比如你写了一个程序,用来检查英语的拼写,你添加了几百条规则,终于看上去像点样子了,可如果你是Microsoft Word的开发者呢,中文怎么办,西班牙语怎么办…
这个时候用机器学习吧!


在监督式机器学习中, 我们将学习如何创建模型来结合输入信息, 对以前从未见过的数据做出有用的预测。
(特征与标签)就比如说,我们要搞这个垃圾邮件分类吧
特征,它是从email里提取出来的一些特征值,可以是这封信的任何信息。
y是一个标签,y=0是非垃圾邮件,y等于1是垃圾邮件
那么这就解释清楚了标签和特征。
样本是一个特定的数据实例,这里可以看成一个向量,包含特征值和标签,比如某封特定的email,有标签的可能是用户给的,比如用户觉得某封电子邮件是垃圾邮件,他给他贴了个标签,那没有标签的就是我们要干活的对象了
模型可将样本映射到预测的标签y’,可以把他看成一个函数,那他的参数是什么呢?是通过学习得到的。
我们来重点介绍一下模型生命周期的两个阶段:
训练表示创建或学习模型。也就是说,您向模型展示有标签样本,让模型逐渐学习特征与标签之间的关系。
推断表示将训练后的模型应用于无标签样本。也就是说,您使用训练后的模型来做出有用的预测 (y’)。例如,在推断期间,您可以针对新的无标签样本预测 medianHouseValue。
回归与分类
回归模型可预测连续值。例如,回归模型做出的预测可回答如下问题:
加利福尼亚州一栋房产的价值是多少?
用户点击此广告的概率是多少?
分类模型可预测离散值。例如,分类模型做出的预测可回答如下问题:
某个指定电子邮件是垃圾邮件还是非垃圾邮件?
这是一张狗、猫还是仓鼠图片
线性回归
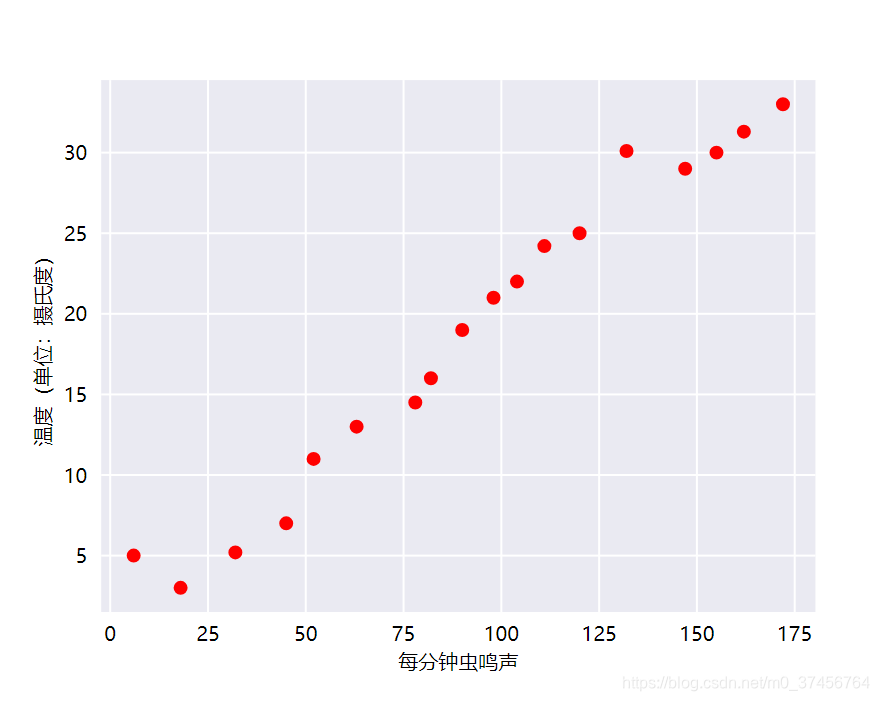
用这个去预测它
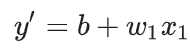
不失为一种近似
L2误差称之为方差
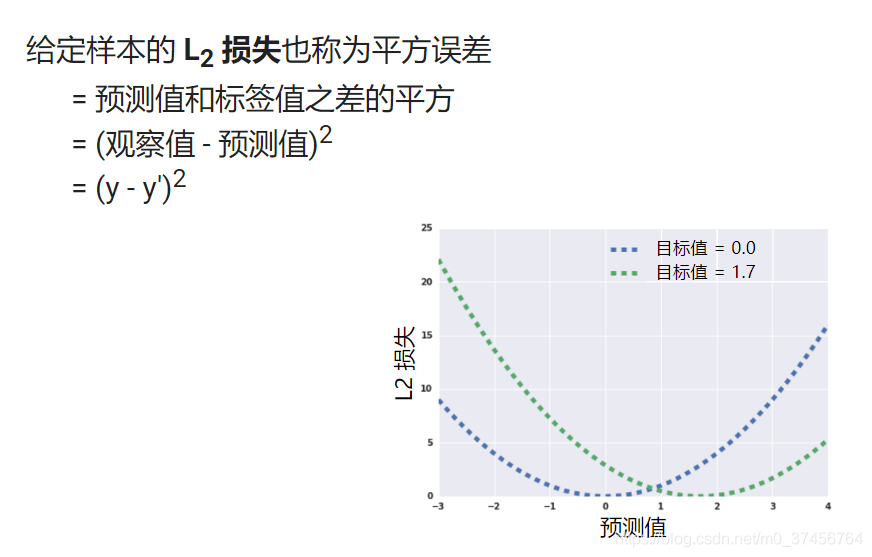
上面的函数用来代表线性回归模型中整个数据集的误差
在监督式学习中,机器学习算法通过以下方式构建模型:检查多个样本并尝试找出可最大限度地减少损失的模型;这一过程称为经验风险最小化。
MSE即样本集方差的计算公式
这里复习下梯度,那什么是梯度呢,梯度是一个向量函数,给定一个点P,它能返回u=f§的这个场,在P点处,u上升的最快的方向,比如平面内有一个气味的分布,给一个点,返回该点处,气味最浓的方向;空间中有一个温度的分布,给定一个点P,返回P点处温度上升的最快的那个方向。它是怎么实现的呢,用的是方向导数,|G|,方向导数不是给一个点,返回所有方向的变化率吗,我把那个最大的变化率给你构造出来,那这个最大的变化率产生于哪个方向呢,梯度方向啊。这样,单独把这个方向拿出来讲,就是梯度了。