使用person embedding
embedding 的作用
蕴含背景和说话方式,解决了多轮对话中response不一致的问题。(换一种方式问问题,得到的答案不同)。

embedding的实现
- 具体的人物做背景标注昂贵,根据对话的回答聚类产生。
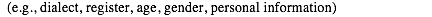
- 在target的E表示中加入speaker representation。每个source用户绑定一个向量vi,在decode的时候和h_t,e_t(cell state应该)一起作为输入。


- 训练的判断方式,
- BELU, perplexity,
- test的时候,i和j没有Wi和Wj,使用临近的i‘和j’来代替,所以speaker-address model需要训练vi,vj,wi,wj,一共3个矩阵
- speak 和 speak-address的区别是后者考虑了两个说话人

- 效果:improve relative performance up to 20% in BLEU score and 12% in perplexity
代码的部分细节
persona E的产生
https://github.com/fionn-mac/A-Persona-Based-Neural-Conversation-Model/tree/master/Fine_Tune(pytorch版本)
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import Pre_Train
from Pre_Train.decoder_rnn import Decoder_RNN as Base_Class
from attention import Attention
class Decoder_RNN(Base_Class):
def __init__(self, hidden_size, embedding, personas, num_layers=1, use_embedding=False,
train_embedding=True, dropout_p=0.1):
Base_Class.__init__(self, hidden_size, embedding, num_layers, use_embedding, train_embedding, dropout_p)
self.personas = nn.Embedding(personas[0], personas[1])
if use_embedding:
self.input_size = embedding.shape[1] + personas[1] # Size of embedding vector
else:
self.input_size = embedding[1] + personas[1] # Size of embedding vector
self.gru = nn.GRU(self.hidden_size + self.input_size, self.hidden_size, self.num_layers)
def forward(self, input, speakers, hidden, encoder_outputs):
"""
input -> (1 x Batch Size)
speakers -> (1 x Batch Size, Addressees of inputs to Encoder)
hidden -> (Num. Layers * Num. Directions x Batch Size x Hidden Size)
encoder_outputs -> (Max Sentence Length, Batch Size, Hidden Size)
"""
batch_size = input.size()[1]
embedded = self.embedding(input) # (1, B, V)
persona = self.personas(speakers) # (1, B, V')
features = torch.cat((embedded, persona), 2)
attn_weights = self.attn(hidden[-1], encoder_outputs)
# (batch, out_len, in_len) * (batch, in_len, dim) -> (batch, out_len, dim)
context = attn_weights.bmm(encoder_outputs.transpose(0, 1)).transpose(0, 1)
rnn_input = torch.cat((features, context), 2)
output, hidden = self.gru(rnn_input, hidden)
output = output.squeeze(0) # (1, B, V) -> (B, V)
output = F.log_softmax(self.out(output), dim=1)
return output, hidden, attn_weights
人物的聚类是如何产生未详细介绍。想到社交平台上用户是有大量特征的,比如网易云的音乐喜好属性,头条算法的新闻喜好属性。
数据集中只有几种人,把这些人每人对应一个index,
数据集的形式: 2 45 43 6|1 123 45(第一个数字2是第一个人的代号。横杠之后第二个数字1是第二个人的代号)
https://github.com/jiweil/Neural-Dialogue-Generation/tree/master/Persona_Addressee,
代码查看:
对于GRU在decoder部分的结构,
输入的rnn_input【context和feature(上一次的输出和person向量)】,
和hidden一起一起作为GRU的参数输入,
(context和hidden区别,context是注意力之后的hidden)
其他备注
- 使用beamsearch然后N-best,还有rerank,避免“呵呵”无意义回答。
- 第一个模型的数据集是twitter,第二个是老友记的语料,涉及到多轮对话,而且每个人特征不同。
- 别人的意见。人物特征建模还可以用于情感分析。出了person representation还可以有context representation。但是这个context在任务型和随意聊天中不一样。具体如何定义context应该比较复杂。
- 疑问:很多人都说很有理论意义。但是我后来查找论文发现虽然被引用的多但是基本没有正文引用的。