A Knowledge-Grounded Neural Conversation Model
Abstract
Neural network models arecapable of generating extremely natural sounding conversational interactions.Nevertheless, these models have yet to demonstrate that they can incorporatecontent in the form of factual information or entity-grounded opinion that wouldenable them to serve in more task-oriented conversational applications. Thispaper presents a novel, fully data-driven, and knowledge-grounded neuralconversation model aimed at producing more contentful responses without slotfilling. We generalize the widely-used SEQ2SEQ approach by conditioningresponses on both conversation history and external “facts”, allowing the modelto be versatile and applicable in an open-domain setting. Our approach yieldssignificant improvements over a competitive SEQ2SEQ baseline. Human judgesfound that our outputs are significantly more informative.
神经网络模型能够产生非常自然的对话交互。尽管如此,这些模型还没有证明他们可以以事实信息或基于实体的观点的形式整合内容,从而使他们能够服务于更多以任务为导向的对话应用程序。本文提出了一种新颖的,完全以数据驱动的,以知识为基础的神经对话模型,旨在没有时隙填充的情况下产生更多内容的响应。 我们推广广泛使用的SEQ2SEQ方法,通过调节对话历史记录和外部“事实”的响应,使模型具有通用性并适用于开放域设置。我们的方法对具有竞争性的SEQ2SEQ基线做出重要改进。人工评判发现我们的输出明显更丰富。
1 Introduction 简介
Conversational agents such asAlexa, Siri, and Cortana have been increasingly popular, as they facilitateinteraction between people and their devices. There is thus a growing need tobuild systems that can respond seamlessly and appropriately, and the task ofconversational response generation has recently become an active area ofresearch in natural language processing.
像Alexa,Siri和Cortana等会话代理已经越来越受欢迎,因为它们促进了人与设备之间的交互。 因此,越来越需要构建能够无缝适当做出反应的系统,并且会话响应生成的任务最近已成为自然语言处理研究的一个活跃领域。
Recent work has shown that itis possible to train conversational models in an end-to-end and completelydata-driven fashion, without hand-coding. However, these fully data-drivensystems lack grounding in the real world and do not have access to any externalknowledge (textual or structured), which makes it difficult to respondsubstantively. Fig. 1 illustrates the difficulty: while an ideal response woulddirectly reflect on the entities mentioned in the query (user input), neuralmodels produce responses that, while conversationally appropriate, seldominclude factual content. This contrasts with traditional dialog systems, whichcan easily inject entities and facts into responses using slot-filling, butoften at the cost of significant hand-coding, making such systems difficult toscale to new domains or tasks.
最近的工作表明,无需手动编码,就可以以端到端和完全数据驱动的方式来训练对话模型。 然而,这些完全由数据驱动的系统在现实世界中缺乏基础,并且无法获得任何外部知识(文本或结构化),这使系统难以做出实质性回应。 图1说明了难点:虽然理想的反应会直接反映在查询中提到的实体(用户输入),但神经模型产生的反应尽管在会话上合适,但很少包含事实内容。 这与传统的对话系统形成了鲜明的对比,传统的对话系统可以使用时隙填充功能轻松地将实体和事实注入响应中,但往往以大量手工编码为代价,使得这些系统难以扩展到新的领域或任务。
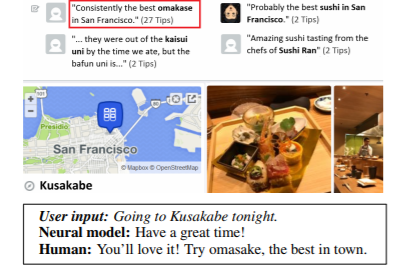
图1:完全由数据驱动的会话模型的响应通常是适当的,但通常缺乏人类响应的内容特征
The goal of this paper is tobenefit from both lines of research—fully data-driven and grounded in externalknowledge. The tie to external data is critical, as the knowledge that isneeded to make the conversation useful is often stored in non-conversationaldata, such as Wikipedia, books reviews on Goodreads, and restaurant reviews onFoursquare. While conversational agents can learn the backbone of humanconversations from millions of conversations (Twitter, Reddit, etc.), we relyon non-conversational data to infuse relevant knowledge in conversation withusers based on the context. More fundamentally, this line of research alsotargets more useful conversations. While prior data-driven conversationalmodels have been essentially used as chitchat bots, access to external data canhelp users make better decisions (e.g., recommendation or QA systems) oraccomplish specific tasks (e.g., task-completion agents).
本文的目标是受益于两条研究线索 - 全面的数据驱动和以外部知识为基础。 与外部数据的联系非常重要,因为使对话有用所需的知识通常存储在非传统数据中,例如Wikipedia,Goodreads的书评和Foursquare的餐厅评论。 尽管会话代理可以从数百万次会话(Twitter,Reddit等)中学习人类会话的主干,但我们依赖非会话数据从而能够根据上下文,在与用户的对话中输入相关知识。 更根本的是,这一系列的研究也针对更有用的对话。 虽然以前的数据驱动型会话模型基本上被用作聊天机器人,但访问外部数据可以帮助用户做出更好的决策(例如推荐或QA系统)或完成特定的任务(例如任务完成代理)。

图2:社交媒体数据集包括许多内容丰富而有用的交流,例如,这里是从真实推文中提取的推荐对话摘录。 尽管以前的模型(例如SEQ2SEQ)成功地学习了会话的主干,但他们难以建模和生成内容丰富的单词,例如在会话数据中稀疏表示的命名实体。 为了帮助解决这个问题,我们依赖非会话文本,这些文本更加详尽地表示这些实体。
This paper presents a novel,fully data-driven, and knowledge-grounded neural conversation model aimed atproducing more contentful responses. It offers a framework that generalizes theSEQ2SEQ approach of most previous neural conversation models, as it naturallycombines conversational and non-conversational data via multi-task learning.The key idea of this approach is that it not only conditions responses based onconversation history but also on external “facts” that are relevant to thecurrent context. Our approach only requires a way to ground externalinformation based on conversation context, which makes it highly versatile andapplicable in an open-domain setting. This allowed us to train our system at avery large scale using 23M social media conversations and 1.1M Foursquare tips.The trained system showed significant improvements over a competitivelarge-scale SEQ2SEQ baseline. To the best of our knowledge, this is the firstlarge-scale, fully data-driven neural conversation model that effectivelyexploits external knowledge, and it does so without explicit slot filling.
本文提出了一种新颖的,完全以数据驱动的,以知识为基础的神经对话模型,旨在产生更多内容的回应。它提供了一个概括大多数以前的神经对话模型的SEQ2SEQ方法的框架,因为它通过多任务学习自然地结合了对话和非对话数据。这种方法的关键思想是,它不仅要根据对话历史记录回应,而且还要基于与当前情况相关的外部“事实”。我们的方法只需要基于对话上下文来处理外部信息,这使得它在开放领域环境中具有很高的通用性和适用性。这使我们能够使用23M社交媒体对话和1.1M Foursquare提示,大规模地训练我们的系统。训练有素的系统比竞争性的大规模SEQ2SEQ基线显示出显着的改进。据我们所知,这是第一个有效利用大规模的外部知识,完全以数据驱动的神经对话模型,并且它没有明显的时隙填充。
2 Grounded Response Generation 有根据地产生回应
A primary challenge inbuilding fully data-driven conversation models is that most of the world’sknowledge is not represented in any existing conversational datasets. Whilethese datasets have grown dramatically in size thanks in particular to socialmedia, this data is still very far from containing discussions of every entryin Wikipedia, Foursquare, Goodreads, or IMDB. This problem considerably limitsthe appeal of existing data-driven conversation models, as they are bound torespond evasively or deflectively as in Fig. 1, especially with regard to thoseentities that are poorly represented in the conversational training data. Onthe other hand, even when such conversational data representing most entitiesof interest did exist, we would still face challenges as such huge datasetwould be difficult to be used for model training, and many conversationalpatterns exhibited in the data (e.g., for similar entities) would be redundant.
构建完全数据驱动的对话模型的主要挑战是大多数世界的知识没有表示在任何现有的对话数据集中。尽管这些数据集在规模上有了显着增长,特别是在社交媒体方面,但这些数据还远远不包含Wikipedia,Foursquare,Goodreads或IMDB中每个条目的讨论。这个问题极大地限制了现有数据驱动对话模型的吸引力,因为它们必然会如图1那样回避或偏离地做出回应,特别是对于那些在会话训练数据中代表性较差的实体。另一方面,即使当代表大多数感兴趣实体的对话数据确实存在时,我们仍然会面临挑战,因为这样庞大的数据集将难以用于模型训练,并且数据中展示的许多对话模式(例如,相似的实体)将是多余的。
Our approach aims to avoidredundancy and attempts to better generalize from existing conversational data,as illustrated in Fig. 2. While the conversations in the figure are aboutspecific venues, products, and services, conversational patterns are generaland equally applicable to other entities. The learned conversational behaviorscould be used to, e.g., recommend other products and services. A traditionaldialog system would use predefined slots to fill conversational backbone (bold text)with content; here, we present a more robust and scalable approach.
我们的方法旨在避免冗余,并试图从现有的会话数据中进行更好的概括,如图2所示。虽然图中的对话是关于特定场所,产品和服务的,但会话模式一般同样适用于其他实体。 学习到的会话行为可以用于其他诸如产品和服务的推荐。 传统的对话系统将使用预定义的插槽来填充会话骨干(粗体文本)和内容; 在这里,我们提出了一个更强大和可以扩展的方法。
In order to infuse theresponse with factual information relevant to the conversational context, wepropose a knowledge-grounded model architecture depicted in Fig. 3. First, wehave available a large collection of world facts, which is a large collection ofraw text entries (e.g., Foursquare, Wikipedia, or Amazon reviews) indexed bynamed entities as keys. Then, given a conversational history or source sequenceS, we identify the “focus” in S, which is the text span (one or more entities)based on which we form a query to link to the facts. This focus can either beidentified using keyword matching (e.g., a venue, city, or product name), ordetected using more advanced methods such as entity linking or named entityrecognition. The query is then used to retrieve all contextually relevantfacts: F = {f1, ..., fk} .Finally, both conversation history and relevant factsare fed into a neural architecture that features distinct encoders forconversation history and facts. We will detail this architecture in the subsectionsbelow.
为了将回答与会话语境相关的事实性信息注入,我们提出了一个基于知识的模型体系结构,如图3所示。首先,我们有大量的世界事实,这是一个由大量的原始文本命名实体索引的条目(例如,Foursquare,维基百科或亚马逊评论)作为关键字。然后,给定会话历史或源序列S,我们识别S中的“焦点”,即文本跨度(一个或多个实体),根据该文本形成查询以链接到事实。可以使用关键字匹配(例如场地,城市或产品名称)来识别该焦点,或者使用更高级的方法(例如实体链接或命名实体识别)来检测焦点。该查询然后用于检索所有与上下文相关的事实:F = {f1,...,fk}。最后,对话历史记录和相关事实都被输入到一个神经体系结构中,该体系结构以对话历史和事实的不同编码器为特征。我们将在下面的小节详细介绍这个架构。

图3:基于知识的模型架构。
This knowledge-groundedapproach is more general than SEQ2SEQ response generation, as it avoids theneed to learn the same conversational pattern for each distinct entity that wecare about. In fact, even if a given entity (e.g., @pizzalibretto in Fig. 2) isnot part of our conversational training data and therefore out-of-vocabulary,our approach is still able to rely on retrieved facts to generate anappropriate response. This also implies that we can enrich our system with newfacts without the need to retrain the full system.
这种基于知识的方法比SEQ2SEQ响应生成更普遍,因为它避免了需要为我们关心的每个不同实体学习相同的对话模式。事实上,即使一个给定的实体(例如图2中的@pizzalibretto)不属于我们的会话训练数据,因此也不属于我们的词汇,我们的方法仍然能够依靠检索到的事实来产生适当的响应。这也意味着我们可以用新的事实丰富我们的系统,而不需要重新训练整个系统。
We train our system usingmulti-task learning as a way of combining conversational data that is naturallyassociated with external data (e.g., discussions about restaurants 1 Forpresentation purposes, we refer to these items as “facts”, but a “fact” here issimply any snippet of authored text, which may contain subjective or inaccurateinformation. 2 In our work, we use a simple keyword-based IR engine to retrieverelevant facts from the full collection; more details are provided in Sec. 3.and other businesses as in Fig. 2), and less informal exchanges (e.g., aresponse to hi, how are you). More specifically, our multi-task setup containstwo types of tasks:
我们使用多任务学习来训练我们的系统,作为结合与外部数据自然相关的会话数据的一种方式(例如,关于餐馆的讨论1)为了演示的目的,我们将这些项目称为“事实”,但这里是“事实”是我们的工作中,我们使用一个简单的基于关键字的IR引擎从完整的集合中检索相关的事实;更多的细节在第3节中提供,其他的细节也可能包含主观的或不准确的信息。如图2所示的企业)以及较少的非正式交流(例如,对嗨,你好吗?)。更具体地说,我们的多任务设置包含两种类型的任务:
(1) one purelyconversational, where we expose the model without fact encoder with (S, R)training examples, where S represents the conversation history and R is theresponse;
(2) the other task exposesthe full model with ({f1, . . . , fk, S}, R) training examples.
(1)一个纯粹的对话,我们揭示了没有事实编码器的模型和(S,R)训练样例,其中S代表对话历史,R代表响应;
(2)另一个任务用({f1,...,fk,S},R)训练示例展示整个模型。
This decoupling of the twotraining conditions offer several advantages, including: First, it allows us topre-train the conversation-only dataset separately, and start multi-tasktraining (warm start) with a dialog encoder and decoder that already learnedthe backbone of conversations. Second, it gives us the flexibility to exposedifferent kind of conversational data in the two tasks. Finally, one interestingoption is to replace the response in task (2) with one of the facts (R = fi),which makes task (2) similar to an autoencoder and helps produce responses thatare even more contentful. We will discuss the different ways we applymulti-task learning in practice in greater detail in Sec. 4.
这两种训练条件的解耦提供了几个优点,包括:首先,它允许我们单独预训练仅对话数据集,并使用已经学习骨干的对话编码器和解码器开始多任务训练(热启动)的谈话。 其次,它使我们能够灵活地在两个任务中公开不同类型的会话数据。 最后,一个有趣的选择是将任务(2)中的响应替换为其中一个事实(R = fi),这使得任务(2)类似于自动编码器,并且有助于产生更加满意的响应。 我们将在第二节中更详细地讨论我们在实践中应用多任务学习的不同方式。
2.1 Dialog Encoder and Decoder 对话编码器和解码器
The dialog encoder andresponse decoder form together a sequence-to-sequence (SEQ2SEQ model, which hasbeen sucessfully used in building end-to-end conversational systems. Bothencoder and decoder are recurrent neural network (RNN) models: an RNN thatencodes a variable-length input string into a fixed-length vectorrepresentation and an RNN that decodes the vector representation into avariable-length output string. This part of our model is almost identical to priorconversational SEQ2SEQ models, except that we use gated recurrent units (GRU)instead of LSTM cells. Encoders and decoders in sequence-to-sequence modelssometimes share weights in monolingual tasks, but do not do so in the presentmodel, nor do they share word embeddings.
对话编码器和响应解码器一起构成一个序列到序列模型(SEQ2SEQ模型,它已经成功地用于构建端到端会话系统,编码器和解码器都是递归神经网络(RNN):编码的RNN 一个可变长度的输入字符串转换成一个固定长度的矢量表示,一个RNN将矢量表示可解码为一个可变长度的输出字符串,这部分模型与以前的对话式SEQ2SEQ模型几乎相同,除了我们使用门控循环单元(GRU)而不是LSTM单元。序列到序列模型中的编码器和解码器有时在单语言任务中共享权重,但在目前的模型中不这样做,也不共享单词嵌入。
2.2 Facts Encoder 事实编码器
The Facts Encoder of Fig. 3is similar to the Memory Network model first proposed by. It uses anassociative memory for modeling the facts relevant to a particular problem—inour case, an entity mentioned in a conversation–then retrieves and weightsthese facts based on the user input and conversation history to generate ananswer. Memory network models are widely used in Question Answering to makeinferences based on the facts saved in the memory.
图3的事实编码器类似于最初提出的存储器网络模型。 它使用联想记忆来建模与特定问题相关的事实(在我们的例子中,对话中提到的实体),然后根据用户输入和对话历史记录来检索和加权这些事实以生成答案。 记忆网络模型广泛用于问答系统中,根据保存在内存中的事实进行推理。
In our adaptation of memorynetworks, we use an RNN encoder to turn the input sequence (conversationhistory) into a vector, instead of a bag of words representation as used in theoriginal memory network models. This enables us to better exploit interlexicaldependencies between different parts of the input, and makes this memorynetwork model (facts encoder) more directly comparable to a SEQ2SEQ model.
在我们的记忆网络改编中,我们使用RNN编码器将输入序列(会话历史记录)转换为向量,而不是像原始记忆网络模型中使用的一组词表。 这使我们能够更好地利用输入不同部分之间的不连续依赖关系,并使此存储器网络模型(事实编码器)更直接地与SEQ2SEQ模型相媲美。
More formally, we are givenan input sentence S = {s1, s2, ..., sn}, and a fact set F = {f1, f2, ..., fk}that are relevant to the conversation history. The RNN encoder reads the inputstring word by word and updates its hidden state. After reading the whole inputsentence the hidden state of the RNN encoder, u is the summary of the inputsentence. By using an RNN encoder, we have a rich representation for a sourcesentence.
更正式地说,我们得到一个输入句S = {s1,s2,...,sn}和一个事实集F = {f1,f2,...,fk},它们与会话历史相关。 RNN编码器逐字读取输入字符串并更新其隐藏状态。 在读取整个输入句子RNN编码器的隐藏状态之后,u是输入句子的摘要。 通过使用RNN编码器,我们可以为源语句提供丰富的表示形式。
Let us assume u is a ddimensional vector and ri is the bag of words representation of fiwith dimension v. Based on we have:
让我们假设u是一个d维向量,ri是包含维数为v的fi的语料包表示。基于我们有:

Where A, C ∈ Rd×v are the parameters of the memory network. Then,unlike the original version of the memory network, we use an RNN decoder thatis good for generating the response. The hidden state of the RNN is initializedwith uˆ which is a symmetrization of input sentence and the external facts, topredict the response sentence R word by word.
其中A,C∈Rd×v是存储器网络的参数。 然后,与原始版本的存储器网络不同,我们使用一个适合生成响应的RNN解码器。 用输入语句和外部事实的对称化u来初始化RNN的隐藏状态,从而逐个词地预测响应句子R.
As alternatives to summing upfacts and dialog encodings in equation 5, we also experimented with otheroperations such as concatenation, but summation seemed to yield the bestresults. The memory network model of can be defined as a multi-layer structure.In this task, however, 1-layer memory network was used, since multi-hop inductionwas not needed.
作为等式5中总结事实和对话编码的替代方案,我们还尝试了其他操作,例如连接。但求和似乎产生了最好的结果。 存储器网络模型可以被定义为多层结构。 然而,在这项任务中,使用了1层存储网络,因为不需要多跳归纳。
3 Datasets 数据集
The approach we describeabove is quite general, and is applicable to any dataset that allows us to mapnamed entities to free-form text (e.g., Wikipedia, IMDB, TripAdvisor, etc.).For experimental purposes, we utilize datasets derived from two popular socialmedia services: Twitter (conversational data) and Foursquare (nonconversationaldata). Note that none of the processing applied to these datasets is specificto any underlying task or domain.
我们上面描述的方法是相当普遍的,适用于任何允许我们将命名实体映射到自由格式文本(例如Wikipedia,IMDB,TripAdvisor等)的数据集。 出于实验目的,我们利用来自两种流行社交媒体服务的数据集:Twitter(会话数据)和Foursquare(非转化数据)。 请注意,应用于这些数据集的处理均不针对任何基础任务或域
3.1 Foursquare
Foursquare tips are commentsleft by customers about restaurants and other, usually commercial,establishments. A large proportion of these describe aspects of theestablishment,and provide recommendations about what thecustomer enjoyed (or otherwise). We extracted from the web 1.1M tips relatingto establishments in North America. This was achieved by identifying a set of11 likely “foodie” cities and then collecting tip data associated with zipcodesnear the city centers. While we targeted foodie cities, the dataset is verygeneral and contains tips many types of local businesses (restaurants,theaters, museums, shopping, etc.) In the interests of manageability forexperimental purposes, we ignored establishments associated with fewer than 10tips, but other experiments with up to 50 tips per venue yield comparableresults. We further limited the tips to those that for which Twitter handleswere found in the Twitter conversation data.
Foursquare提示的是顾客留下的关于餐馆和其他商店,通常是商业机构的评论。 其中很大一部分描述了企业的各个方面,并提供了关于客户喜欢(或以其他方式)的建议。我们从网络中提取了与北美地区企业相关的1.1M提示。 这是通过确定一组11个可能的“美食家”城市,然后收集与城市中心附近的邮编相关的提示数据。 虽然我们针对的是美食城市,但数据集非常普遍,包含许多本地商业类型(餐馆,剧院,博物馆,购物等)的提示。为了实验目的的可管理性,我们忽略了少于10条相关提示的机构, 但其他实验每个场地最多可获得50个提示,可获得可比的结果。 我们进一步将这些提示限制在Twitter对话数据中找到Twitter处理的提示。
3.2 Twitter
We collected a 23M generaldataset of 3-turn conversations. This serves as a background dataset notassociated with facts, and its massive size is key to learning theconversational structure or backbone.
Separately, on the basis ofTwitter handles found in the Foursquare tip data, we collected approximately 1million two-turn conversations that contain entities that tie to Foursquare. Werefer to this as the 1M grounded dataset. Specifically, we identify conversationpairs in which the first turn contained either a handle of the business name(preceded by the “@” symbol) or a hashtag that matched a handle. Because we areinterested in conversations among real users (as opposed to customer serviceagents), we removed conversations where the response was generated by a userwith a handle found in the Foursquare data.
我们收集了一个23M的3轮谈话通用数据集。 这可以作为与事实无关的背景数据集,其大小是了解会话结构或骨干的关键。
另外,根据Foursquare提示数据中的Twitter句柄,我们收集了大约一百万个包含与Foursquare绑定的实体的两轮对话。 我们将其称为1M接地数据集。 具体而言,我们确定第一轮中包含商户名称句柄(前面带有“@”符号)或与句柄匹配的话题标签的对话对.因为我们对真实用户之间的对话感兴趣(而不是客户服务代理商),我们删除了用户使用Foursquare数据中的句柄生成的响应会话。
3.3 Grounded Conversation Datasets 接地的对话数据
We augment the 1M groundeddataset with facts (here Foursquare tips) relevant to each conversation history.The number of contextually relevant tips for some handles can sometimes beenormous, up to 10k. To filter them based on relevance to the input, the systemuses tf-idf similarity between the input sentence and all of these tips andretains 10 tips with the highest score.
我们使用与每个对话历史记录相关的事实(这里是Foursquare提示)来增加1M基础数据集。 有些句柄的上下文相关提示的数量有时可能很大,最高可达10k。 要根据输入的相关性对它们进行过滤,系统会在输入句子和所有这些提示之间使用tf-idf相似度,并保留10个提示得分最高的提示。
Furthermore, for asignificant portion of the 1M Twitter conversations collected using handles foundon Foursquare, the last turn was not particularly informative, e.g., when itprovides a purely socializing response (e.g., “have fun there”) rather than acontentful one. As one of our goals is to evaluate conversational systems ontheir ability to produce contentful responses, we select a dev and test set (4kconversations in total) designed to contain responses that are informative anduseful.
此外,对于使用Foursquare上找到的句柄收集的1M次Twitter对话,其中很大一部分的最后一次回合并不是特别有用。例如,当它提供纯粹的社交回应(例如,“在那里玩得开心”)而非满足感时。 我们的目标之一是评估会话系统对产生满意答案的能力,我们选择一个开发者和测试集(总共4k对话),旨在包含信息量大且有用的响应。
For each handle in ourdataset we created two scoring functions:
• Perplexity according to a1-gram LM trained on all the tips containing that handle.
• χ-square score, whichmeasures how much content each token bears in relation to the handle. Eachtweet is then scored on the basis of the average content score of its terms.
对于我们数据集中的每个句柄,我们创建了两个评分函数:
•根据在包含该手柄的所有提示上训练的1元LM进行困惑。
•χ平方得分,用于衡量每个令牌相对于手柄有多少内容。 然后每条推文都会根据其条款的平均内容分数进行评分。
In this manner, we selected15k top-ranked conversations using the LM score and 15k using the chi-squarescore. A further 15k conversations were randomly sampled. We then randomlysampled 10k conversations these data to be evaluated by crowdsourced annotators.Human judges were presented with the conversations and asked to determinewhether the response contained actionable information, i.e., did they containinformation that would permit the respondents to decide, e.g., whether or notthey should patronize an establishment. From this, we selected the top-ranked4k conversations to be held out validation set and test set; these were removedfrom our training data.
通过这种方式,我们使用LM分数选择15k排名靠前的会话,使用卡方分数选择15k。 进一步的15k对话随机抽样。 然后,我们随机抽取10k对话数据,由众包注释者评估。 向人工评判提交了对话,并要求确定回应是否包含可诉信息,即是否包含允许回复者作出决定的信息,例如他们是否应该光顾企业。 由此,我们选择排名最高的4k对话进行验证集和测试集; 这些从我们的培训数据中删除。
4 Experimental Setup
4.1 Multi-Task Learning
We use multi-task learningwith these tasks:
• FACTS task: We expose thefull model with ({f1, ..., fn, S}, R) training examples.
• NOFACTS task: We expose themodel without fact encoder with (S, R) examples.
• AUTOENCODER task: It issimilar to the FACTS task, except that we replace the response with each of thefacts, i.e., this model is trained on ({f1, ..., fn, S}, fi) examples. Thereare n times many samples for this task than for the FACTS task.
我们在这些任务中使用多任务学习:
•FACTS任务:我们用({f1,...,fn,S},R)训练样例展示完整模型。
•NOFACTS任务:我们公开没有事实编码器的模型和(S,R)示例。
• AUTOENCODER任务:它与FACTS任务类似,不同之处在于我们用每个事实来替换响应,即,这个模型在({f1,...,fn,S},fi)示例上进行了训练。 这个任务的样本数量是FACTS任务的n倍。
The tasks FACTS and NOFACTS are representativeof how our model is intended to work, but we found that the AUTOENCODER taskshelps inject more factual content into the response. Then, the differentvariants of our multi-task learned system exploits these tasks as follows:
FACTS和NOFACTS任务代表了我们的模型如何工作,但我们发现AUTOENCODER任务有助于在响应中注入更多实际内容。 然后,我们的多任务学习系统的不同变体如下开展这些任务:
• SEQ2SEQ: This system istrained on task NOFACTS with the 23M general conversation dataset. Since there isonly one task, it is not per se a multi-task setting.
• MTASK: This system is trained on twoinstances of the NOFACTS task, respectively with the 23M general dataset and 1Mgrounded dataset (but without the facts). While not an interesting system in itself,we include it to assess the effect of multi-task learning separately fromfacts.
• MTASK-R: This system istrained on the NOFACTS task with the 23M dataset, and the FACTS task with the1M grounded dataset.
• MTASK-F: This system istrained on the NOFACTS task with the 23M dataset, and the AUTOENCODER task withthe 1M dataset.
• MTASK-RF: This systemblends MTASK-F and MTASK-R, as it incorporates 3 tasks: NOFACTS with the 23Mgeneral dataset, FACTS with the 1M grounded dataset, and AUTOENCODER again withthe 1M dataset.
•SEQ2SEQ:使用23M常规对话数据集对该系统进行NOFACTS任务培训。 由于只有一个任务,它本身不是一个多任务设置。
•MTASK:该系统在NOFACTS任务的两个实例上进行训练,分别使用23M通用数据集和1M基础数据集(但没有事实)。 虽然本身并不是一个有趣的系统,但我们将它纳入其中,以便与事实分开评估多任务学习的效果。
•MTASK-R:该系统在使用23M数据集的NOFACTS任务和使用1M数据集的FACTS任务上进行了培训。
•MTASK-F:使用23M数据集对NOFACTS任务和具有1M数据集的AUTOENCODER任务进行此系统的培训。
•MTASK-RF:该系统融合了MTASK-F和MTASK-R,因为它包含3个任务:23M通用数据集的NOFACTS,1M接地数据集的FACTS,以及1M数据集的AUTOENCODER。
We trained a one-layer memorynetwork structure with two-layer SEQ2SEQ models. More specifically, we use2-layer GRU models with 512 hidden cells for each layer is used for encoder anddecoder, the dimensionality of word embeddings is set to 512, and the size ofinput/output memory representation is 1024. We used the Adam optimizer with afixed learning rate of 0.1, with a batch size is set to 128. All parameters areinitialized from a uniform distribution in [-(3/d)1/2, (3/d)1/2],where d is the dimension of the parameter. Gradients are clipped at 5 to avoidgradient explosion.
我们用两层SEQ2SEQ模型训练了一层内存网络结构。 更具体地说,我们使用具有用于编码器和解码器的每层512个隐藏单元的2层GRU模型,词嵌入的维度被设置为512,并且输入/输出存储器表示的大小是1024.我们使用Adam 优化器的固定学习率为0.1,批量大小设置为128.所有参数均以[ - (3 / d)1/2,(3 / d)1/2]中的均匀分布进行初始化,其中d 是参数的维数。 渐变裁剪为5以避免渐变爆炸。
Encoder and decoder usedifferent sets of parameters. The top 50k frequent types from conversation datais used as vocabulary which is shared between both conversation andnon-conversation data. We use the same learning technique as for multi-tasklearning. In each batch, all training data is sampled from one task only. Fortask i we define its mixing ratio value of αi , and for each batch we selectrandomly a new task i with probability of αi/ P j αj and train the system byits training data.
编码器和解码器使用不同的参数组。 会话数据中最常用的50k类型被用作会话和非会话数据之间共享的词汇。 我们使用与多任务学习相同的学习技巧。 在每批中,所有培训数据仅从一项任务中抽样。 对于任务i,我们定义αi的混合比率值,并且对于每一批次,我们随机选择具有αi/Pjαj的概率的新任务i并且通过训练数据训练系统。
4.2 Decoding and Reranking 解码和重新排序
We use a beam-search decodersimilar to with beam size of 200, and maximum response length of 30. Following,we generate N-best lists containing three features: (1) the log-likelihood logP(R|S, F) according to the decoder; (2) word count; (3) the log-likelihood logP(S|R) of the source given the response. The third feature is added to dealwith the issue of generating commonplace and generic responses such as “I don’tknow”, which is discussed in details in. Our models often do not need the thirdfeature to be effective, but—since our baseline needs it to avoid commonplaceresponses—we include this feature in all systems. This yields the followingreranking score:
我们使用类似于波束大小为200,最大响应长度为30的波束搜索解码器。接下来,我们生成包含三个特征的N-最佳列表:(1)对数似然性日志P(R | S,F) 根据解码器; (2)字数; (3)给出响应的源的对数似然日志P(S | R)。 第三个特征是用来处理产生普通和普通回答的问题,例如“我不知道”,这将在下面详细讨论。我们的模型通常不需要第三个特征是有效的,但是由于我们的 基线需要它来避免常见的反应——我们在所有系统中都包含此功能。 这会产生以下重新排列分数:
log P(R|S, F) + λ log P(S|R)+ γ|R|
λ and γ are free parameters,which we tune on our development N-best lists using MERT by optimizing BLEU. Toestimate P(S|R) we train a Sequence-to-sequence model by swapping messages andresponses. In this model we do not use any facts.
λ和γ是自由参数,我们通过优化BLEU使用MERT对我们开发的N最佳列表进行调优。 为了估计P(S | R),我们通过交换消息和响应来训练序列到序列模型。 在这个模型中,我们不使用任何事实。
4.3 Evaluation Metrics 评估指标
Following, we use BLEUautomatic evaluation. While suggest that BLEU correlates poorly with humanjudgment at the sentence-level, we use instead corpus-level BLEU, which isknown to better correlate with human judgments including for responsegeneration. We also report perplexity and lexical diversity, the latter as araw yet automatic measure of informativeness and diversity. Automaticevaluation is augmented with human judgments of appropriateness andinformativeness.
以下,我们使用BLEU自动评估。 尽管提示BLEU与句子层面的人类判断相关性较差,但我们使用的是语料库层次的BLEU,BLEU与人类判断包括响应产生更好地相关。 我们也报告困惑和词汇多样性,后者是一个信息量和多样性的原始但自动测量。 自动评估增加了人性判断的适当性和信息性。
5 Results
Automatic Evaluation: 自动评估
We computed perplexity andBLEU for each system. These are shown in Tables 1 and 2 respectively. Weobserve that the perplexity of MTASK and MTASK-R models on both general andgrounded data is as low as the SEQ2SEQ models that are trained specifically ongeneral and grounded data respectively. As expected, injecting more factualcontent into the response in MTASKF and MTASK-RF increased the perplexityespecially on grounded data.
BLEU scores are low, but thisis not untypical of conversational systems. Table 2 shows that the MTASK-Rmodel yields a significant performance boost, with a BLEU score increase of 96%and 71% jump in 1-gram diversity compared to the competitive SEQ2SEQ baseline.In terms of BLEU scores, MTASK-RF improvements is not significant, but itgenerates the highest 1-gram and 2-gram diversity among all models.
我们为每个系统计算了困惑和BLEU。 这些分别显示在表1和2中。 我们观察到MTASK和MTASK-R模型在通用和接地数据上的困惑程度都低于专门针对通用和接地数据分别训练的SEQ2SEQ模型。 正如所料,在MTASKF和MTASK-RF的响应中注入更多实际内容会增加困惑性,特别是在接地数据上。
BLEU分数很低,但这不是对话系统的非典型。 表2显示,与竞争性SEQ2SEQ基线相比,MTASK-R模型产生显着的性能提升,BLEU得分增加96%,1-gram多样性跳跃71%。 就BLEU分数而言,MTASK-RF的改善并不显着,但它在所有模型中产生最高的1克和2克的多样性。
Human Evaluation: We conducted human evaluations using a crowdsourcing service. Wehad annotators judge 500 paired conversations, asking which is better on two parameters:appropriateness to the topic, and informativeness. Seven judges were assignedto each pair. Annotators whose variance fell greater than two standarddeviations from the mean variance were dropped. Ties were permitted.
人工评估:我们使用众包服务进行人工评估。 我们让注释者判断500对配对,询问哪个更适合两个参数:适合主题和信息性。 七名法官分配给每一对。 注释者的方差下降幅度大于均值方差两个标准偏差。 领带被允许。
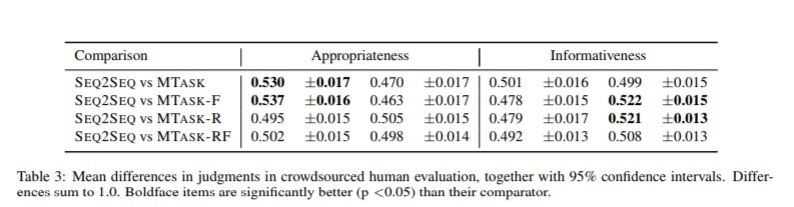
The results of annotation areshow in Table 3. On Appropriateness, no system performed significantly betterthan baseline, and in two cases, MTASK and MTASK-F, the baseline system wassignificantly better. MTASK-R appears to be slightly better than baseline inthe table, but the difference is small and not statistically significant byconventional standards of α = 0.05. On Informativeness, MTASK-F and MTASK-Rperform significantly better than Baseline (p = 0.005 and p = 0.003respectively). Since the baseline system outperforms MTASK-F with respect toAppropriateness, this may mean that MTASK-F encounters difficulty representingthe social dimensions of conversation,but is strong oninformational content. MTASK-R, on the other hand, appears to hold its own onAppropriateness while improving with respect to Informativeness.
注释结果如表3所示。在适用性方面,没有系统的表现明显优于基线,而在两种情况下,MTASK和MTASK-F,基线系统明显更好。 表中MTASK-R似乎略好于基线,但差异很小,并且在α= 0.05的常规标准下没有统计学显着性。 在信息性方面,MTASK-F和MTASK-R的表现明显优于基线(分别为p = 0.005和p = 0.003)。 由于基准系统在适用性方面优于MTASK-F,这可能意味着MTASK-F遇到难以表示对话的社交维度,但在信息内容上很强。 另一方面,MTASK-R似乎在适当性方面持有自己的观点,同时在信息性方面有所改进。
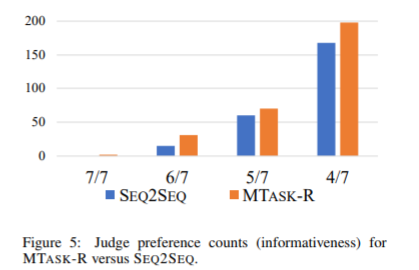
The narrow differences inaverages in Table 3 tend to obfuscate the judges’ voting trends. Accordingly,we translated the scores for each output into the ratio of judges who preferredthat system and binned their counts. The results are shown in Figs. 4 and 5where we compare MTASK-R with the SEQ2SEQ baseline. Bin 7 on the leftcorresponds to the case where all 7 judges “voted” for the system, bin 6 tothat where 6 out of 7 judges “voted” for the system, and so on. Other bins arenot shown since these are a mirror image of bins 7 through 4. The distributionsin Fig. 4 are more similar to each other than in Fig. 5. indicating that judgepreference for the MTASK-R model is relatively stronger with regard toinformativeness.
表3中平均数的狭隘差异往往会混淆法官的投票趋势。 因此,我们将每个输出的分数转换为那些喜欢这个系统并分类计数的法官的比例。结果如图1和2所示。 我们将MTASK-R与SEQ2SEQ基线进行比较。左边的7号箱对应于所有7名法官“为该系统投票”,6号箱到7名法官中有6人“为该系统投票”的情况,等等。 其他箱并未示出,因为它们是箱7到箱4的镜像。图4中的分布比图5中的彼此更相似,这表明判断对MTASK-R模型的偏好相对较强 提供信息。


6 Discussion
Figure 6 presents examples ofoutputs generated by MTASK-RF model. It illustrates that responses of our modelare generally not only generally adequate, but also more informative and useful.
For example the firstresponse combines “have a safe flight”, which is safe and appropriate and assuch typical of existing neural conversational systems, but also “nice airportterminal”, which is grounded in knowledge about the specific airport. While ourmodel sometimes regurgitates fragments of tips in its responses, it oftenblends together information from various tips and the conversational in orderto produce a response, such as in the the 5th and last responses of the figure.The 5th is mainly influenced by two Foursquare tips and the model creates afusion of the two, a kind of text manipulation that would be difficult withslot filling.
图6给出了由MTASK-RF模型生成的输出示例。 它说明我们的模型的反应一般不仅通常是适当的,而且更具信息性和有用性。
例如,第一个响应结合了“安全飞行”,这是安全和适当的,以及现有神经对话系统的典型特征,而且还包括基于关于特定机场的知识的“好机场候机楼”。 虽然我们的模型有时会在响应中反复提示片段,但它通常会将来自各种提示和会话的信息混合在一起,以便产生响应,如图中的第5个和最后一个响应。 第五个主要受到两个Foursquare提示的影响,模型创建了两个融合,这是一种文本操作,在插槽填充时会很困难。
7 Related Work
The present work extends thedata-driven paradigm of conversation generation by injecting knowledge fromtextual data into models derived from conversational data. This paradigm wasintroduced by Ritter et al. who first proposed using statistical MachineTranslation models to generate conversational responses from social media data.It has been was further advanced by the introduction of neural network models. Theintroduction of contextual models by is an important advance; we build on thisby incorporating context from outside the conversation.
目前的工作通过将来自文本数据的知识注入到来自会话数据的模型中来扩展对话生成的数据驱动范式。 Ritter等人介绍了这种范例。 他首先提出使用统计机器翻译模型来生成来自社交媒体数据的会话响应。 通过引入神经网络模型已经进一步推进。 情境模型的引入是一个重要的进步; 我们通过结合对话之外的背景来建立在这个基础上。
This work distinguishesitself from a second paradigm of neural dialog modeling in which questionanswer slots are explicitly learned from small amounts of crowd-sourced data orcustomer support logs . In many respects, this second paradigm can becharacterized as an extension of conventional dialog models with or withoutstatistical modelling.
Relevant to the current workis, who employ memory networks to handle restaurant reservations, using a smallnumber of keywords to handle entity types in a knowledge base (cuisine type,location, price range, party size, rating, phone number and address). Thatapproach requires a highly structured knowledge base, whereas we are attemptingto leverage free-form text using a highly scalable approach in order tolearning implicit slots.
这项工作区别于神经对话建模的第二范例,其中问题答案槽是从少量众包数据或客户支日志中明确获知的。 在许多方面,这个第二范式可以被表征为传统对话模型的扩展,有或没有统计建模。
与当前工作相关的是,他们使用记忆网络来处理餐馆预订,使用少量关键字处理知识库中的实体类型(美食类型,位置,价格范围,派对大小,评分,电话号码和地址)。 这种方法需要高度结构化的知识库,而我们正试图利用高度可扩展的方法利用自由形式的文本来学习隐式插槽。
8 Conclusions
We have presented a novelknowledge-grounded conversation engine that could serve as the core componentof a multi-turn recommendation or conversational QA system. The model is alargescale, scalable, fully data-driven neural conversation model thateffectively exploits external knowledge,and does so without explicitslot filling. It generalizes the SEQ2SEQ approach to neural conversation modelsby naturally combining conversational and non-conversational data throughmulti-task learning. Our simple entity matching approach to grounding externalinformation based on conversation context makes for a model that isinformative, versatile and applicable in open-domain systems.
我们已经提出了一种新型的基于知识的谈话引擎,可以作为多回合推荐或会话QA系统的核心组件。 该模型是一种大规模,可扩展,完全数据驱动的神经对话模型,可有效利用外部知识,并且无需显式填充时隙。 它通过自然地通过多任务学习将会话和非会话数据结合起来,将SEQ2SEQ方法推广到神经对话模型。 我们简单的实体匹配方法可以基于会话上下文建立基础外部信息,这使得该模型具有信息性,通用性并且适用于开放域系统。