
论文链接:https://arxiv.org/pdf/2203.09795.pdf
代码链接:无
1. 动机
虽然视觉Transformer已经取得了相当大的进展,但对其设计和训练程序的优化只进行了有限的探索
2. 贡献
这篇论文提供了三种关于训练视觉Transformer的见解:
- 并行的视觉Transformer。提出了一个非常简单的方法来实现vit。从如下所示的顺序体系结构开始,作者通过成对地重组相同的块来并行化体系结构,这可以用于任何不同数量的并行块。这将产生具有相同数量参数和计算的体系结构,同时更宽更浅。这种设计允许更多的并行处理,简化优化,并根据实现减少延迟。实验分析了这种并行结构的性能,特别是与顺序基线相比,它如何影响精度。如果深度足够,并行版本将成为一个引人注目的选择。在某些情况下,作者还观察到由于更容易的优化而导致的准确性的提高。
- Fine-tuning attention is all you need。通常的做法是,在针对目标任务进行微调之前,先对网络进行训练。这是支撑迁移学习的标准方法,当目标任务的图像数量有限时,可以利用像ImageNet这样的大型通用数据集。另一个上下文是改变分辨率的上下文。通常情况下,一个人会以比在推理时间使用的分辨率更低的分辨率训练。这样不仅节省了资源,而且还减小了数据增强所产生的训练和测试图像的尺度差异。
- 利用masked自监督学习预处理patch。本文提出了一种简单的方法,通过应用patch预处理后的掩蔽,将基于mask的自监督训练方法与patch预处理相适应。然而,作者进行的实验分析表明,现有的卷积stem在与BeiT结合时并不有效。为了解决这个问题,本文引入了一个分层的MLP (hMLP) stem,它交叉了MLP层和patch聚合操作,并且禁止patch之间的任何通信。我们的实验表明,这种选择是有效的,能够利用BeiT自监督的预训练和patch预处理的好处。此外,hMLP-stem对于监督情况下的ViT也是有效的
3. 方法
3.1 baseline
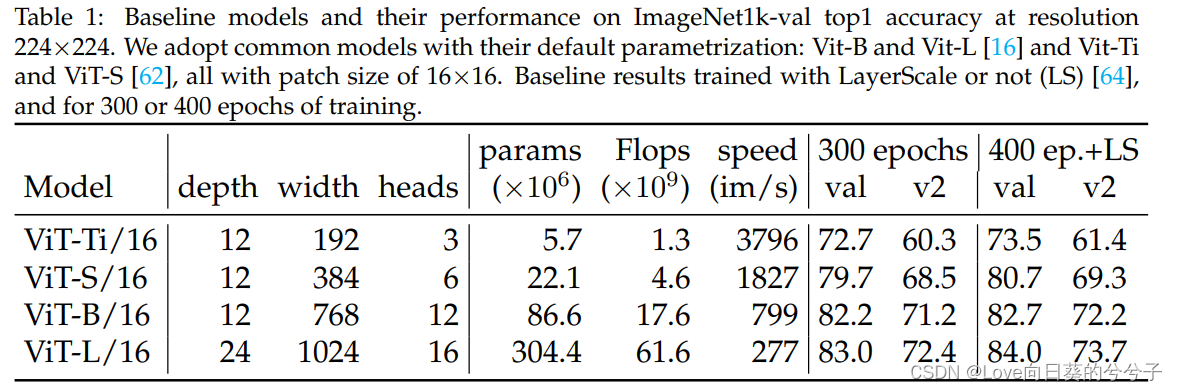
如上表1中展示了baseline的结果。作者通过少量调整,训练过程在所考虑的模型大小方面优于现有的监督训练程序,如下表所示。注意,本文所有的模型都使用 16 × 16 16 \times 16 16×16的patch大小。除非特别说明,本文实验是用尺寸为 224 × 224 224 \times 224 224×224的图像进行的。
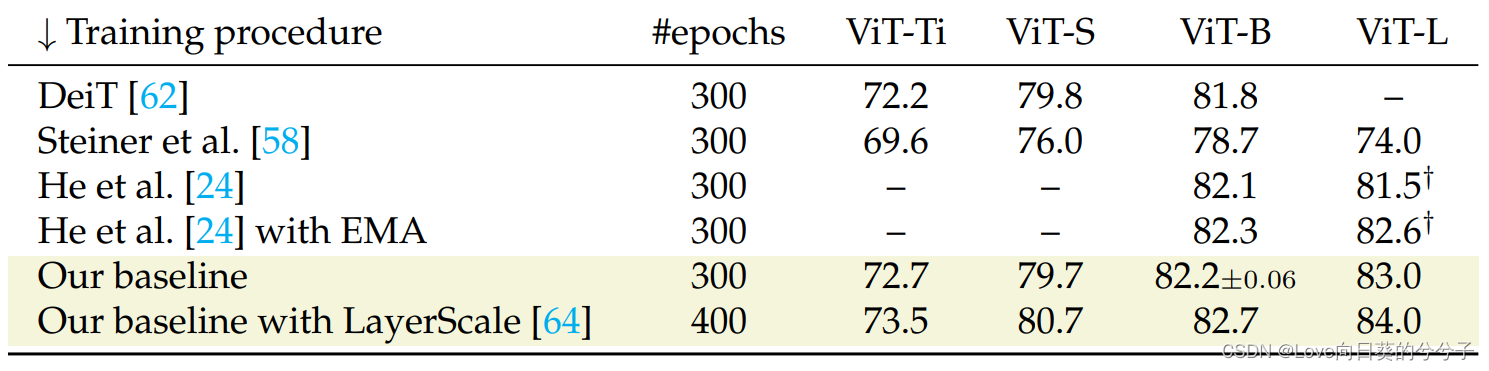
3.2 Depth vs Width: Parallel ViT
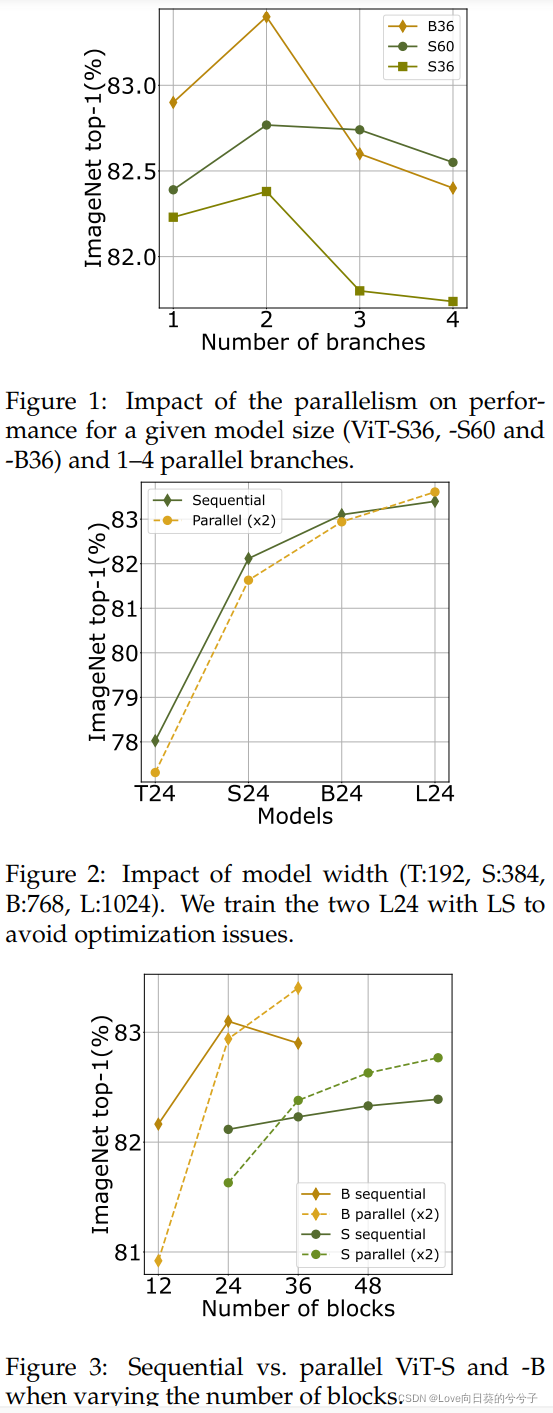
在神经架构设计中,一个反复出现的争论是如何平衡宽度和深度。Imagenet上第一个成功的神经网络并不是很深,例如,2014年的公为22层的GoogleNet是很深的,而ResNets改变了这种情况。ResNets由于剩余连接,导致网络越深对优化的阻碍就越小。在它被引入后,一些研究人员研究了交换深度相对于宽度的替代选择,如Wide Residual Networks。最近,人们对更wide的架构重新产生了兴趣。例如,Non-deep Networks提出了一个具有多个并行分支的体系结构,其设计更加复杂。在本文的工作中,其目标是提出一个更简单和灵活的替代方案,以更直接的方式建立在常规的ViT之上。
1)关于ViT的宽度与深度的不同优缺点
ViT体系结构由三个量参数化:宽度(即工作维度d)、深度和头的数量。本文并不讨论后者。增加深度或宽度会增加模型的容量,通常也会增加模型的精度。对于在表1中报告的最常见的ViT模型,宽度和高度是一起缩放的。
- 参数化 & 优化。网络越深,层的组成性越好。这是ResNet的一个决定性优势,因为优化问题被剩余连接解决。然而,过多的深度会阻碍优化,即使有残差连接。已经提出了一些解决vit这一问题的解决方案,表明使用改进的优化程序进行训练时,Transformer能从深度中受益。
- 可分性。在图像分类中,最终将空间特征投影或池化成高维潜在向量,然后将其反馈给线性分类器。这个向量的维数应该足够高以便类是线性可分的。因此,对于涉及许多类的任务,它通常更大。例如,在ResNet-50中,当应用于CIFAR时,它的尺寸为512,而ImageNet的尺寸为2048。在ViT中,宽度与每个patch的工作维度相同,通常比ResNet更小,这可能会限制分离能力。另外,隐向量的维数越大,越容易出现过拟合。在这方面,容量和过拟合之间的妥协是微妙的,并取决于训练集的大小
- 复杂性。在ViT中,不同的复杂性度量受到宽度和深度的不同影响。忽略patch预处理和最后的分类层,它们对复杂性的影响可以忽略不计,则有:1)参数的数量与深度和宽度的二次函数成正比;2)由FLOPS确定的计算与深度成比例,在宽度上是二次的;3)当增加固定宽度的深度时,推理时间的峰值内存使用是恒定的,但它是宽度的二次函数;4)宽架构的延迟在理论上更好,因为它们更并行,但实际的加速取决于实现和硬件。
2)Parallelizing ViT
本文通过分组层提出并分析了flattening视觉Transformer。考虑由函数 m h s a l ( ⋅ ) mhsa_l(\cdot) mhsal(⋅)、 f f n l ( ⋅ ) ffn_l(\cdot) ffnl(⋅)、 m h s a l + 1 ( ⋅ ) mhsa_{l+1}(\cdot) mhsal+1(⋅)和 f f n l + 1 ( ⋅ ) ffn_{l+1}(\cdot) ffnl+1(⋅)定义的Transformer块序列,而不是像通常的实现那样用四个步骤顺序处理输入 x l x_l xl:
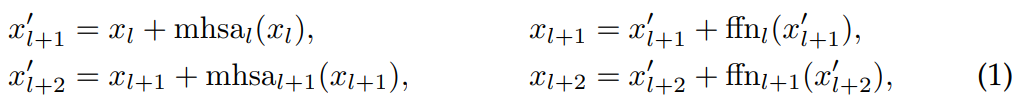
作者用两个平行的运算来代替这个组合:
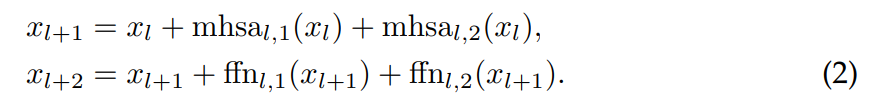
对于给定数量的MHSA和FFN块,这将层数减少了两层。相反,并行处理的数量是并行处理的两倍。这种并行化背后的直觉是:随着网络的深入,任何残留块 r ( ⋅ ) r(\cdot) r(⋅)的贡献,无论是 m h s a ( ⋅ ) mhsa(·) mhsa(⋅)还是 f f n ( ⋅ ) ffn(·) ffn(⋅),相对于整体函数来说,都变得越来越小。因此,近似 ∀ r , r ′ r ′ ( x + r ( x ) ) ≈ r ′ ( x ) \forall{r, r'}\ r'(x + r(x)) \approx r'(x) ∀r,r′ r′(x+r(x))≈r′(x)变得越来越令人满意,并且很容易检验,如果这个近似是正确的,公式(1)和(2)是相等的。
本文的策略不同于使用工作维数更大的Transformer,这将导致准确度、参数、内存和FLOPS之间的不同权衡,正如下表3展示的那样。与上面讨论的增加工作维数会增加复杂性的二次方相比,本文的修改对于参数和计算是中立的。根据作者是否有效地处理并行化,推断时间和延迟时间的峰值内存使用将被修改。注意,我们可以选择并行处理任意数量的块,而不是两个;如果在每一层处理单个块,回到顺序设计
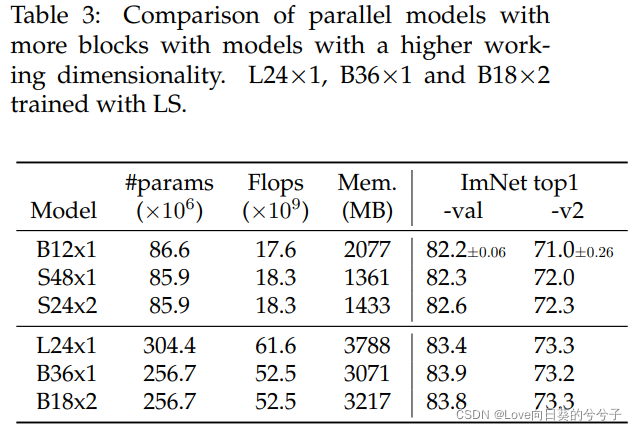
3.3 Fine-tuning attention is all you need
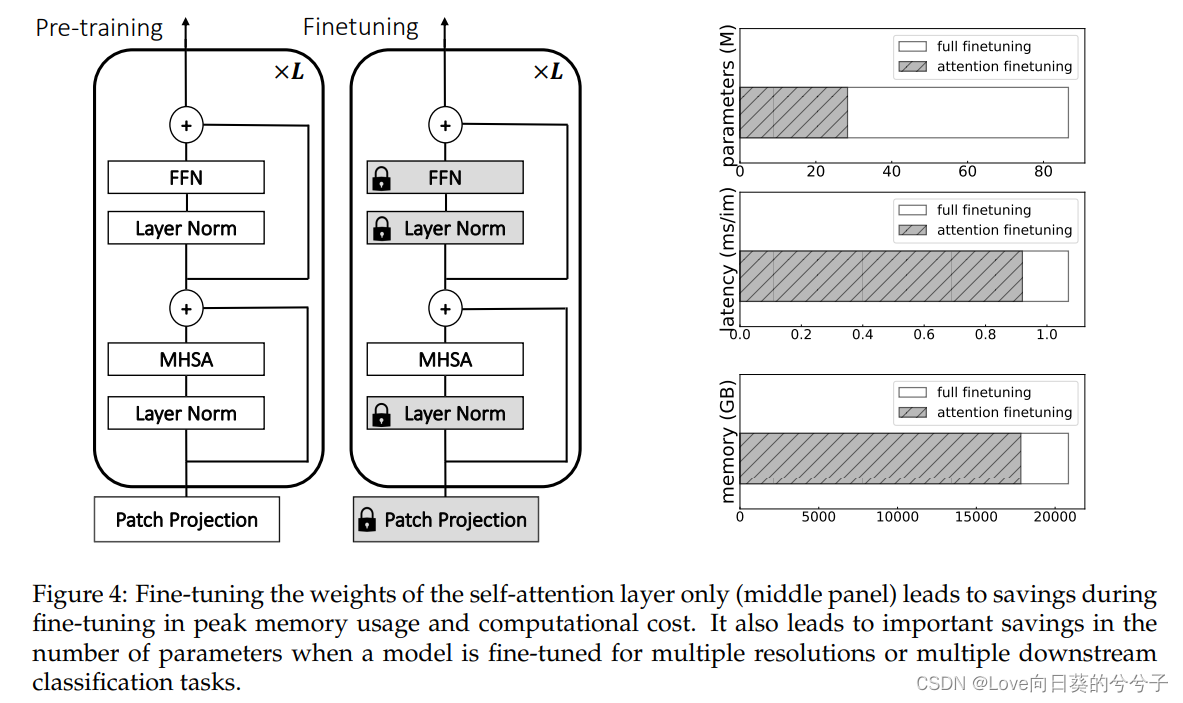
作者在这里重点关注ViT模型的微调,以便使模型适应更大的图像分辨率,或者处理不同的下游分类任务。具体地,作者考虑了一种只对MHSA层对应的权值进行微调的方法,如图4。一般来说,微调也是与基础模型和迁移学习本身概念相关的范式。最近的一项工作探索了使用各种类型的适配器模块和少量任务特定参数的预训练模型的适应性。相反,在我们的工作中,本文专注于微调原始ViTs。
3.4 Patch preprocessing for Bert-like self-supervised learning
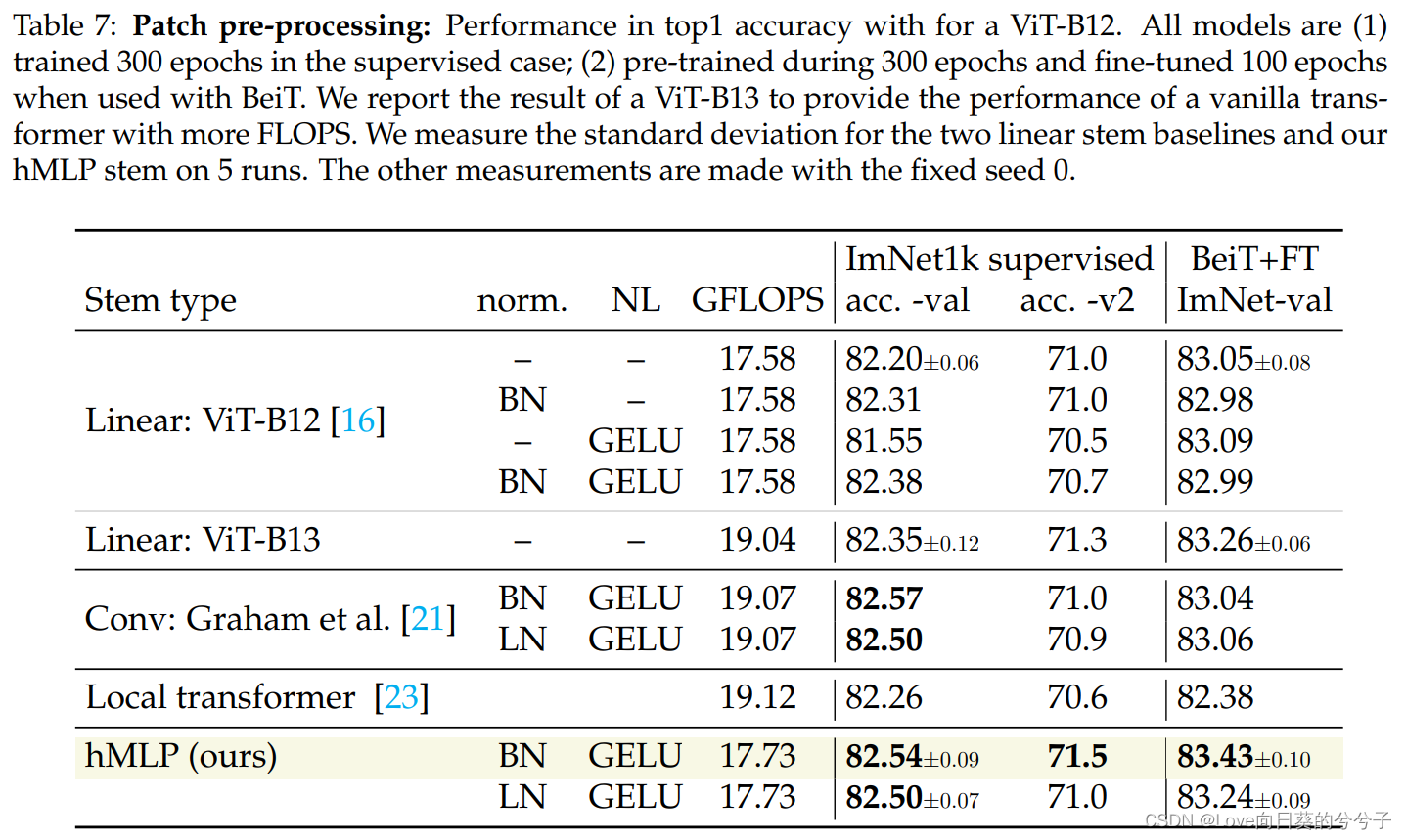
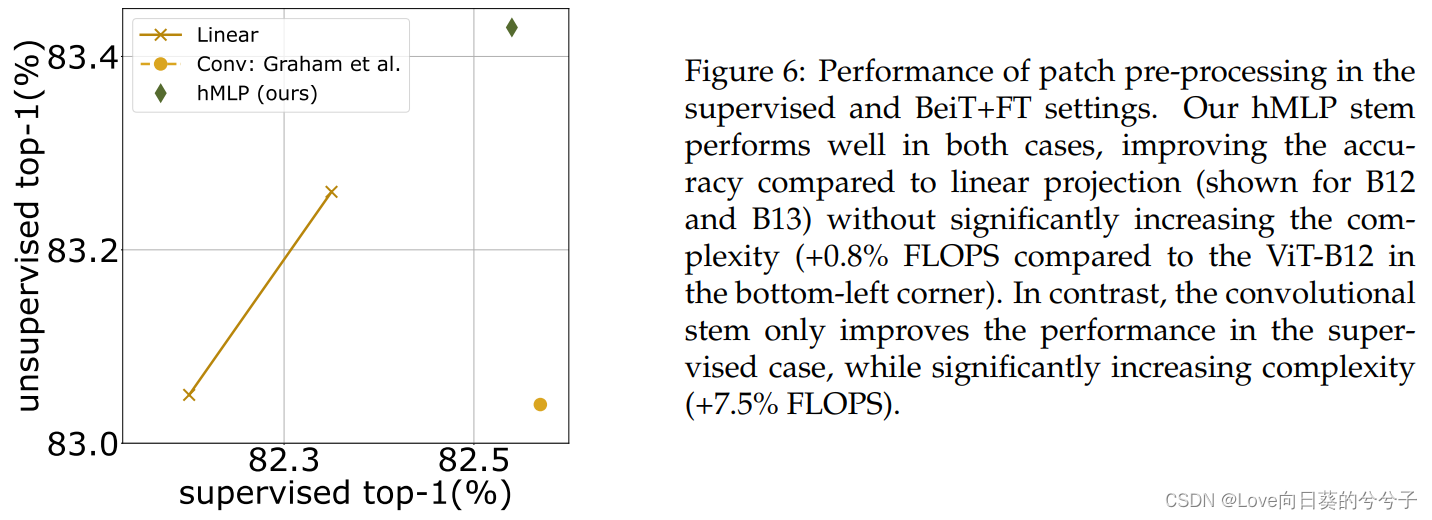
原始的ViT论文考虑在网络设计中加入卷积而不是patch projection。最近的几篇论文主张在体系结构中包含一个小型的预处理网络,而不是简单的patch projection。大多数被认为是基于卷积的预处理子网络,通常被称为卷积stem。小型变压器也已经被考虑。虽然开发这些patch预处理设计是为了提高精度和/或稳定性,但它们的设计和灵活性仍存在一些问题。1)首先,当与普通Transformer结合使用时,哪种效果最好还不清楚。2)其次,目前还没有解决它们与基于patch masking的自我监督方法的兼容性问题,特别是在像BeiT这样的Bert-like自动编码器上。本节将尝试回答这些问题,作者在精度方面比较了几种现有的预处理设计,并结合BeiT,使用BeiT作者发布的代码库来计算和评估它们。这里所做的唯一改变是在ImageNet-1k上训练标记器,而不是使用来自于BeiT中使用的DALL-E的标记器,该标记器是在由2.5亿张图像组成的专有数据集上训练的。这样,预训练只基于ImageNet-1k。这允许重复的实验和公平的比较,并给出了等价的结果。由于现有的卷积设计在结合掩码的情况下并不令人满意,首先介绍了作者自己的设计。
3.4.1 hierarchical MLP (hMLP) stem
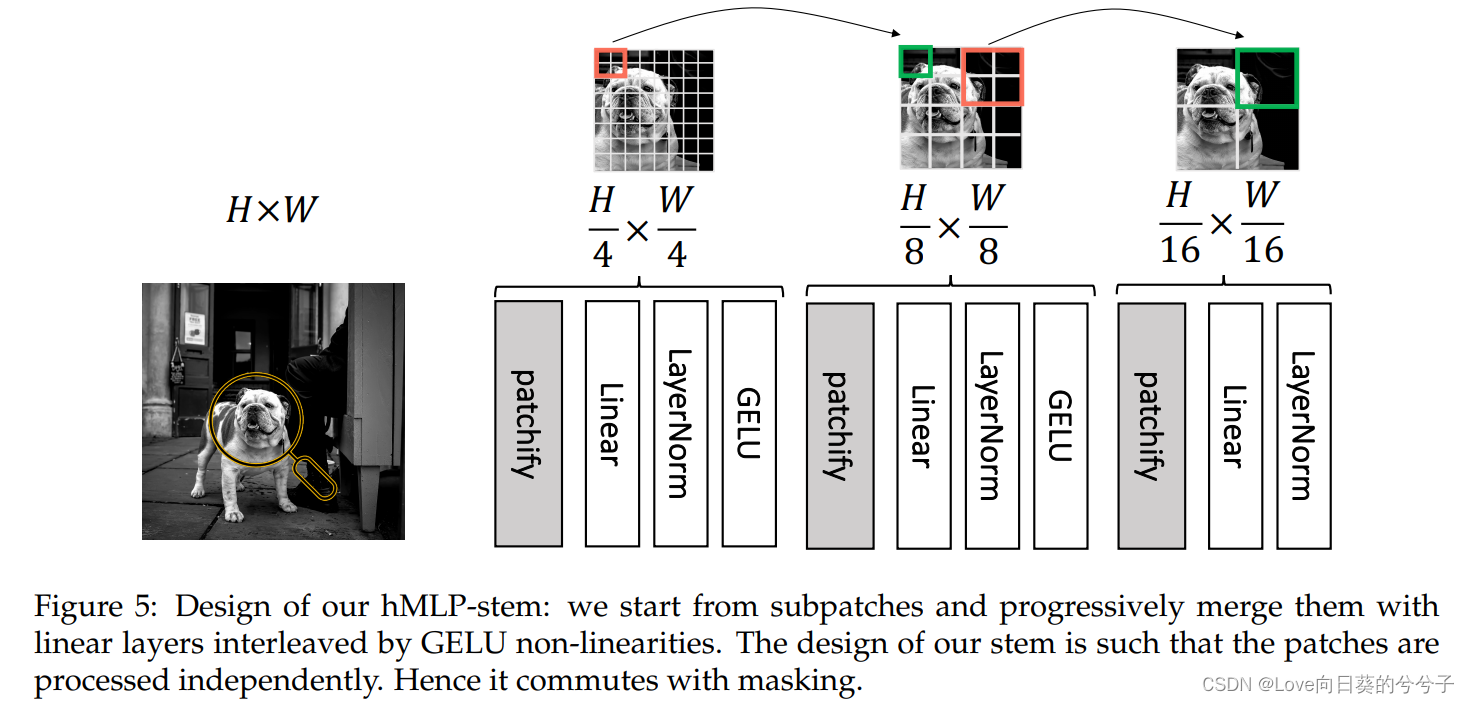
如上图所示,所有的patch独立处理,线性层交错非线性和重正态化。它的设计是由作者的动机所引导的,即在预处理阶段删除不同16×16补丁之间的任何交互。即使我们屏蔽一个patch,它也不会像现有设计那样,因为与其他补丁的卷积重叠而产生任何工件。因此,使用hMLP解决方案,我们可以等效地在patch处理阶段之前或之后屏蔽patch。请注意,尽管patch是独立处理的,我们的hMLP-stem相当于一个卷积stem,其中卷积核的大小和它的stride是匹配的,在实践中,用卷积层实现了它,如下代码:

简而言之,我们从小的 2 × 2 2 \times 2 2×2个patch开始,然后逐渐增加它们的大小,直到它们达到 16 × 16 16 \times 16 16×16。上图5中的patchify表示补丁大小的每一个增加,这体现了像swin-transformer这样的分层Transformer设计的精神。在应用GELU非线性之前,作者先用线性映射和归一化来映射这些patch。对于归一化,我们考虑并评估两种选择:要么使用批处理归一化(BN),要么使用层归一化(LN)。虽然BN提供了更好的折衷,但LN在小批量使用时更有意义:它甚至可以在每批图像中工作得很好,就像经常用于物体检测一样。
4. 部分实验结果
4.1 sequential and parallel ViTs对比
4.2 优化的影响
作者使用LayerScale提供结果,这有助于优化最大的模型。它提高了顺序模型和并行模型的性能,二者最终大致相当。因此,对于足够大且经过适当优化的模型,顺序vit和并行vit大致相当
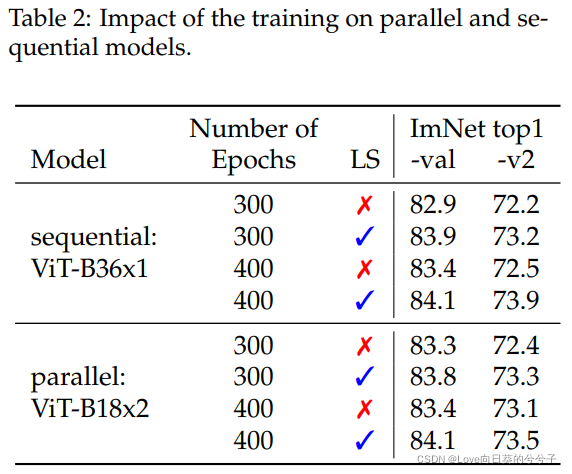
4.3 增加模块数量还是增加工作维度?
作者在参数和FLOPS方面大致调整了复杂性,但这意味着具有更大工作维数的ViT模型在典型实现中具有更高的峰值内存使用。在两种测试环境中,顺序模型和并行模型都比具有较大工作维数的模型具有更高的精度。顺序和并行模型可与36块进行比较。在48块的情况下,由于顺序模型的深度增加,并行模型的效果更好。
4.4 潜在因素
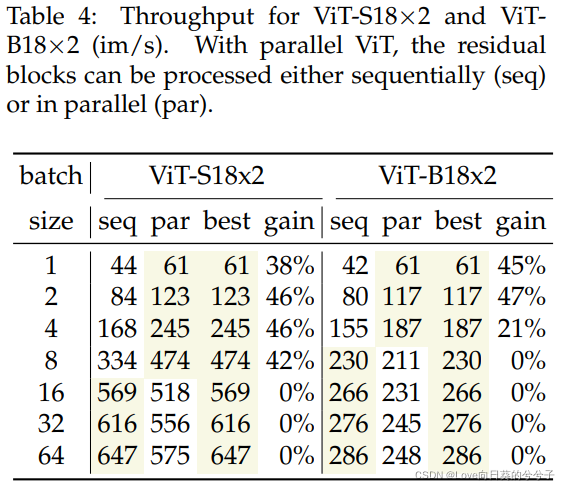
在一个V100的通用gpu上,观察到在每个样品处理的情况下有显著的速度提高,在相对较小的模型下,小批量处理也有一些增益。这个比较基于本文并行架构的一个简单实现,由于缺乏特定的CUDA内核,这个实现不是最优的。总的来说,测量结果表明,需要特定的硬件或内核才能在吞吐量方面获得显著的优势。
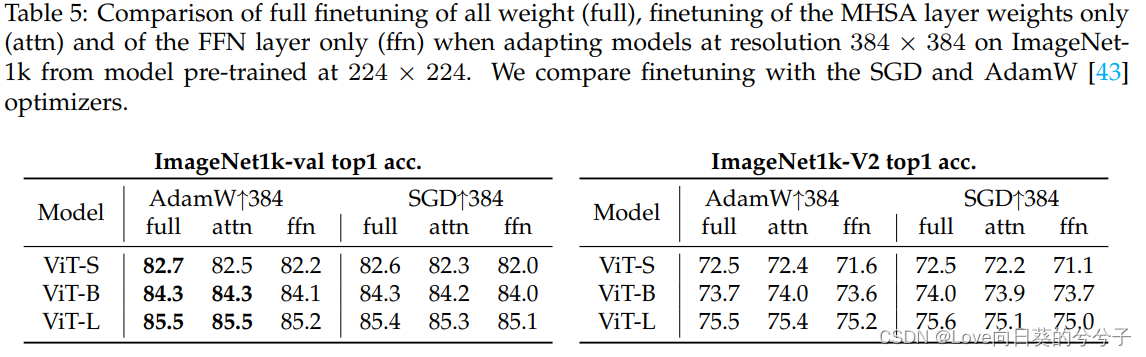
4.5 不同分辨率上微调
在表5中报告了对预训练为 224 × 224 224 \times 224 224×224的模型在分辨率为 384 × 384 384 \times 384 384×384的情况下进行微调的ViT-S、ViT-B和ViT-L的结果。仅微调MHSA权重提供的结果与全面微调ImageNet-val和ImageNet-V2的结果相差在标准偏差(0.1)以内。当微调FFN层时,情况并非如此,而这些层包含MHSA参数数量的两倍。注意,我们预先训练的模型经过了足够长的训练(400个epoch),以确保收敛
4.6 对不同的数据集进行微调
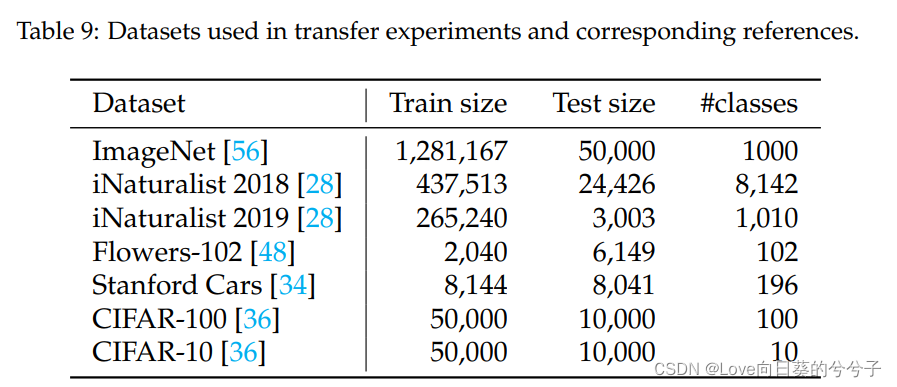
通过微调将在ImageNet上预训练的ViT转移到不同的下游分类任务时,评估本文的方法。作者考虑的是如下表9给出特征和引用的公共基准。
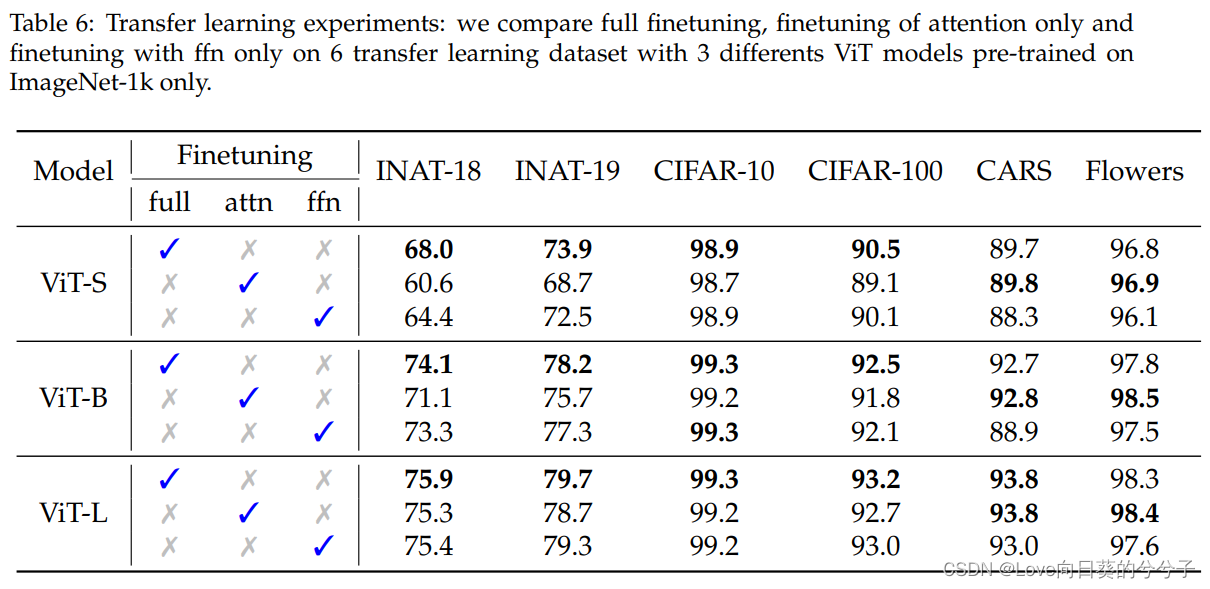
4.7 监督学习中的stem比较
5. 结论
- 对于小的数据集,即CARS和Flower,仅对MHSA层进行微调是一个很好的策略,它甚至比全调优更好。作者的解释是,限制权重的数量具有规则化的效果。
- 在使用ViT-S小模型与大数据集(特别是iNaturalist)混合这种情况下,有更多的图像和新的类需要学习,这些是在微调阶段之前没有看到的。将微调限制在MHSA层只允许修改相对较少的参数。FFN层有两倍多的权值,在这种情况下会产生更好的结果。随着ViT-L模型的增大,这种限制趋于消失,MHSA的容量要大得多,因此足够了。
- 与现有文献相比,hMLP设计并没有显著增加计算需求。例如,在本文的设计中,ViT-B需要17.73 GFLOPS的FLOPS。与使用通常的线性映射相比,这只增加了不到1%的计算量
这篇论文目前刚刚挂在arXiv,没有真正发表,实验结果真实性还不能完全保证,请大家谨慎参考!!!