大家好,我是微学AI,今天给大家带来自然语言处理实战项目1-自定义的中文命名实体识别应用,本项目通过利用通用版的模型进行自定义的命名实体进行抽取,并提供可视化的抽取结果展示。
一、通用版模型选择的原因
本项目使用通用版的模型进行命名实体识别的原因:
1. 节省时间和人力:自己训练一个高质量的命名实体识别模型需要大量的时间和人力资源。使用通用版的模型可以节省这些资源。
2. 提高准确性:通用版的模型已经经过了大量的数据训练和验证,具有良好的准确性和稳定性。使用这些模型可以获得更高的识别准确率。
3. 适用范围广:通用版的模型可以处理各种语言和领域的命名实体识别任务,适用范围广。
4. 便于使用和维护:通用版的模型已经封装好了接口,使用起来非常方便。同时,由于这些模型是由大型组织和公司开发和维护的,可以获得较好的支持和更新。
二、中文命名实体识别
中文命名实体识别(NER)是一项NLP的任务,目的是从给定文本中识别出具有特定身份或特定意义的实体名称并标注其类型,如人名、地名、组织机构等。在实际应用中,NER对于文本信息的自动化加工和管理具有十分重要的作用,被广泛应用于文本分类、情感分析、信息提取、知识图谱等领域。
中文命名实体识别的原理基本相同于其他语言的NER,即通过建立模型,将文本中的语言结构和上下文信息作为特征,进行分类预测,识别和标注出文本中存在的实体名称和类型。常用的模型包括CRF、BiLSTM-CRF模型、 BERT模型等。
常见的中文命名实体模型包括:
CRF模型(条件随机场)
CRF是一种统计模型,将标注问题形式化为特征选择和分类问题。CRF基于训练数据自动选择最佳特征组合,具有鲁棒性和灵活性,适用于识别各种类型的命名实体。

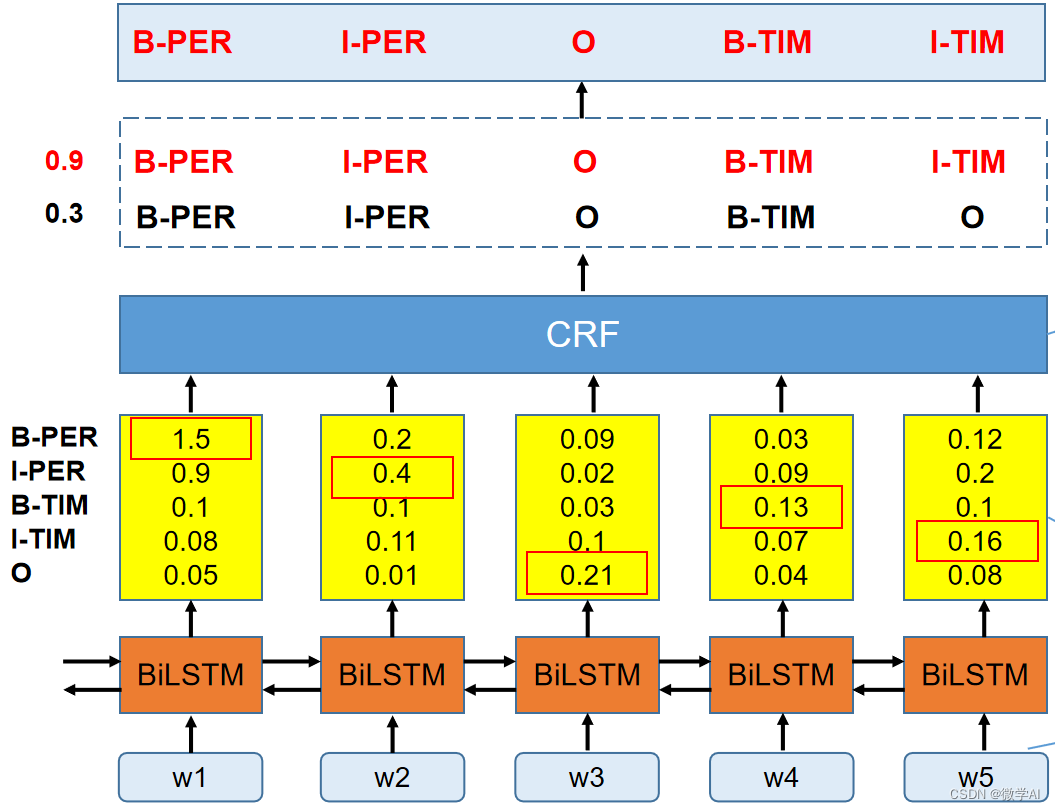
BiLSTM-CRF模型
双向长短时记忆网络-条件随机场(Bidirectional Long Short-Term Memory–Conditional Random Field,BiLSTM-CRF)是一种结合了深度学习和统计学习的方法,可以捕捉文本序列中的局部和全局特征,适用于识别复杂的命名实体。
BERT模型
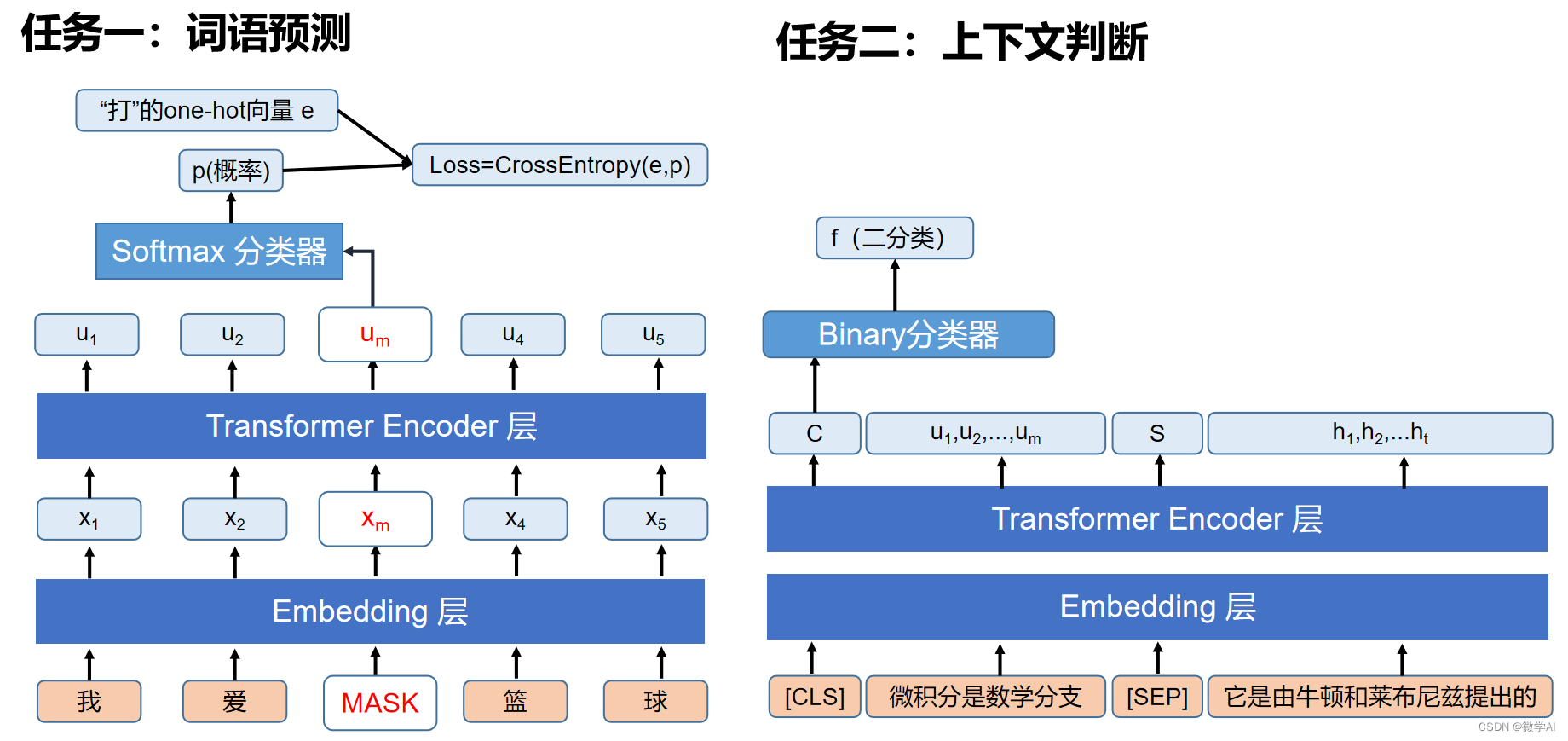
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer结构的深度双向预训练语言模型,它是Transformer模型中的编码部分,利用词语预测,上下文判断两大任务进行训练,并生成高质量的词向量表示。在中文命名实体识别任务中,可以通过对BERT进行微调,进一步提升模型的表现。
三、中文命名实体识别代码案例
本案例利用PaddleNLP框架来实现自定义中文命名实体识别,PaddleNLP是百度公司开源的自然语言处理工具包,旨在提供各种NLP任务(如命名实体识别、文本分类、情感分析、信息抽取、依存句法分析等)的高效、易用、且高度可定制化的解决方案。
PaddleNLP的特点和优势包括:
1.丰富的预训练模型
PaddleNLP提供了包括ERNIE、RoBERTa等一系列高质量的预训练模型,通过在大规模数据集上进行训练,可以提供具有高表现力的深度语言表示,并且基于PaddlePaddle框架,方便快速地使用这些预训练模型进行相关任务的Fine-tuning。百度前段时间,发布了“文心一言”模型,真是基于ERNIE3.0的基础训练的,目前这个大模型还在内测阶段,我们还不能用上。
2.多任务学习
PaddleNLP支持使用多任务学习来增强模型性能,也提供了多个任务之间的联合优化框架,以使得多个任务可以互相学习权重,有助于提高模型的泛化能力。
3.易用的API和高度可定制化
PaddleNLP提供了简洁易用的API,帮助开发者快速构建和训练自然语言处理模型,同时也支持多种特征提取、模型构建等高度可定制化的配置,使得模型能够更好地适应用户的需求和数据。
4.高性能和可扩展性
PaddleNLP底层基于PaddlePaddle深度学习框架,并且深度优化了计算图,在保证高性能的同时,支持了多种硬件加速,包括GPU、CPU等,同时也能够支持大规模分布式训练、以及在线学习。
现在我们就用PaddleNLP框架下的模型进行命名实体识别,普通的机器都可以跑起来的。
# coding=utf-8/gbk
from paddlenlp import Taskflow
schema = ['组织机构','成立时间','法人代表','股票代码'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema)
text = "微学智能有限公司是属于人工智能行业,成立于2022年5月15日,法人代表为微学AI。"
result = ie(text)[0]
print(result)运行结果:
{'组织机构': [{'text': '微学智能有限公司', 'start': 0, 'end': 8, 'probability': 0.9293754386128015}], '成立时间': [{'text': '2022年5月15日', 'start': 21, 'end': 31, 'probability': 0.9762881153890177}], '法人代表': [{'text': '微学AI', 'start': 37, 'end': 41, 'probability': 0.9077387385134443}]}实体识别可视化代码:
with open("entity.html", "w", encoding="utf8") as f:
head = '''<div class="entities" style="line-height: 3.5; direction: ltr"> <h3>实体分析结果:</h3></div>'''
for sch in schema:
if sch in result.keys():
for infor in result[sch]:
text =text.replace(infor['text'],
'''<mark class="entity" style="background: #7aecec; padding: 0.45em 0.6em; margin: 0 0.25em; line-height: 1; border-radius: 0.35em;">'''+infor['text']+'''
<span style="font-size: 0.8em; font-weight: bold; line-height: 1; border-radius: 0.35em; vertical-align: middle; margin-left: 0.5rem">'''+sch+
'''</span></mark>''')
maintext = '''<div class="entities" style="line-height: 2.5; direction: ltr">'''+text+'''</div>'''
f.write(head)
f.write(maintext)运行结果可生成entity.html文件,我们可以通过打开entity.html文件查看网页版的实体识别结果。

可视化的网页呈现,我们可以清晰地看到识别结果的实体所在的位置,便于后续网页的开发与运用。大家有什么问题,后续可以交流合作,请持续关注,谢谢。