文章目录
前言
此篇文章是有关基于LSTM的命名实体识别实验的实验过程及具体代码讲解。
实验过程
实验过程包括数据预处理、特征提取、模型设计、训练和评估、预测等多个部分。
1.数据预处理
a.数据集结构如下:

数据集分为训练集(train)、测试集(test)、验证集(val),以及词典(words.txt)。其中train、test、val均包含一个文本数据集(sentences.txt)和一个BIO标注数据集(labels.txt)
b.加载数据集
def load_data(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
data = [line.strip().split() for line in f.readlines()]
return data
其中,data_path为你的数据集地址
c.加载词典
with open('词典地址', 'r', encoding='utf-8') as f:
word2id = {
line.strip():i for i, line in enumerate(f.readlines())}
d.使用<PAD>标识符将所有序列处理成同样高度
//注意要设置序列的最长长度max_len
def pad_sequence(seq, max_len, padding_token):
seq += [padding_token] * (max_len - len(seq))
return seq[:max_len]
其中,seq为文本数据集中的文本,即一句句话,max_len为序列最长长度,即每句话的最长长度,超过的部分自动截断,padding_token为你自己设置的填充字符。
e.将标签序列转换为数字序列,以便于模型训练
def label2id(label, label_map):
label_set = set(label)
return [label_map[l] if l in label_map else label_map['<PAD>'] for l in label]
其中,label为你的标签数据集,label_map为你自己定义的BIO标注字典。
2.模型构建
a.建立词嵌入层
vocab_size = len(word2id)
embedding = nn.Embedding(vocab_size, embedding_size, padding_idx=word2id[pad_token])
注意:此步骤可以通过加载预训练词向量(例如,GloVe)进行优化。
b.建立LSTM模型
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embedding_size, hidden_size, num_layers, num_classes):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.lstm = nn.LSTM(embedding_size, hidden_size, num_layers, batch_first=True, bidirectional=True)
self.fc = nn.Linear(hidden_size*2, num_classes) # *2是因为双向LSTM
def forward(self, x):
x = self.embedding(x)
out, _ = self.lstm(x)
out = self.fc(out)
return out
注意:此步骤可以通过加入Dropout层和添加注意力机制进行优化。
c.模型初始化
model = LSTMModel(vocab_size, embedding_size, hidden_size, num_layers, len(label_map))
d.定义损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=str)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
其中,str为你所要排除的干扰符号。
注意:此步骤可以通过使用ReduceLROnPlateau()调整学习率,以便保证模型的准确率。
3.模型训练与评估
a.模型训练
代码比较简单,与平常模型训练类似,这里只写思路:
(1)定义epoch次数和批处理大小batch_size
(2)把处理好的数据输入定义好的LSTM模型中
(3)定义前向传播、损失计算、反向传播
(4)利用验证集进行模型验证,可以用torch.no_grad()来进行验证
(5)计算输出验证集的损失值和模型准确率
val_loss = total_loss / len(new_val_sent)
val_acc = total_num_correct / (len(new_val_sent)*max_len)
其中val_loss为损失值计算,val_acc为准确率计算。
b.模型评估
此次模型训练(epoch=10)后得到的验证集损失值和准确率如下:
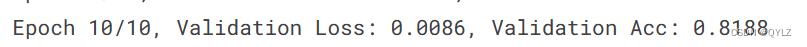
用训练得到的LSTM模型对测试集进行预测处理结果如下:

由结果可知,模型在经过简单训练后预测的结果准确率是0.82左右,还是不错的。
总结
本次实验过程没有对模型进行优化,但是还是有很多方面值得优化的,下面是一些修改建议:
(1)使用预训练词向量。预训练的词向量具有更好的语义表示能力,并且可以在训练数据有限的情况下提高模型性能。PyTorch已经内置了一些流行的预训练词向量,如GloVe和fastText。可以使用torchtext库加载这些预训练词向量。
(2)加入Dropout层。Dropout层可以随机删除一些神经元,以避免过拟合,并提高模型泛化性能。
(3)使用注意力机制。在文本分类任务中,注意力机制可以帮助模型选择关键词汇,从而进一步提高性能。可以使用nn.MultiheadAttention或者自行定义注意力层来实现。
(4)调整学习率。学习率的选择对模型训练的效果影响很大。可以采用自适应算法(如Adam)或手动调整。推荐使用PyTorch的ReduceLROnPlateau回调函数自动降低学习率。
(5)模型融合。可以使用多个模型的预测结果平均或加权平均来提高性能。可以使用PyTorch的Ensemble模块实现。
以上就是本次实验的所有内容,希望对大家有所帮助与启发,也欢迎大家来评论区进行讨论,作者也在学习中,如有讲解不清楚或者错误的地方,还请大家指正,如果喜欢此次内容,希望可以给个三连,谢谢观看。