转载请注明出处:https://blog.csdn.net/HHTNAN
简介
CoreNLP 项目是Stanford开发的一套开源的NLP系统。包括tokenize, pos , parse 等功能,与SpaCy类似。SpaCy号称是目前最快的NLP系统, 并且提供现成的python接口,但不足之处就是目前还不支持中文处理, CoreNLP则包含了中文模型,可以直接用于处理中文, 但CoreNLP使用Java开发,python调用稍微麻烦一点。
Stanford CoreNLP是一个比较厉害的自然语言处理工具,很多模型都是基于深度学习方法训练得到的。
先附上其官网链接:
https://stanfordnlp.github.io/CoreNLP/index.html
https://nlp.stanford.edu/nlp/javadoc/javanlp/
https://github.com/stanfordnlp/CoreNLP
安装Installation
windows 10 环境
安装依赖
1.首先需要配置JDK,安装JDK 1.8及以上版本。。
2.之后到 https://stanfordnlp.github.io/CoreNLP/history.html 下载对应的jar包。
将压缩包解压得到目录,再将语言的jar包放到这个目录下即可。
3.下载Stanford CoreNLP文件:http://stanfordnlp.github.io/CoreNLP/download.html

4.下载中文模型jar包(注意一定要下载这个文件,否则它默认是按英文来处理的)。
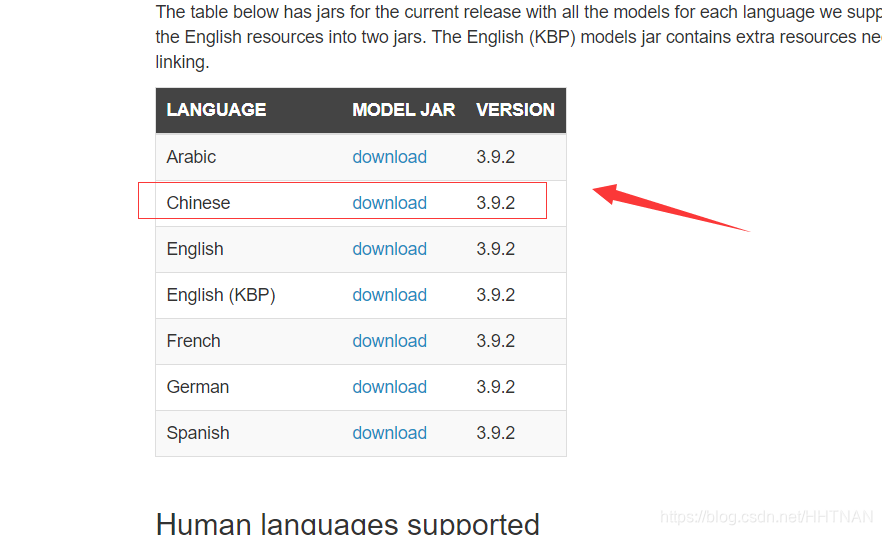
5.接下来py安装 stanfordcorenlp
6. 解压配置
下载完成后两个文件加起来1G+下载完成后两个文件加起来1G+

把解压后的Stanford CoreNLP文件夹下载的Stanford-chinese-corenlp-2018—models.jar放在同一目录下(注意:一定要在同一目录下,否则执行会报错)

7. 在Python中引用模型,执行下面语句:
from stanfordcorenlp import StanfordCoreNLP
nlp=StanfordCoreNLP(r’D:\D:\stanford_nlp\stanford-corenlp-full-2018-10-05’,lang=‘zh’)
应用
#encoding="utf-8"
from stanfordcorenlp import StanfordCoreNLP
import os
if os.path.exists('D:\\stanford_nlp\\stanford-corenlp-full-2018-10-05'):
print("corenlp exists")
else:
print("corenlp not exists")
nlp=StanfordCoreNLP('D:\\stanford_nlp\\stanford-corenlp-full-2018-10-05',lang='zh')
sentence = '王明是清华大学的一个研究生'
print(nlp.ner(sentence))
输出:
corenlp exists
[(‘王明’, ‘PERSON’), (‘是’, ‘O’), (‘清华’, ‘ORGANIZATION’), (‘大学’, ‘ORGANIZATION’), (‘的’, ‘O’), (‘一’, ‘NUMBER’), (‘个’, ‘O’), (‘研究生’, ‘O’)]
三、查看词性标注
在浏览器中访问:http://localhost:9000/

转载请注明出处:https://blog.csdn.net/HHTNAN