我在知乎里看到的推荐文章,结果发现是沐神的。去年入门的时候就是看的沐神的视频开始做的,顿时来了兴趣。
摘要:
在图像分类的相关研究中,都有着很多的小trick。但是这些trick不会在文章中提及,只会写在源码中(所以,多看别人的源码很重要!!trick,代码精简都是很深的学问呢!)。那么在这篇文章中,就研究了这些可以使performrence提高的trick,以及经验性地通过ablation study来说明每个trick对模型准确率的影响。
将这些trick组合运用,ResNet-50的top-1验证准确性在ImageNet上从75.3%提高到79.29%,并且还可以迁徙到其他方向。
introduce:
扯了一些家常,会建立一个训练baseline,然后用trick改进等等。
Training Procedures
首先给了一个函数、超参的baseline算法--小批量随机梯度下降算法

模型使用resnet最常用的版本,train步骤和Infer步骤如下:
train:
1.随机采样一张图像并将其解码为[0,255]的32位浮点型原始像素值;
2.在[3/4,4/3]中随机选取长宽比,[8%,100%]中随机选取面积比进行裁减。然后resize成224*224的矩形图;
3.以p=0.5的概率进行随机水平翻转;
4.比例色相,饱和度和亮度,系数均取自[0.6,1.4];
5.用正态分布N(0,0.1)采样的系数加上PCA噪声;
6.对RGB三通道进行标准化,均值取[123.68,116.779,103.939],方差取[58.393,57.12,57.375]
验证阶段:
保持图像长宽比,然后将较短边resize到256。再中心裁减为224*224。最后RGB三通道正则化按训练的来。(验证不添加任何的随机增强)
初始化:
Xavier初始化(即权重参数均匀选择[-a,a],a=根(6/din+dout),din和dout是该层的输入通道数和输出通道数,偏差参数设为0,BN层中,gama=1,beta=0)
其余:
优化算法选择NAG,120个epoch,8个v100,batch-size=256,学习率0.1,30th\60th\90th epoch下降10倍。
实验结果:
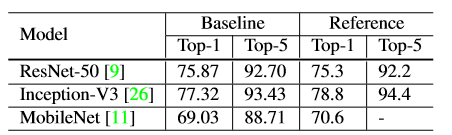
effientTraining:
讨论一下在不牺牲模型精度情况下,实现低数值精度和更大批量。
大批量训练:
可以提高硬件的并行能力降低通信成本,但是会减慢训练进度。但可以利用启发式方法来解决这个问题。
法一:线性缩放学习率:
批量梯度下降过程中,批量的大小不会改变梯度的期望。但批量越大梯度的方差越小,即大批量可以较少梯度中的噪声。因此,对于大批量训练来说可以适度提高学习率。选择根据皮杜大小线性增加学习率。256批量大小,初始学习率0.1。更大的批量b时,初始lr设置为0.1*b/256。
法二:学习率warm-up:
原因:随机初始化的参数离最终solution的参数相差甚远,刚开始大的学习率可能导致数值不稳定。因此可以先用小的学习率warm-up,再到初始学习率进行学习。策略为:前m个batch(如5个)用于warm-up,初始学习率为beta,小于m的batch学习率设为i*beta/m。
法三:零γ:
因为残差块的输出为x+block(x),其中block的最后层时BN层(BN层标准化输入为 ˆ x, 然后比例转换为 γˆ x + β。一般γ和β初始化为1和0。但是这样对后面的mimics网络来说训练时困难的。因此将γ设为0,可以将每个残差块的输出为x。这样就可以初始的时候较好的训练mimics网络。
法四:无偏差衰减:
权重和偏差衰减的目的是减少模型的过拟合。一般使用L2正则化。但是有文章提出仅需对权重进行衰减即可。因此,在卷积层和全连接层中只对权重衰减,BN层中的偏差、γ、 β不衰减。
note that:对极大批量来说layer-wise自适应学习率有效。
低精度训练:
神经网络data一般使用FP32类型,但是以v100为例,其提供14TFLOPS用于32位浮点运算,提供100TFLOPS用于16位浮点运算。因此选择FP16进行运算可以提高2-3倍运算速度。
但是native的用FP16对训练可能出现不利。因此有提出:FP16储存所有参数和激活值,并用FP16计算梯度。同时,所有参数copy到FP32中进行更新。另外(loss*一个标量)使之更好的FP32中计算。
最后的效果:
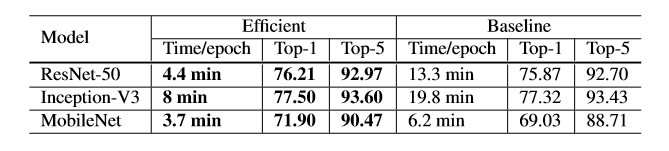

模型调整
模型调整一般不会改变计算复杂度(如改变stride),但对结果影响巨大。
resnet模型介绍:包括:1.Inputstem:下采样4倍,2.stage:两个residual bolck和一个 bottleneck structure(下采样2倍) 3.根据residual block数量分为ResNet-50 and ResNet-152等模型。

resnet-B:在downsampling模块中,pathA第一个卷积为1*1和stride = 2,因此它忽略了特征图的3/4,调整--将stride=2放在next卷积中,其kernel=(3,3),stride = 2,不会有信息忽略。
resnet-C:在Inception-v2中提出,应用于SENet,PSPNet,DeepLabV3,ShuffleNet中。用3*3的kernel代替A中的7*7的kernel。减少计算代价。
resnet-D:基于B的分析,将kernel=1*1 stride=2的卷积层中,stride改为1,并在后面添加一个平均池化层(kernel = 2*2 ,stride = 2)。

结果如下:尽管resnet-D最复杂,但计算效率仅增加了3%
训练技巧:
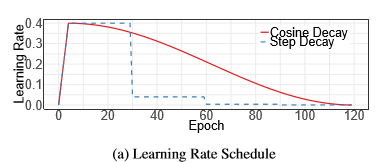
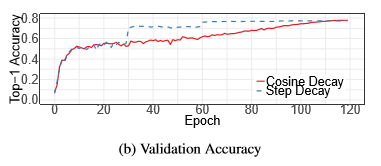
1.余弦学习率衰减:
一般学习率在warm-up后采用指数下降的形式下降(每30个epoch 乘以0.1,或者每两个乘以0.94)。
余弦退火策略是,在warm-up后按照余弦曲线下降到0: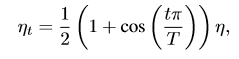 其中,T为总批次,t是当前批次, η 为初始学习率。
其中,T为总批次,t是当前批次, η 为初始学习率。
2.标签平滑:
原本用于分类的全连接网络,跟上一个sofmax层,使得输出为一个概率分布形式。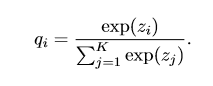 ,loss=
,loss= 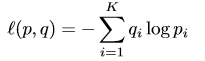 =
=![]() 。这样的最优结果形式为:zy=Inf,其余的尽可能小。该方法使得模型过于自信,容易过拟合。
。这样的最优结果形式为:zy=Inf,其余的尽可能小。该方法使得模型过于自信,容易过拟合。
label-smoothing的方法是将原先的指示函数( a truth probability distribution to be pi = 1 if i = y and 0 otherwise)进行修改:
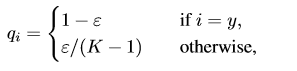 这样一来,最优解如下:
这样一来,最优解如下:
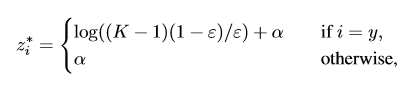
其中log((K −1)(1−ε)/ε) 称为gap,即 最大概率类别的得分 与 其他类别得分的平均值 之间的差距。
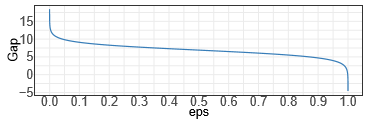
当 ε = 0.1 and K = 1000时,两个模型的输出对比:
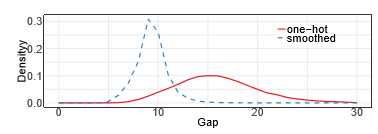 。可以看出:label-smoothing的gap分布在理论gap附近,且极值较少。
。可以看出:label-smoothing的gap分布在理论gap附近,且极值较少。
3.知识蒸馏:
就是利用一个较高准确率的预训练模型来指导模型训练。做法是Loss中增加一个蒸馏loss:
loss(p,softmax(z)) + T^2*loss(softmax(r/T),softmax(z/T)),
(r是预训练模型的全连接层输出,z是训练模型的全连接层输出,T称为温度超参,控制比重的)。目的是让模型的输出更平滑,因为是从预训练模型中蒸馏出来的结果分布中学习。
4.混合训练:
每次选取两个新样本,利用线性插值生成一个新样本进行训练。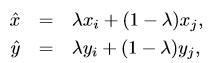 。λ ∈ [0,1] is a random number drawn from the Beta (α,α) distribution
。λ ∈ [0,1] is a random number drawn from the Beta (α,α) distribution
(这个思想第一次看到,顺便也看了一下paper,是一个非常有意思的想法,对于降低预测空间的复杂度很有帮助)
