,因为对无脚本的对话进行实时标记将影响对话流。对话后的自我标注看似可行,但目前没人做过。因此,许多ERC数据集由一群不参与脚本和对话的人编写脚本并添加注释。标注时,上下文会作为先验知识给到标注者。标注者须站在发言人的处境下做标注。
对话上下文建模
对话中的情绪动态变化由两方面组成:自我依赖和人际依赖。自我依赖,也被称为情感惯性,处理的是说话人在谈话中对自己产生的情感方面的影响。另一方面,人际依赖性与对方诱导说话者的情感影响有关。相反,在对话过程中,说话者也倾向于模仿对方来建立融洽的关系。
对对话中句子的上下文进行建模,是这个研究领域很活跃的问题。记忆网络(Memory Networks)、RNNs和注意力机制已经在以前的工作中被使用,例如HRLCE或DialogueRNN,来从上下文中获取信息。
说话者特定建模
每个个体表达情感的方式是微妙的。比如有些人善用讽刺,在讽刺时表达的意思可能和字面完全不同。例如Pa : ‘The order has been cancelled.’, Pb : ‘This is great!’。这句话如果是讽刺就得反着理解。在背景信息不足的情况下,如果能根据之前的发言对说话者性格建模,通常能提升表现。
倾听者特定建模
对话过程中,倾听者对说话者的言语会做出判断。然而,说话人说话时,倾听者的反应是没有文本记录的。一个模型必须借助于视觉模态来模拟听者的面部表情,以捕捉听者的反应。然而,根据DialogueRNN,捕捉倾听者反应并没有带来提升,因为倾听者后来的话表明了他的反馈。此外,当听者在谈话中从不说话时,他/她的反应仍然是无关紧要的。尽管如此,对倾听者建模在必须对情绪每个瞬间中仅需持续识别是很有用的,例如政治演讲中的听众反应,而不是对每个话语的情感识别。
情绪转移现象
由于情绪惯性,谈话中的参与者倾向于保持一种特定的情绪状态,除非一些外部刺激(通常是其他参与者)引起了改变。
当前ERC模型很难好好解决这个问题,DialogueRNN对相似情绪的转变(有愤怒到悲伤)建模更准确。为了解决这一问题,可以提出一个检测情绪转移的新问题:
1)基于历史对话和当前语句,判断是否发生情绪的转移?(二分类)
2)如果发生转移,那么新情绪是什么?
作为baseline,CRF条件随机场是吸引人的方法,因为其可以对模型标签建模。
细粒度情感识别
细粒度情绪识别旨在识别显性和隐性表达的情绪。它旨在对对话主题、说话者意见和观点进行更深入的理解。图6举了一个例子。普通的情绪识别器不可能理解双方在政府法案方面的积极情绪。只有通过解读第二个人对反对法案的不满,分类者才能推断出第二个人对法案的支持。另外,即使第一个人没有直接表明对法案的支持,从对话中也应当能看出来。
多方对话
通常,多方对话中的情绪识别难度更大,因为难以跟踪单个说话者的状态和处理共同引用。
讽刺现象
讽刺是一种用于表达轻蔑的语言工具。不能检测讽刺的ERC系统大多不能准确预测讽刺话语的情感。讽刺的本质也依赖于人,这再次证明了说话人在对话中的侧写。
情绪推理
对于可解释的AI系统来说,推理能力是很重要的。在ERC的语境中,人们通常希望理解说话人表达情感的原因。读者不应该把情感推理和上下文建模混为一谈,我们在本节前面已经讨论过了。与语境建模不同,情感推理不仅发现会话历史中触发话语情感的语境话语,而且构建了这些语境话语对目标话语的函数。
情感推理很难定义一个分类或标记集。目前还没有包含如此丰富注解的数据集。构建这样的数据集将使未来的对话系统能够构建有意义的论证逻辑和话语结构,向类人对话又迈进了一步。
数据集

这些数据集都不能用于情感推理,因为它们缺少推理任务所需的必要注释细节。读者还应该注意,所有这些数据集都不包含细粒度和主题级别的情感注释。
前沿方法
句子的情绪取决于以下三个因素:
1)这个句子以及他的上下文,包括说话者之前的句子、说话恩意图和对话的主题
2)说话者状态,比如个性和辩论逻辑
3)前一个句子的情感表达。
虽然IEMOCAP和SEMAINE在近十年前就已经开发出来了,但是大多数使用这两个数据集的工作并没有考虑到上述因素。
CMN,由Hazarika提出的对话记忆网络,是第一个将每个说话人的特定上下文的记忆利用起来的ERC方法。之后,Hazarika用ICON(交互的对话记忆网络)改进了这个方法。这两种方法实际上都在分类时发掘目标句子的说话人信息。这使得模型对特定说话者的细微差别视而不见。
DialogueRNN旨在关注说话人信息,对自我和人际间的情绪影响分层级多阶段地结合attention机制RNN建模。在IEMOCAP和SEMAINE上,DialogueRNN都比前两个模型表现更好。
掌握说话者内在依赖联系的观点在ERC研究中也颇受认可,量子理论和LSTM也被用于建模。Quantum-Inspired Interactive Networks(QIN)在IEMOCAP和MELD上超越了CMN和ICON。最近Yeh等人提出一种ERC模型,叫做交互感知的注意力网络(IANN),其通过利用内在说话者关系建模。与ICON和CMN类似,IANN利用了每个说话者的独立的记忆。见图8 :
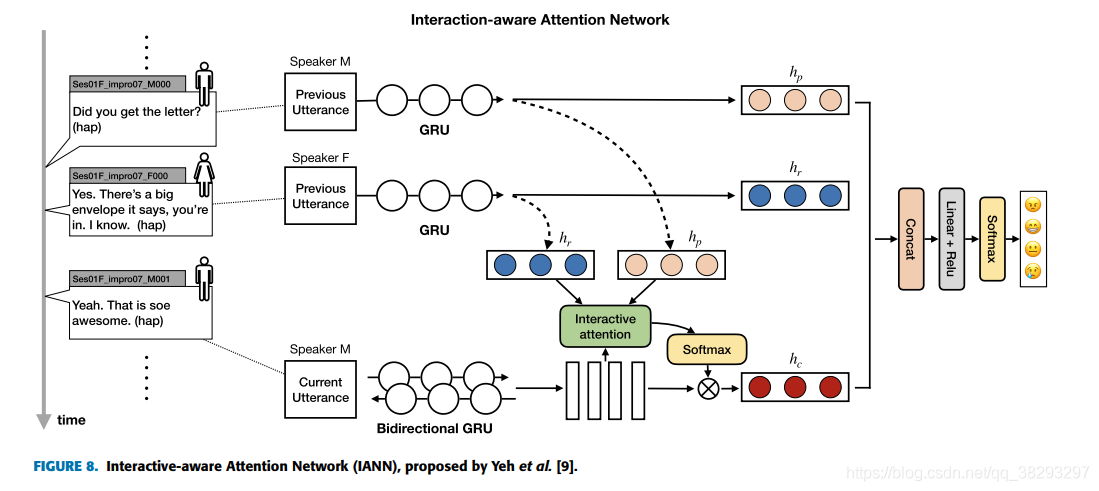
所有以上模型就证实了,对自我和人际间影响建模的上下文历史对ERC任务有用。此外,DialogueRNN表明邻近的句子富含更多上下文信息,以及如果未来的句子可以用的话,也能带来效果提升。
同时,远距离句子更少被用到。此外,CMN和ICON没有用到未来的句子作为上下文。然而,对于实时应用,系统不能依赖于未来的话语。在这种情况下,使用固定上下文窗口的CMN、图标和对话框是合适的。
这些网络,如CMN、ICON、IANN、DialogueRNN等,在情感转移的话语表达上表现较差。特别是目标语的情感与前一种话语不同的情况,DialogueRNN只能正确预测47.5%的实例。相比之下,在没有情绪变化的区域,它的成功率为69.2%。
在这三个方法中,只有DialogueRNN能够大范围上处理多方对话。只是表现不比bc-LSTM要好很多。由于会话中话语的顺序性,在上述模型中使用了RNNs来生成上下文。然而,由于基于rnnn的上下文表示方法在获取远距离上下文信息方面表现较差,因此仍有很大的改进空间。
Emotion-X和EmoContext最近被提出用来解决ERC问题。EmoContext的共享任务已经吸引了500多名参与者,证实了这个研究领域越来越受欢迎。与其他数据集相比,EmoContext数据集[37]具有非常短的对话,只包含三句话,目标是预测第三句话的标签。
这个数据集的前面的句子没有标签。关键在于使用bc-LSTM对上下文建模。这些工作中有一些共同的趋势,如融合传统词嵌入方法比如Glove、ELMo,来提高表现。大多数工作运用的注意力机制。图9b描述了Huang的HRLCE框架,由句子编码器和上下文编码器组成。为了表示这些句子,HRLCE运用了ELMo,GLOVE和Deepmoji.
HRLCE运用了多头注意力机制,旨在EmoContext上测评,不过它很容易适配其他ERC数据集。需要注意的是,EmoContext数据集上的所有工作都没有利用说话者信息。事实上,在我们的实验中,我们发现利用说话者信息的DialogueRNN在EmoContext数据集上的表现与Bae等人的、Huang等人的、Chatterjee等人的相似(表6)。一个可能的原因可能是数据集中存在非常短的上下文历史记录,这使得说话者的信息变得无关紧要。
结论
对话中的情感识别已在NLP研究人员中越来越流行。在本文中,我们总结了该任务的最新进展,并重点介绍了与此研究领域相关的几个关键研究挑战。此外,我们指出了当前的工作如何部分解决了这些挑战,同时也提出了一些不足。总的来说,一个有效的情绪转移识别模型和上下文编码器可以在聊天对话的基础上产生显著的性能改进,甚至可以改进面向任务的对话的某些方面。此外,诸如主题级别的特定于说话者的情绪识别,多方对话的ERC以及对话的嘲讽检测等挑战可以构成新的研究方向。此外,为了在长时间的独白中跟踪情绪,细粒度的特定于说话者的连续情绪识别可能会变得有趣。我们认为,解决本文概述的每个挑战不仅可以提高人工智能对话的理解能力,还可以通过满足情感信息来提高对话系统的性能。
