机器学习review
Paper:Machine Learning: A Review of Learning Types
这是一篇关于机器学习的综述,里面简述了各种现有的机器学习技术。
1 主要的方法:监督、无监督、强化
1.1 监督学习
数据格式:特征 + 标签
学习目标:到从输入到输出的映射函数
根据输出变量划分,监督学习又可以分为分类和回归
分类:输出结果是离散的、可列的,如水果种类、手写字体识别。
回归:输出结果是连续的,如价格、温度-气压曲线
1.2 无监督学习
数据格式:特征
目标:尝试根据输入的数据建立模型,发现数据的潜在特性
无监督的代表是聚类——一种挖掘数据内部结构的技术。
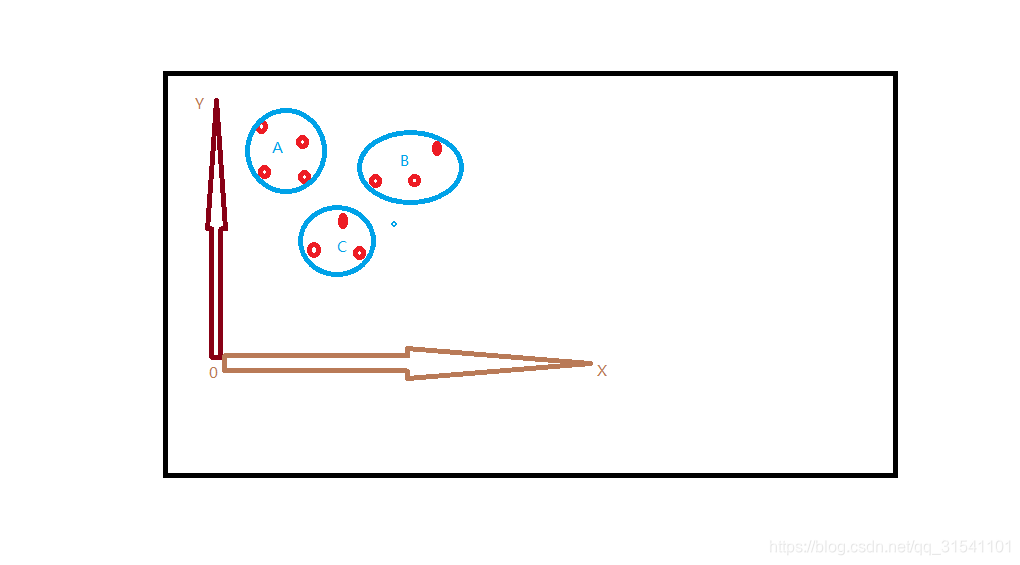
举个栗子:我有10个样本,要把它们分成A、B、C共3类(集群);
如下图,每个类内部的样本其相似性较大,类之间相似性较小。
相似性度量可用空间距离、欧氏距离,度量方法不同会产生不同的聚类结果。
K-means算法例子:乘客分群,区分高价值客户、无价值客户等
1.3 强化学习
强化学习是这样一个过程:
一个agent在一系列任务中
1)观察环境状态
2)做出反应(或行为或决策)
3)获得惩罚或者奖励
4) 调整自己的行为
不断重复上述过程,最终目标是最大化它的最终奖励。
调整方式:如果Agent的某个行为策略导致环境正的奖赏(强化信号),那么Agent以后产生这个行为策略的趋势便会加强。
强化学习例子——王者荣耀中的机器人。

Overview of reinforcement learning. An agent observes
the environment state and performs actions to maximize an overall
reward.
2 混合方法
2.1 半监督学习(semi-surpervised learning)
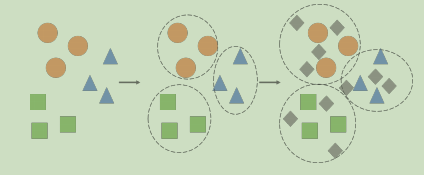
顾名思义,半监督是监督学习和无监督学习的中间状态,算法使用带标记和不带标记数据的组合来训练模型。
常见的方法是,少量标签数据和大量未标记数据的组合,先使用无监督学习算法进行聚类,根据聚类结果,可对未标记数据进行标记,然后就可以使用监督学习算法训练数据。
许多半监督学习算法的成功很大程度上取决于以下假设的有效性:未标记和标记的数据具有相同的分布
 Overview of semi-supervised learning
Overview of semi-supervised learning
2.2 自监督学习(self-surpervised learning)
自监督是无监督的一种形式。初始时,数据没有任何标记,通过不断地挖掘,从而发现数据的内在联系,形成监督信息
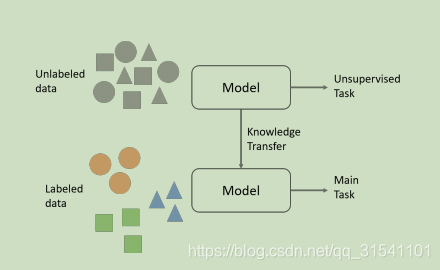
This is done in an unsupervised manner by forcing the network to learn
semantic representation about the data. Knowledge is then transferred to the model for the main task.
2.3自我学习(self-taught learning)
自学习与半监督学习类似,也使用未标记的数据,试图在已标记数据有限的情况下,提高监督学习的性能。但,自学习允许标记数据与未标记数据拥有不同的分布,甚至不用遵循同分类,所以在实际应用中,自学习使用更加广泛。

自上而下:监督分类使用大象和犀牛的标记示例;半监督学习使用大象和犀牛的附加未标记示例;转移学习使用其他类型标记的数据集;自学只需要额外的未标记图像,例如从互联网上随机下载的图像。
自学习的问题是,如何通过无监督学习从未标记数据中学习知识,这些知识是什么,然后如何将这些知识迁移到监督学习的任务中。
更多参考:Self-taught learning: transfer learning from unlabeled data
.
3 其他常用方法
3.1 多任务学习(Multi-task Learning)
MTL的灵感来源于人类的学习活动,人们通常将以前任务中学到的知识,应用于在新的任务中学习其他的知识。这里“以前的任务”应是相互关联的。比如小学生写文章,老师先会教他们认字、写字、学词、造句、标点…

3.2 主动学习(active learning)
“学习模块”和“选择策略”是主动学习算法的2个基本且重要的模块。
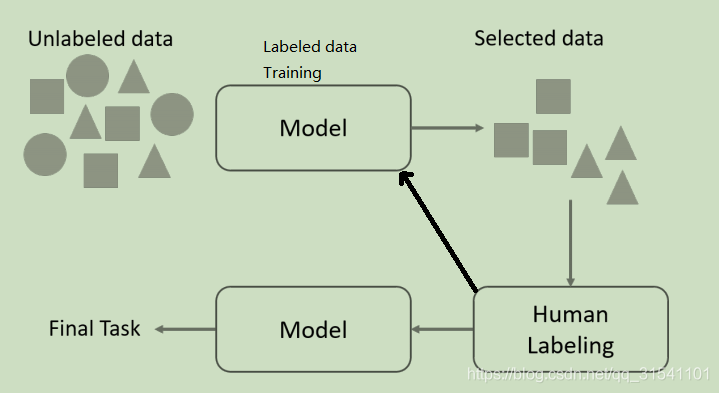
主动学习过程:“学习模块” 先对少量标记数据进行训练,根据此次训练结果,从未标记数据中选择想要标记的数据,人类专家标记,再把新标记的数据加入训练数据中。不断重复直到学习到模型达到某种标准。
3.3 在线学习(online learning)
准确地说,Online Learning并不是一种模型,而是一种模型的训练方法,Online Learning能够根据线上反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高线上预测的准确率。Online Learning的流程包括:将模型的预测结果展现给用户,然后收集用户的反馈数据,再用来训练模型,形成闭环的系统。
3.3.1 增量学习(incremental learning)
增量学习思想可以描述为:每当新增数据时,并不需要重建所有的知识库,而是在原有知识库的基础上,仅对由于新增数据所引起的变化进行更新。我们发现,增量学习方法更加符合人的思维原理。