由于之前发布了HMM模型的详细代码讲解,但是一万二千字的内容大家看着也头皮发麻,所以在写这个日期识别的时候我分为几篇文章进行讲解,这样就能用更多的图例来描绘代码的运转过程,也能方便大家更好的阅读。
目录
零、命名实体识别(NER)
命名实体识别(Named Entities Recognition,NER),书上写的关于NER我觉得最重要的一句话就是:NER的目的是识别语料中人名、地名、组织机构名等命名实体。
我先简单来谈一谈对于这个"命名实体识别"的想法。我们从英文入手(毕竟这东西也是他们发明的然后我们翻译的,所以我个人觉得肯定直接看英文比较好),recognition这个就没的说了,就是识别,但是是识别什么?那就是Named Entities,命名的实体。那么我们的目标就是转移到了对这个"命名的实体"的理解上来。
我们先讨论一下"实体"的概念,百度百科的解释是:客观存在并可相互区别的事物;数据库中的定义是:某类事物的集合,把每一类数据对象的个体称为实体;再结合上上文写到的关于NER的目的和"命名"二字,那么这里"命名实体"就可以理解为:主要对象为名词的未登录词。
这里有两个需要翻译的点:
- “主要”: 为什么说是主要,因为这后面不是实战内容是"日期识别"么,既然划分过来了那不就属于NER么,所以我这里说是主要。
- 未登录词: 未登录词指的是没有被收录在分词词表中但必须切分出来的词,包括各类缩写词、专有名词、新增词汇。
我这里为什么写了这么多NER的内容,主要就是为了帮助大家找到我们使用NER主要针对的是什么问题,有了目标才能有相应的合适的方法对吧。
然后关于"条件随机场(CRF)",由于本例子中没有用到,所以这里就不讲了,如果我以后有写这方面的文章那就再说吧。
以上是闲谈,下面是正文的开始。
一、说明
作者在书上也写到了,这种基于规则(例子中大量使用的正则表达式)的命名实体识别虽然运行速度快且无需进行训练,但是普适性较差。所以我对他的代码有点点小的改动,以及找到了几个相应的优化点与大家一起分享。
在本文及之后的文章中代码讲解的顺序就依据方法出现的先后顺序进行讲解。
二、time_extract(text)
1. 代码流程
def time_extract(text):
"""
思路:
通过jieba分词将带有时间信息的词进行切分,记录连续时间信息的词。
使用了词性标注,提取"m(数字)"和"t(时间)"词性的词。
规则约束:
对句子进行解析,提取其中所有能表示日期时间的词,并进行上下文拼接
:param text: 每一个请求文本
:return: 解析出来后最终的句子
"""
time_res = []
word = ''
key_date = {'今天': 0, '明天': 1, '后天': 2}
for k, v in psg.cut(text):
# k: 词语, v: 词性
if k in key_date:
# 当k存在于key_date中时
if word != '':
# 如果word不为空时, 列表中添加相应的词语
time_res.append(word)
# 获取系统当前时间,并且获取句子中时间的跨度(0, 1, 2),通过当前时间 + 时间跨度获得几天后的时间
word = (datetime.today() + timedelta(days=key_date.get(k, 0))) \
.strftime('%Y {0} %m {1} %d {2} ').format('年', '月', '日')
elif word != '':
# 如果k不存在于key_date时,word不为空
if v in ['m', 't']:
# 当词性为数字或时间时,添加至word中
word = word + k
else:
# 当词性不为数字或时间时,将word放入time_res,同时清空word
time_res.append(word)
word = ''
elif v in ['m', 't']:
# 当k不存在于key_date中,且word为空时,如果词性是数字或时间时,word为该词语
word = k
if word != '':
# word中可能存放的值:
# 1. 通过词性标注后获得的时间跨度后的时间
# 2. 非key_date中的时间或数字
# 即只有k不存在于key_date,word不为空,词性不为数字或时间时,word才为空,进入不了这个if语句
time_res.append(word)
# 如果返回的结果是None,则直接清洗,否则放入集合中
result = list(filter(lambda x: x is not None, [check_time_valid(w) for w in time_res]))
final_res = [parse_datetime(w) for w in result]
return [x for x in final_res if x is not None]
这一段基本是我看的最久的一个方法,也是本例子中最核心的一段代码,因为后面的方法都是在这段代码的基础上延伸的,而这里最核心的就是初步清洗的方法,即for语句里面的内容,我这里使用一个图解来说明具体步骤,后面的部分读者就可以自行推导了。
使用的句子如下:我从今天住到后天下午3点。分词结果如下:
我/r 从/p 今天/t 住/v 到/v 后天/t 下午/t 3/m 点/m
- step 1: 首先"我"不在key_date中,第一个if语句不执行;其次word == “”,那么第一个elif语句不执行;最后v != ‘m’ and v != ‘t’,所以第二个elif语句不执行。具体的数据情况如下:

- step 2: 同上一步,不多赘述
- step 3: 这里发现"今天"在key_date中,于是执行第一个if语句,这时候word为空,内层第一个if语句跳过,于是执行后面这一团代码,这一团代码的含义是,将系统的今天时间 + 时间跨度后的时间组装成"%Y 年 %m 月 %d 日"这种格式,具体的数据变化图如下:
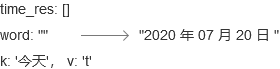
- step 4 :"住"不在key_date中,于是跳过这个if语句,word不为空,所以进入第一个elif语句。由于v == “v”,不执行这个内层if语句,执行else语句,将word装入time_res,同时清空word。具体数据变化如下:

- step 5:"到"同第一步。
- step 6:"后天"在key_date中,同step 3,具体的数据变化图如下:

- step 7:"下午"不在key_date中,此时word不为空,进入第一个elif语句,同时v == ‘t’,进入内层第一个if语句。具体的数据变化图如下:

- step 8 and step 9:"3"和"点"同step 7相同,数据变化图如下:
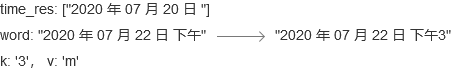
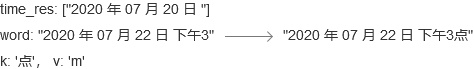
至此,for语句结束,但是word还不为空,所以需要执行最下面这个if语句,将word中的内容添加至time_res中,time_res最后如下:
time_res: ['2020 年 07 月 20 日 ', '2020 年 07 月 22 日 下午3点']
数据的初步清洗就是time_res获取完成,这时候我们就获取了之前文本中的所有有关时间的内容,之后的两行语句就是数据的后续处理,由于涉及到了其他的方法,所以下文进行讨论。
2. 代码逻辑
其实在这串代码中,word就是一个中间变量,用于记录所有的与时间和数字有关的内容,time_res才是真正的初步处理后的时间变量。
由于我们是需要把一个独立的时间,比如“2020 年 07 月 20 日”和“2020 年 07 月 22 日 下午3点”这种存储进入列表中,所以word需要一次性记录足够的时间信息才能转移至time_res中。
由于担心这一段话中还有另外一个时间段,所以当检测到word不为空(记录了时间)且下一个的词不是时间和数字词时,就先转移。
3. 优化问题
3.1 代码优化
关于第一个if语句内嵌的if语句中,word在书本上是如下的:
word = (datetime.today() + timedelta(days=key_date.get(k, 0))).strftime("%Y 年 %m 月 %d 日")
但是我跑代码的时候报错,大体上意思是编码格式有问题,所以我改动了下代码如下:
word = (datetime.today() + timedelta(days=key_date.get(k, 0))) \
.strftime('%Y {0} %m {1} %d {2} ').format('年', '月', '日')
3.2 规则优化
代码中没有体现,但是有个思路,因为有可能我们会这样说:我要今天入住,在下午。其实我们表达的是一个时间,但是使用上面的代码出来就是两个时间段了,所以这里也看得出来单纯的基于规则的NER是很欠缺普适性的。
三、check_time_valid(word)
这是我觉得最神奇的一个方法,清洗的方法如果我理解的没有错的话,就可读性贼差,我们先看代码:
def check_time_valid(word):
"""
对拼接字符串近一步处理,以进行有效性判断
:param word: time_res中的每一项(每一项切割出来的时间)
:return: 清洗后的句子
"""
# match()匹配成功返回对象,否则返回None,
# match是全匹配,即从头到尾,而$是匹配最后,从match源码来看,如果str是存在非数字的情况会直接返回None
# 这里的意思就是清洗掉长度小于等于6的纯数字(小于等于6的意思是指非准确日期,比如2020)
m = re.match('\d+$', word)
if m:
# 当正则表达式匹配成功时,判断句子的长度是否小于等于6,如果小于等于6,则返回None
if len(word) <= 6:
return None
# 将"号"和"日"替换为"日",个人理解,这里是号和日后面莫名其妙跟了一串数字的情况
word_1 = re.sub('[号|日]\d+$', '日', word)
if word_1 != word:
# 如果清洗出来的句子与原句子不同,则递归调用
return check_time_valid(word_1)
else:
# 如果清洗出来的句子与原句子相同,则返回任意一个句子
return word_1
我最大的迷茫的是这个正则表达式:
m = re.match('\d+$', word)
先说正则\d+$,就是从后向前匹配所有数字,遇到开头或者非数字就停止,而对于match,源码的注释是这样写的:
Try to apply the pattern at the start of the string, returning
a Match object, or None if no match was found.
核心是:at the start of the string,也就是说是从头开始匹配,再遇上这个正则,那不就是说要匹配整个word是不是纯数字嘛,纯数字为match对象,否则为None,那我觉得还不如直接写个^\d+$让人容易理解一些,嗨。
接着就是下面那个if,为何要小于等于6?这里我也是觉得有问题的,我个人认为是7,我先解释下这个7的由来:
如果是纯数字表达的时间(当然我不知道什么情况下通过语音识别识别出来的时间会是纯阿拉伯数字),那么应该是20200720这样,这里就有8位数字了,那么6的由来呢?我猜测会不会是2020720这样,但是这样也就太不严谨了,毕竟为什么不把日期这一位的0去掉呢?
不过反正这个正则表达式以及下面的if语句最后的结果都是:清除掉非时间的纯数字。
再说下面的这串正则,我个人的理解是假设这样的实际情况出现的:“住到后天下午120块对吧?”,将后面这个表示价格的120给清洗掉。
之后就是判断是否相等,如果不等就递归,毕竟有可能把"号"替换成了"日",相当于是再一次确定这个真的是个日期对吧。
返回回去后通过相应的一个lambda表达式把None的取值过滤掉,这个方法也就到此为止了。
四、总结
以上两个方法是我个人认为逻辑上最难绕的两个方法,同时也是我觉得小的优化点比较多的内容,后面还有3个方法,将在下篇文章中讲解。下篇文章的快捷入口。
五、参考
[1]涂铭,刘祥,刘树春.Python自然语言处理实战核心技术与算法[M].机械工业出版社:北京,2018.4:63.