版权声明: 本文为博主原创文章,未经博主允许不得转载 https://blog.csdn.net/u011467621/article/details/48243135
> 翻译总结by joey周琦
希望把自己阅读到的,觉得有营养的论文,总结笔记和自己想法,留给自己,也分享给大家。因为英文论文中一些专有,有难度的词句,会给出英文原文。
这篇文章总结了有关机器学习的12条重要,简单,明了的经验。本文面对分类问题总结,但不限于分类问题。
学习=模型+评估+优化
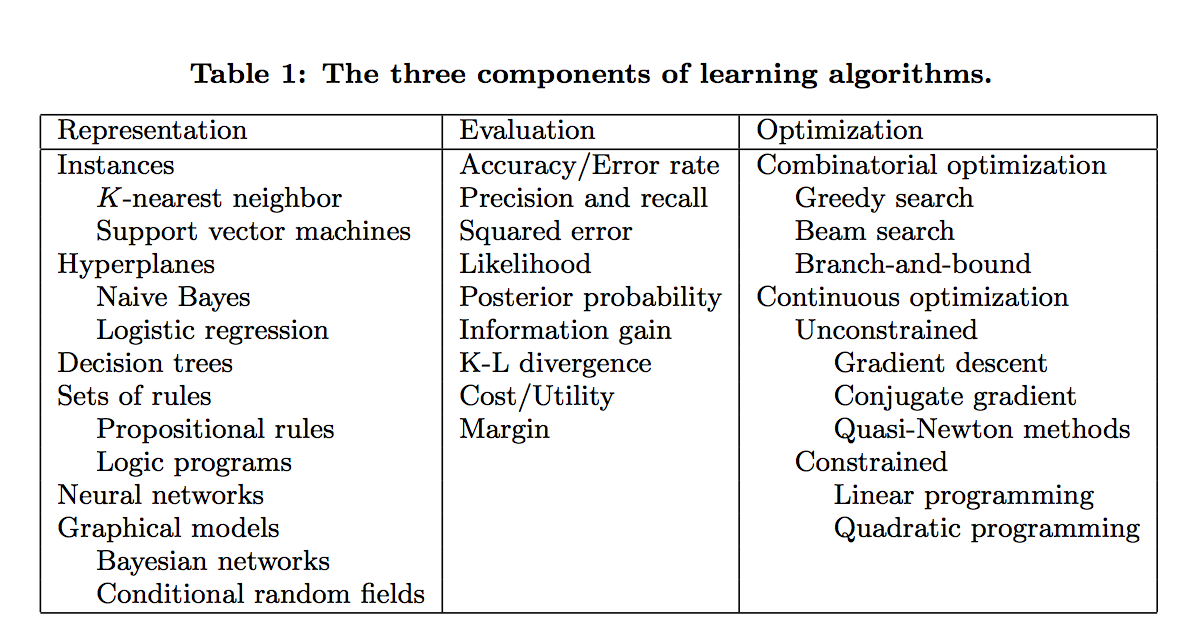
Learning = representation + evaluation + optimization。- representation(模型): 对于一个学习算法选择一个模型,相当于选择一个分类器的集合,这个集合可称为假设空间,空间中的分类器被认为是可以学习的。常见的模型有:KNN, SVM, Naive Bayes, 逻辑回归LR, 决策树等等。
- evaluation (评估): 也就是目标函数(cost function)或得分函数。常见的评估指标有, 准确率召回率,平方误差和,似然函数,后验概率等。
- optimization (优化): 也就是优化算法。常见的优化算法有梯度下降法,高斯牛顿法,线性优化,二次优化等。
- 课本中一般都是以模型来分章节讲解,但是评估与优化同等重要。
泛化能力才是重要的(It’s Generalization that counts)
- 数据要分为训练数据和测试数据,只提高训练数据的预测精度是不够,这样可能会造成过拟合。100%的在训练数据上的精度,可能在测试数据上只有50%. 在训练数据上75%的精度可能测试数据上也是75%的精度,由于前面的分类器。所以说泛化能力才是最重要的。
只有数据是不够的
- 只有数据是无法进行机器学习的,必须有先验的知识在算法里面。(no free lunch理论)
- 先验知识比如,用什么建模,评估,如何优化
- 过拟合有很多方面 (overfitting has many faces)
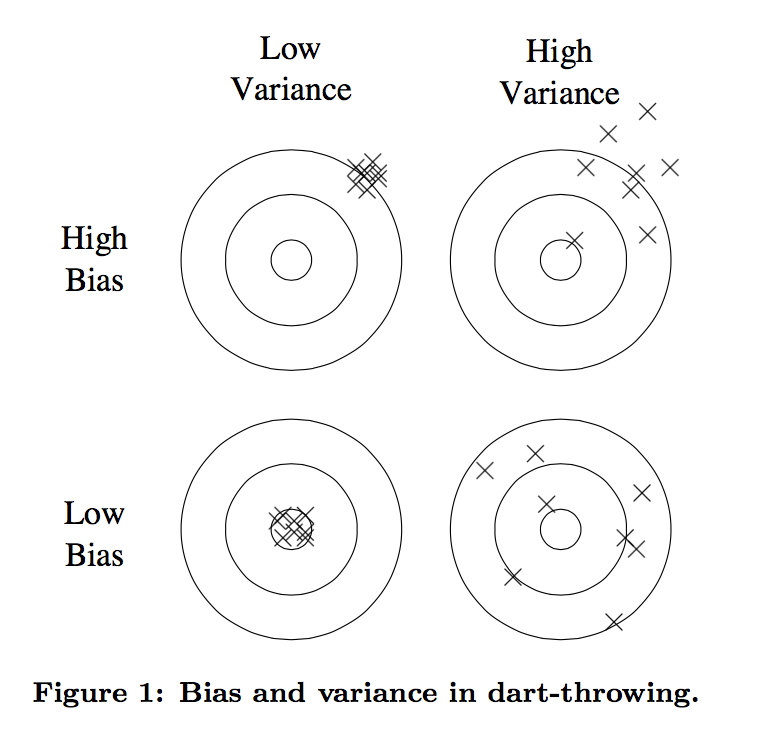
- 误差可以分解为 bias和variance两个方面,如下图
- bias可以理解是预测或估计很多次的均值
- variance表示很多次估计的方差,如右下角的图,虽然均值和真实接近,但是每一次估计的方差过大。
- 线性模型一般variance小,bias大
- 树模型一般variance大,bias小
- 下面几个思路可能减小过拟合:
- 交叉验证 (cross validation), 即每次抽出一部分数据作为test data, 剩下的作为training data
- 可以加入正则项,避免模型过于复杂
- 一个常见的误解是,有噪声的情况才会出现过拟合。(没有噪声也会出现过拟合)
- 误差可以分解为 bias和variance两个方面,如下图
- 直觉在高维度行不通
- 维数灾难
- 在高维度的相似度和低纬度的相似度不同
- 直觉上,加入一些信息量少的feature可能不会影响预测效果,因为它最多少提供一些信息。然后现实中,这些feature提供的信息的益处不如它增加的维度对结果所带来的坏处。
- 可以通过一定方法降维输入的feature,如PCA等
- 理论保证不一定可靠
- 现实实现中,理论保证不一定可靠
- 理论推动了机器学习的发展,但是在实际中只是参考因素之一
- 特征工程(选择)是关键 (feature engineering is the key)
- 为什么有些机器学习项目成功了,有些没有呢?最核心的原因就是feature的选择使用。
- 实际项目中,很多时间都在用于,收集、清理、预处理数据,特征选择。然后才是放在算法中跑
- 跑算法可能是其中最快的一环。(因为很成熟了)
- 在特征选择时,需要加入人的知识在里面,那些效果好的算法往往是特征选择的好。(以呼应了前面的理论,只有data是不够的,需要人的智慧)
- (插一句,难怪现在数据挖掘工程师都被称为feature engineer)
- 更多的数据可以打败更聪明的算法
- 假设你已经拿到了最优的feature,如何继续优化
- 1 设计更好的算法
- 2 使用更多的数据
- 很多研究者专注于设计更好的算法,而最快速简单的方法就是收集使用更多的数据
- 80年代收集数据是问题,现在主要的问题是处理数据的速度。
- 假设你已经拿到了最优的feature,如何继续优化
- 学习更多的模型,而不是一个
- 现在 model ensembles的技术非常标准了,最简单的就是bagging.
- 简单来说就是多训练不同的模型,用model ensembles的技术将这些模型综合起来用,可以得到比任何模型单一都好的效果。(在netflixprize比赛中也得到了体现,不同队伍的分类器组合到一起可以得到一个更优的分类器)
- 简单并不代表准确
* 如果假设模型比较的简单,并且获取了比较好的结果,说明是假设的比较精确。并不能说明越简单就越精确
* 简单本身就是一种优点,但是它和精确没有必然联系 - 可以被建模不一定代表可以被学习
- 相关关系并不意味着因果关系
.