版权声明:转载请注明出处 https://blog.csdn.net/zhouchen1998/article/details/88912145
词性标注与命名实体识别
- 词性标注
- 词性是词汇基本的语法属性,通常称为词类。词性标注是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程。例如,表示人、地点、事物以及其他抽象概念的名称即为名词,表示动作或者状态变化的为动词,描述或修饰名词属性、状态的词为形容词。
- 在中文中,一个词的词性很多时候都是不固定的,一般表现为同音同形的词在不同的场景下,其表示的语法属性截然不同,这为词性标注带来了很大的困难;但是另一方面,从整体上看,大多数词语尤其是实词,一般只有一到两个词性,且其中一个词性的频率远大于另一个,即使每次将高频词性作为词性选择进行标注,准确率也在80%以上。
- 词性标注最简单的方法是从语料库中统计每个词所对应的高频词性,将其作为默认词性,但这样显然还有提升空间。目前主流的是如同分词一样,将句子的词性标注为一个序列标注问题来解决,那么分词中常用的手段,如隐含马尔可夫模型、条件随机场模型(CRF)等皆可以在标注任务中使用。
- 词性标注具有一定的规范,什么表示表示什么,如’n’表示名词,目前没有统一规范,主要有北大词性标注集和宾州词性标注集两种,各有千秋。
- jieba是词性标注不错的选择。
- 具体为jieba.posseg
- 命名实体识别
- 与自动分词、词性标注一样,命名实体识别也是自然语言处理的基础任务,是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。其目的是识别语料中人名、地名、组织机构名等命名实体。
- 由于这些命名实体数量不断增加,不可能在词典穷尽列出,且其构成方法具有各自规律性,因此,通常把对这些词的识别在词汇形态处理(如汉语切分)任务中独立处理,称为命名实体识别(NER)。NER研究分为三大类(实体类、时间类、数字类)和七小类(人名、地名、组织机构名、时间、日期、货币和百分比)。由于数量、时间、日期、货币等实体识别通常可以采用模式匹配的方式取得较好的结果,相比之下人名。地名。组织机构名较为复杂,近年来的研究主要针对这些。
- 命名实体识别当前并不是一个大热的研究课题,因为学术界部分认为这是一个已经解决的问题。但是,不少人认为通用识别准确率很低。
- 同样的,中文命名实体识别难度更大,主要原因如下。
- 各类命名实体数量众多。
- 命名实体构成规律复杂。
- 嵌套情况复杂。
- 长度不确定。
- **其实,除了分词,NLP每个子任务的划分方法基本上都是基于规则、基于统计和两者结合的方法。**CRF往往有着更好的效果。
- CRF++包是个不错的选择。
- 实战
- 日期识别
- 根据用户电话语音识别出文本,解析文本提到的相关日期。
- 代码
-
import re from datetime import datetime, timedelta from dateutil.parser import parse import jieba.posseg as psg # 参考字典,用于文本转数字 UTIL_CN_NUM = { '零': 0, '一': 1, '二': 2, '两': 2, '三': 3, '四': 4, '五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9 } UTIL_CN_UNIT = {'十': 10, '百': 100, '千': 1000, '万': 10000} def cn2dig(src): """ 转为数字 :param src: :return: """ if src == "": return None m = re.match(r"\d+", src) if m: # 若匹配到数字 return int(m.group(0)) # 若只有文本,则进行文本转换 rsl = 0 unit = 1 # 倒序查找 for item in src[::-1]: if item in UTIL_CN_UNIT.keys(): unit = UTIL_CN_UNIT[item] elif item in UTIL_CN_NUM.keys(): num = UTIL_CN_NUM[item] rsl += num * unit else: return None if rsl < unit: rsl += unit return rsl def year2dig(year): """ 转为数字 :param year: :return: """ res = '' for item in year: if item in UTIL_CN_NUM.keys(): res = res + str(UTIL_CN_NUM[item]) else: res = res + item m = re.match(r"\d+", res) if m: if len(m.group(0)) == 2: return int(datetime.today().year/100)*100 + int(m.group(0)) else: return int(m.group(0)) else: return None def parse_datetime(msg): """ 解析日期 :param msg: :return: """ if msg is None or len(msg) == 0: return None try: dt = parse(msg, fuzzy=True) return dt.strftime('%Y-%m-%d %H:%M:%S') except Exception as e: m = re.match( r"([0-9零一二两三四五六七八九十]+年)?([0-9一二两三四五六七八九十]+月)?([0-9一二两三四五六七八九十]+[号日])?([上中下午晚早]+)?([0-9零一二两三四五六七八九十百]+[点:\.时])?([0-9零一二三四五六七八九十百]+分?)?([0-9零一二三四五六七八九十百]+秒)?", msg) if m.group(0) is not None: res = { "year": m.group(1), "month": m.group(2), "day": m.group(3), "hour": m.group(5) if m.group(5) is not None else '00', "minute": m.group(6) if m.group(6) is not None else '00', "second": m.group(7) if m.group(7) is not None else '00', } params = {} for name in res: if res[name] is not None and len(res[name]) != 0: tmp = None if name == 'year': tmp = year2dig(res[name][:-1]) else: tmp = cn2dig(res[name][:-1]) if tmp is not None: params[name] = int(tmp) target_date = datetime.today().replace(**params) is_pm = m.group(4) if is_pm is not None: if is_pm == u'下午' or is_pm == u'晚上' or is_pm =='中午': hour = target_date.time().hour if hour < 12: target_date = target_date.replace(hour=hour + 12) return target_date.strftime('%Y-%m-%d %H:%M:%S') else: return None def check_time_valid(word): """ 确认时间的合法性 :param word: :return: """ m = re.match(r"\d+$", word) if m: if len(word) <= 6: return None word1 = re.sub(r'[号|日]\d+$', '日', word) if word1 != word: return check_time_valid(word1) else: return word1 def time_extract(text): """ 提取时间 :param text: :return: """ time_res = [] word = '' keyDate = {'今天': 0, '明天': 1, '后天': 2} for k, v in psg.cut(text): if k in keyDate: if word != '': time_res.append(word) word = datetime.today() + timedelta(days=keyDate.get(k, 0)) print(word) word = word.strftime('%Y{}%m{}%d{}').format("年", "月", "日") elif word != '': if v in ['m', 't']: word = word + k else: time_res.append(word) word = '' elif v in ['m', 't']: word = k if word != '': time_res.append(word) result = list(filter(lambda x: x is not None, [check_time_valid(w) for w in time_res])) final_res = [parse_datetime(w) for w in result] return [x for x in final_res if x is not None] if __name__ == '__main__': text1 = '我要住到明天下午三点' print(text1, time_extract(text1), sep=':') text2 = '预定28号的房间' print(text2, time_extract(text2), sep=':') text3 = '我要从26号下午4点住到11月2号' print(text3, time_extract(text3), sep=':') text4 = '我要预订今天到30的房间' print(text4, time_extract(text4), sep=':') text5 = '今天30号' print(text5, time_extract(text5), sep=':')
-
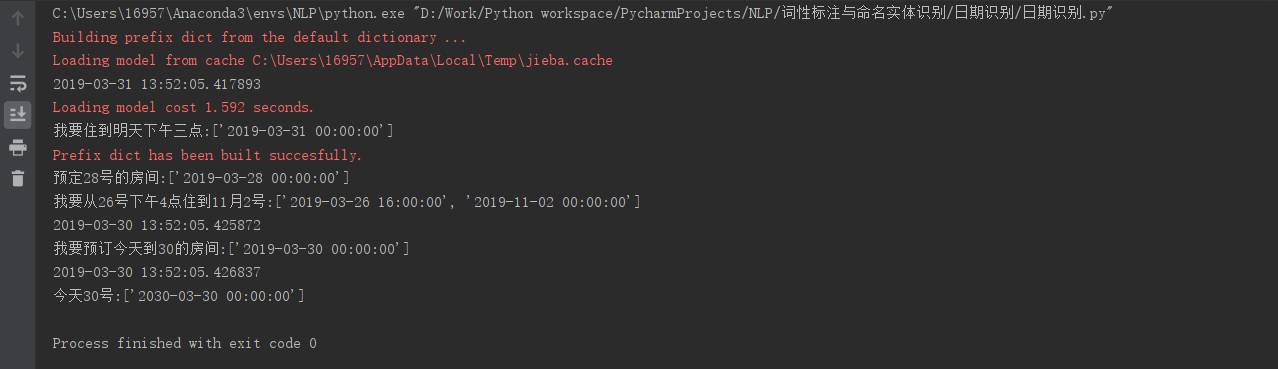
- 效果
- 地名识别
- 安装CRF++。(使用源码包)
- 使用CRF++
- 确定标签体系
- 标记为"B"、“E”、“M”、“S”、"O"中一个
- 语料数据处理
- 按照指定token格式
- 语料数据为1998年人民日报分词数据集
- 见corpus_handler.py
- 特征模板设计
- 见template文件
- 模型训练和测试
- 使用命令行
crf_learn -f 4 -p 8 -c 3 template train.txt model- `crf_test -m model test.txt > test.rst
- 使用命令行
- 模型使用
- 确定标签体系
- 日期识别
- 补充说明
- 参考书为《Python自然语言处理实战》
- 对书中的一些错误做了纠正(原书使用Jupyter Notebook,我使用Pycharm作为开发环境,推荐Jupyter),并对代码添加了一定注释
- 具体数据集和代码见我的Github,欢迎star或者fork
- 到此,中文分词技术、词性标注与命名实体识别这词法层面的三个基础已经介绍完毕。