一、什么是监督学习?
监督学习是指:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。这就要求学习算法是在一种“合理”的方式从一种从训练数据到看不见的情况下形成。
二、监督学习分类
数据集中的每个样本有相应的“正确答案”,根据这些样本做出预测,分有两类:回归问题和分类问题
1.回归问题(Regression Problem):
对已经存在的点(训练数据)进行分析,拟合出适当的函数模型y=f(x),这里y就是数据的标签,而对于一个新的自变量x,通过这个函数模型得到标签y。
例如:预测房价,根据样本集拟合出一条连续曲线。
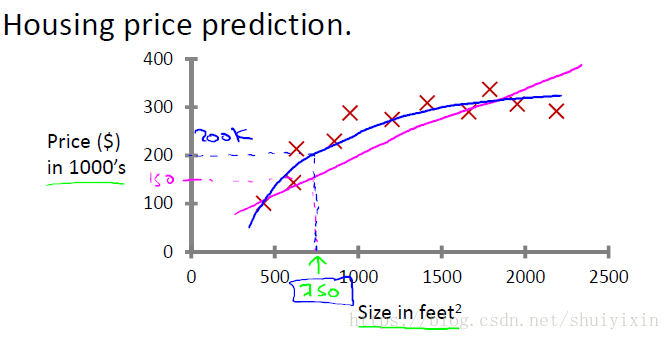
2.分类问题(Classification Problem):
训练数据是特征向量与其对应的标签,同样要通过分析特征向量,对于一个新的向量得到其标签。回归分析与分类区别其实就是数据的区别就是回归是针对连续数据,分类是针对离散数据。
例如:根据肿瘤特征判断良性还是恶性,得到的是结果是“良性”或者“恶性”,是离散的。
