命名实体识别(NER)是在自然语言处理中的一个经典问题,其应用也极为广泛。比如从一句话中识别出人名、地名,从电商的搜索中识别出产品的名字,识别药物名称等等。传统的公认比较好的处理算法是条件随机场(CRF),它是一种判别式概率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或是生物序列。简单是说在NER中应用是,给定一系列的特征去预测每个词的标签。如下图:
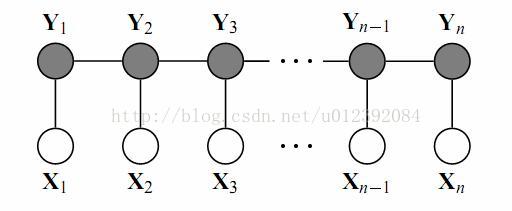
X我们可以看做成一句话的每个单词对应的特征,Y可以看做成单词对应的标签。这里的标签就是对应场景下的人名、地名等等。重点在X的理解上面,什么是特征呢?通常我们都会取的特征是词性,如果名词、动词… 但是有人会反问,知道了词性就能学习出标签吗?显然是不够的,我们可能需要更多的特征来完成我们的学习。但是这些特征需要我们根据不同的场景去人工的抽取,比如抽取人名的特征我们往往可能看看单词的第一个字是不是百家姓等等。所以更多严谨的CRF的图应该如下:
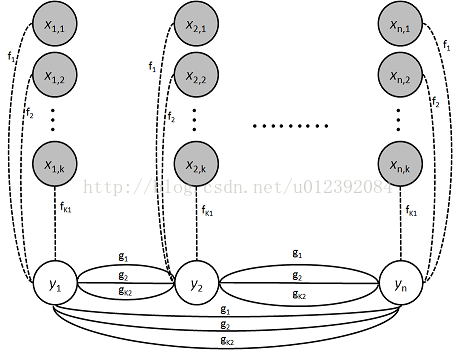
至于y之间的连线请参考CRF算法的详细内容。接下来会更注重用深度学习的方法来解决NER问题。
看了上图有的人则会有疑惑了,这个特征要怎么提取呢?如何知道提取出来的特征是有效的呢?要提多少个特征才好呢?的确,特征工程确实是一个麻烦的问题,关于特征的提取也大都是根据经验和拍脑门想出来的,这整个过程很是麻烦。幸运的是现在深度学习大红大紫,其原因除了它的效果卓越之外还免去了我们手工提取特征的烦恼,以下将会讲解本人Github上的代码思路与实现。
本代码用TensorFlow实现了双向循环神经网络(Bi-RNN)+ 条件随机场(CRF)在NER上的应用。了解深度学习的人都知道,我们把数据放入神经网络中然后输出我们想要的结果,无论想要处理的问题是分类、回归或者是序列的问题,其本质就是通过神经网络学习出特征然后根据特征求得结果。这不就正是我们需要的吗?我们只要让神经网络替我们把特性选好,然后我们只要简单的把特征放到CRF里不就好了吗?这就是整个程序的本质。
知道了本质我们需要克服的困难也很多,接下来我们一一来解决。
- 如何把词转换成神经网络能接受的数据?
神经网络只接受数字,不接受字符串,所以我们需要用工具把词转换成为词向量,这个工具可以是gensim word2vec、glove等等。训练的数据最好是要有个庞大的数据集,比如从网上爬取下来的新闻然后用这些数据来训练词向量。如果就用已有的数据训练行不行呢?或者干脆不训练,随机初始化这些词向量行不行呢?答案是:可以。但是解决不了下面这个问题。
2. 如何处理训练数据中没有见过的词?
我们之所以需要用庞大的新闻数据来预训练词向量的原因就是为了克服训练数据量小的问题。因为人力有限,我们不可能有很大的标记过的数据,如果在测试样例中出现了我们没有标记过的词,那么显然会影响NER结果。然后word2vec的用处就是将相似的词的“距离”拉的很近(由于word2vec又是一个很大的话题,这里不拓展讨论啦),这样可以一定程度上减少未出现词的影响。
整个流程图如下:
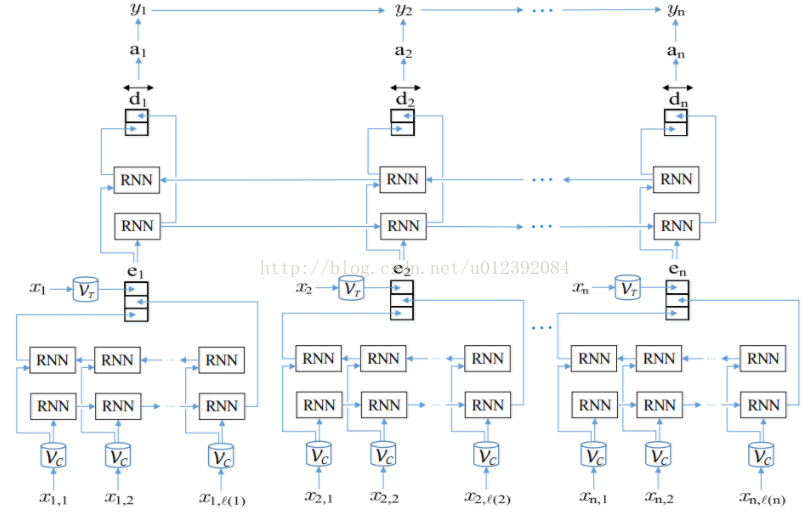
更具体的实现在 https://github.com/shiyybua/NER 中有中文注释,其使用简单也可以不需要太关注细节。