文章目录
前言
自然语言处理(Natural Language Processing, NLP)是一门研究计算机如何理解、处理、生成人类语言的学科。近年来,NLP领域急速发展,如何高效地从海量文本中抽取出有用的信息成为了一个迫切的问题,在这个问题中命名实体识别任务引起了广泛关注。命名实体识别(Named Entity Recognition, NER)是指在大规模文本数据中识别出命名实体的过程。命名实体通常是指具有特定名称或角色的实体,如人名、地名、组织、日期等。
PyTorch LSTM模型是在深度学习领域中越来越流行的序列模型之一,它被广泛应用于自然语言处理任务中。利用这些模型可以快速训练出高精度的命名实体识别系统,解决大规模文本数据中的抽取问题。
在本次实验中,我们将使用PyTorch LSTM模型来实现命名实体的高精度识别,并对模型进行调参和优化,最终得到一个性能很高的命名实体抽取系统。希望这个实验可以进一步拓展我们对PyTorch的了解,同时提高我们在命名实体识别任务上的应用水平。
本篇文章主要分享的是实验预备(知识学习)部分,具体实验过程及代码请看作者的另一篇(实践学习):
一、LSTM是什么?
LSTM(Long Short-Term Memory)模型是一种递归神经网络(Recurrent Neural Network, RNN),是针对传统的RNN模型中长期依赖关系难以捕捉的问题提出的解决方案。
传统的RNN模型在处理长序列时可能会出现梯度消失或梯度爆炸的问题,导致无法学习到长期依赖关系,而LSTM通过引入门限参数的方式来调节记忆与遗忘,从而能够有效地解决这个问题。
LSTM的基础单元由三个门组成:输入门、输出门和遗忘门,见下图。它们可以控制信息的流动以及信息的“遗忘”或“保留”。此外,LSTM还有一个称为单元状态(cell state)的特殊状态,也叫细胞状态,用于存储长期的记忆信息。
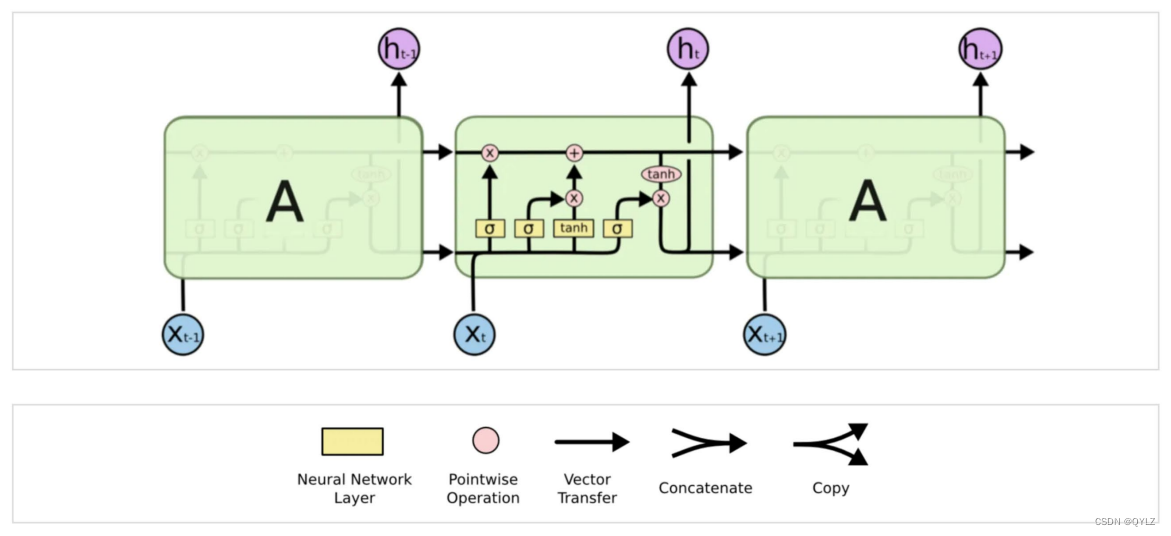
具体而言,在每个时间步骤中,LSTM会首先根据当前的输入和上一个时间步骤的状态,计算出本时间步骤的以下三个门的状态:
- 输入门:控制哪些信息需要加入到单元状态中;
- 遗忘门:控制哪些信息需要从单元状态中遗忘掉;
- 输出门:控制从单元状态中输出哪些信息。
根据上述门的状态和当前的输入,LSTM可以计算更新后的单元状态,并根据输出门的状态进行输出。
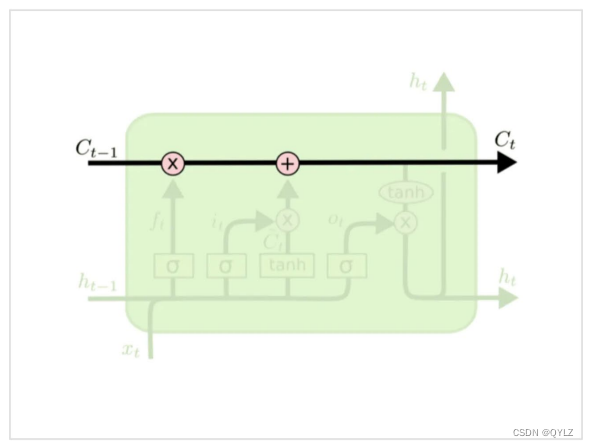
1.单元状态
在LSTM中,cell state是由上一个时间步骤的cell state、输入门和遗忘门控制的。对于当前时间步骤,遗忘门将会决定哪些信息需要从cell state中丢弃,而输入门则决定哪些信息需要新加入到cell state中。设计为可以保留和传递信息,因此有助于解决传统RNN模型中无法处理长期依赖关系的问题。
2.门
在LSTM中,门限(Gate)是由一个sigmoid层和一个逐点乘法操作的组合。
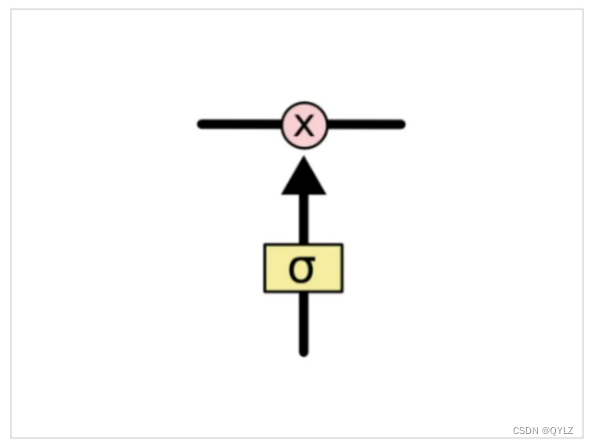
LSTM中的gate由于引入了sigmoid神经元,可以实现了对信息的有选择性地存储、遗忘和输出,从而让模型可以更加精准地处理序列数据。同时,由于门限的存在,使得LSTM可以有效地抵抗长期依赖问题,并且可以更好地捕捉输入序列中的重要特征。
a.Sigmoid函数
该函数也叫挤压函数,sigmoid函数是一种常见的激活函数,用来增强神经元之间的非线性关系,通常用于神经网络中。
作用:sigmoid函数将任意实数映射到[0,1]区间内的某个值,使其具有一定概率解释的能力。当输入值趋近正无穷时,sigmoid函数的输出值接近于1;当输入值趋近负无穷时,sigmoid函数的输出值接近于0。在输入值为0附近,sigmoid函数的输出值约等于0.5。
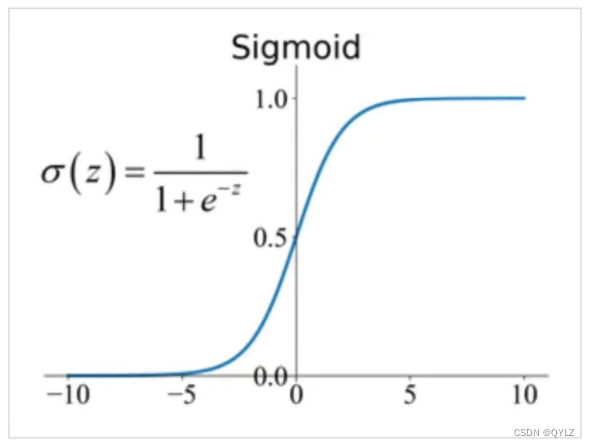
(1)数学表达式为:
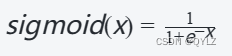
其中,x是输入值,e是自然对数的底数。
(2)特点:
- 输出值范围为[0,1]:sigmoid函数的输出总是在[0,1]之间的值,并且在输入非常大或非常小的时候趋近于边界。
- 具有连续可导性:由于sigmoid函数是一个光滑、可微的函数,因此可以方便地计算梯度和更新权重。
- 容易产生梯度消失的问题:当输入值非常大或非常小时,sigmoid函数的导数将接近于0,导致反向传播过程中的梯度极度减小,从而导致梯度消失或爆炸的问题。
b.逐点乘法
逐点乘法(element-wise multiplication)是指对两个矩阵/向量/张量中的对应元素进行相乘操作,得到一个由相应位置元素积构成的新矩阵/向量/张量。在神经网络中,逐点乘法通常用于实现一些重要的运算,例如将LSTM中记忆单元状态与输入数据进行结合等。
(1)下面以两个向量为例,介绍逐点乘法的计算过程:

(2)特点:

在神经网络中,逐点乘法常用于实现向量/矩阵元素级别的计算,比如卷积、池化、LSTM中门限值计算等场景。逐点乘法能够有效地处理矩阵各位置的信息,并且由于其具有可交换和分配性,因此可以更加灵活地运用到神经网络中的多个部分,从而提高模型的表达能力和效率。
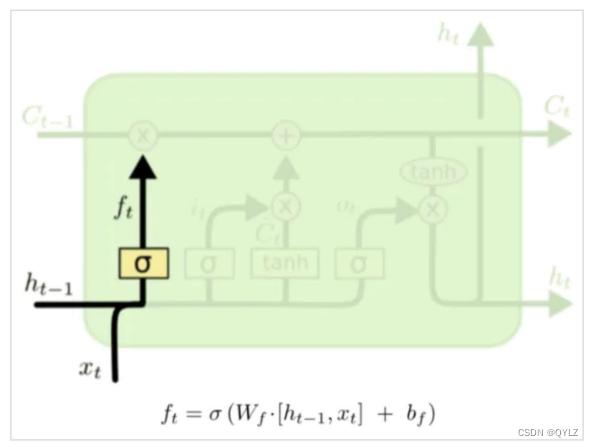
3.遗忘门
遗忘门负责决定何种旧信息应该从cell state中被遗忘。
原理:它接收当前时间步骤的输入和上一个时间步骤的隐藏状态作为输入,通过一个sigmoid激活函数将这些输入信息转化成一个0~1之间的向量。这个向量中的每个元素表示是否选择遗忘cell state中相应位置的信息。如果一个元素的值接近1,则代表这个位置的信息很重要,应当予以保留;反之如果一个元素的值接近0,则代表这个位置的信息已经过时,可以忽略。
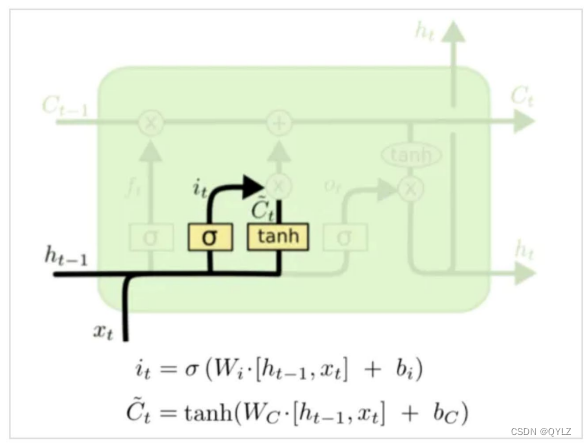
4.输入门
输入门负责决定何种新信息应该被添加到cell state中。
原理:它接收当前时间步骤的输入和上一个时间步骤的隐藏状态作为输入,通过一个sigmoid激活函数将这些信息转化成一个0~1之间的向量。这个向量中的每个元素表示是否选择把当前输入与上一个时间步骤的隐藏状态相应位置的信息加入到cell state中。如果一个元素的值接近1,则代表这个位置的信息非常重要,应当予以保留;反之如果一个元素的值接近0,则代表这个位置的信息对于当前时间步骤并不重要,可以忽略。
a.tanh函数
tanh函数是双曲正切函数(hyperbolic tangent function)的缩写,是一种常见的激活函数,用来增强神经元之间的非线性关系,通常用于神经网络中。
作用:tanh函数将任意实数映射到[-1,1]区间内的某个值,比sigmoid函数的输出范围更大。当输入值趋近正无穷时,tanh函数的输出值接近于1;当输入值趋近负无穷时,tanh函数的输出值接近于-1。在输入值为0附近,tanh函数的输出值约等于0。
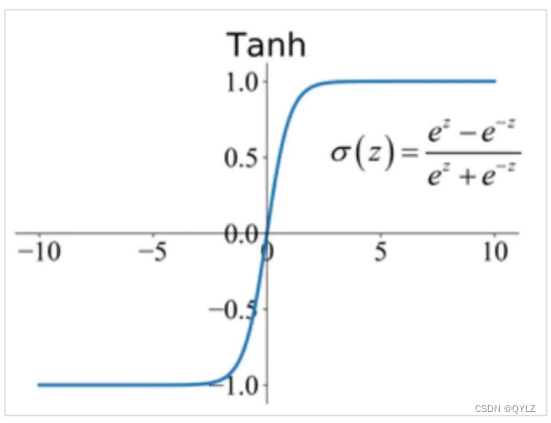
(1)数学表达式:
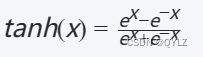
其中,x是输入值,e是自然对数的底数。
(2)特点:
-
输出值范围为[-1,1]:tanh函数的输出总是在[-1,1]之间的值,并且在输入非常大或非常小时趋近于边界。
-
具有连续可导性:由于tanh函数是一个光滑、可微的函数,因此可以方便地计算梯度和更新权重。
-
0中心性:tanh函数在输入值为0附近取得最大值,因此可以使神经元在正负方向上有相同的响应能力,从而避免了一些问题(比如梯度消失)。
与sigmoid函数不同的是,tanh函数的输出值有符号,具有更强的表达能力,可以处理包含负数的数据。但是,tanh函数也存在梯度消失的问题,在深层神经网络中容易产生梯度消失或爆炸的情况。
除了作为激活函数外,tanh函数还可以用于其它计算任务,如生成均值为0、方差为1的随机数(即标准正态分布的采样)等。
b.更新细胞
更新细胞是实现长期记忆的关键部分,是由三个门控单元:输入门(input gate)、遗忘门(forget gate)和输出门(output gate)共同控制的。这三个门控单元根据输入信号、上一个时间步的隐藏状态以及细胞状态的状态值来决定信息的传递和保留。
具体地,在LSTM中,更新细胞的计算过程如下:



最后得到的新细胞的信息包括旧细胞的部分信息和候选细胞的部分信息。
5.输出门
输出门控制LSTM在当前时间步骤是否应该输出cell state的内容。
原理:它接收当前时间步骤的输入和上一个时间步骤的隐藏状态以及当前时间步骤更新后的cell state作为输入,通过一个sigmoid激活函数将这些信息转化成一个0~1之间的向量。这个向量中的每个元素表示是否选择从cell state中相应位置的信息输出。如果一个元素的值接近1,则代表这个位置的信息非常重要,应当予以输出;反之如果一个元素的值接近0,则代表这个位置的信息对于当前时间步骤并不重要,可以忽略。
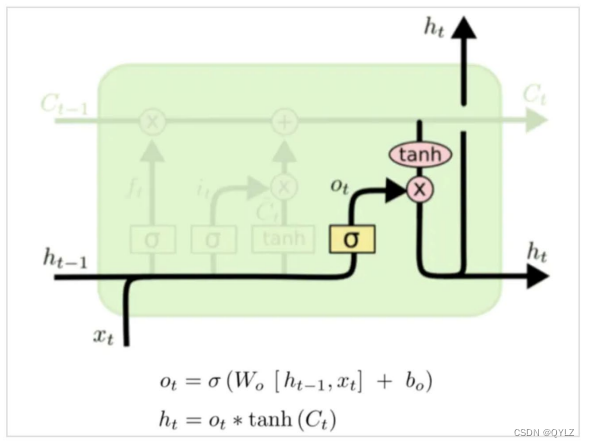
具体来讲,在每个时间步骤中,LSTM都有如下的计算过程:
(1)计算输入门:将当前输入和上一个时间步骤的隐藏状态作为输入,经过一个sigmoid激活函数得到一个0~1之间的值向量。这个向量中的每个元素表示是否选择把当前输入与上一个时间步骤的隐藏状态相应位置的信息加入到cell state中。
(2)计算遗忘门:将当前输入和上一个时间步骤的隐藏状态作为输入,经过一个sigmoid激活函数得到一个0~1之间的值向量。这个向量中的每个元素表示是否选择遗忘cell state中相应位置的信息。
(3)计算候选状态:将当前输入和上一个时间步骤的隐藏状态作为输入,经过一个tanh激活函数得到一个-1~1之间的向量。这个向量中的每个元素表示在当前时间步骤应该添加到cell state中的信息。
(4)计算新的cell state:通过将当前时间步骤的候选状态与上一个时间步骤的cell state相应位置的信息按元素加权合并,再根据输入门和遗忘门的值更新cell state。
(5)计算输出门:将当前输入和上一个时间步骤的隐藏状态作为输入,经过一个sigmoid激活函数得到一个0~1之间的值向量。这个向量中的每个元素表示是否选择从cell state中相应位置的信息输出。
(6)计算当前时间步骤的输出:通过将当前时间步骤的cell state进行tanh激活,并根据输出门的值筛选部分元素作为本时间步骤的输出。
二、什么是命名实体识别
命名实体识别(Named Entity Recognition,简称NER)是自然语言处理领域的一个重要任务。它主要是从文本中识别出与组织、人物、地点等实体相关的名称,并按照预定义好的类别对其进行标注。
1.原理
NER的主要目标是识别文本中涉及的实体,并对其进行分类。在预处理阶段,需要对文本进行分词、词性标注等基础工作。然后,利用机器学习或者深度学习等方法,对于每个单词,判断它是否可能表示一个实体。如果是,则确定它的类别,并将其标注出来。
常用的NER模型有两种:
- 基于规则的模型
- 基于机器学习的模型。
基于规则的模型通常依赖于语言学知识和规则列表等先验知识,手动构建正则表达式、模板匹配等方式进行命名实体识别。基于机器学习的模型通常不需要手动构建规则,而是通过训练数据和特征提取技术学习从输入文本中自动推断出实体名称和类别信息。例如,卷积神经网络(CNN)、循环神经网络(RNN)和转换器(Transformer)等深度学习模型。
2.实现方法
基于机器学习的NER模型通常由三部分组成:特征提取、标注策略和分类器。
a.特征提取
特征提取是机器学习算法的关键步骤,可以将原始文本转换为计算机可处理的特征向量。在NER任务中,常见的特征包括:
- 文本词向量:通过将文本中的每个单词映射为一个高维的向量来表示。可以使用预训练的词向量模型,如Word2Vec、GloVe等
- 词性标记:对文本中的词进行词性标注,如名词、动词、形容词等
- 形态学特征:如前缀、后缀、词根等
- 上下文信息:即单词与上下文中其他单词之间的关系,如 n-gram(包含n个连续单词的部分序列)、句子特征等
b.标注策略
在标注策略中,需要选择合适的类别集合、标注方式和标注标准。一般来说,命名实体的类别集合包括人名、地名、机构名称、时间、日期等。标注方式常用的有IOB标注法,即将每个实体区分为B(beginning)、I(in)和O(out)三种标签。其中,B标签表示一个实体的开始,I标签表示实体的中间部分,O标签表示非实体词。
BIO标注法:
- B(Beginning)表示一个实体的开头
- I(Inside)表示实体的内部
- O(Others)表示不属于任何实体
例如:在句子“Bill Gates is the founder of Microsoft”中,如果我们想识别人名和机构名,可以对其中的一些单词进行BIO标注:
- Bill - B-PER (表示 Bill 是一个人名的开始)
- Gates - I-PER (表示 Gates 是一个人名的内部)
- Microsoft - B-ORG (表示 Microsoft 是一个机构名的开始)
因此,整个句子的BIO标注为“B-PER I-PER O O B-ORG”。
c.分类器
在NER任务中,分类器主要用于确定特征向量的类别标签。常用的分类器包括朴素贝叶斯分类器、支持向量机、随机森林和神经网络等。其中,神经网络(如LSTM、CRF等)在NER任务中被广泛应用,取得了较好的效果。
批处理(Batch Processing)
批处理(Batch Processing)是一种数据处理技术,它通过将大量的数据一次性送入系统中进行计算或处理,以降低数据处理的时间和成本。在机器学习中,批处理通常用于训练模型,即将多个样本一起输入到模型中进行训练,以加快训练速度和优化模型性能。
原理:利用现代计算机的并行计算能力,将多个数据样本一起送入模型中进行计算,以充分利用CPU和GPU的计算资源。具体而言,我们可以将多个数据样本打包成一个“批”(Batch)进行处理,每个批包含多个数据样本和对应的标签信息,然后将这个批作为模型的输入,同时计算损失函数和梯度,并更新模型参数。
注意:批处理的大小(Batch Size)是可以调整的,并且通常会根据具体任务和计算资源的不同进行调整。如果批处理的大小太小,将会引起计算资源的浪费,因为CPU和GPU需要频繁地将数据从内存中读取到显存中。而如果批处理的大小太大,可能会导致显存不足或者过拟合等问题。因此,合理地调整批处理的大小可以帮助我们充分利用计算资源,加快模型训练的速度,并且优化模型的性能。
三、实验过程及代码
具体过程请看下面文章(实践学习):
https://blog.csdn.net/weixin_56242678/article/details/130867899
总结
此篇主要是分享了一些有关实验的预备知识学习,作者也在学习中,如有讲解不清楚的地方,还请大家给予指正,如果喜欢此次内容,希望可以给个三连,谢谢观看。