前几节我们详细的探讨了,梯度下降存在的问题和优化方法,本节将介绍在数据处理方面很重要的优化手段即批量归一化(批量归一化)。
批量归一化(Batch Normalization)并不能算作是一种最优化算法,但其却是近年来优化深度神经网络最有用的技巧之一,并且这种方法非常的简洁方便,可以和其他算法兼容使用,大大加快了深度模型的训练时间。
BN算法详解
那什么叫批量归一化呢?首先,归一化就是将数据的输入值减去其均值然后除以数据的标准差,几乎所有数据预处理都会使用这一步骤。而深度学习也可以认为是逐层特征提取的过程,那每一层的输出其实都可以理解为经过特征提取后的数据。因此,批量归一化方法的“归一化”所做的其实就是在网络的每一层都进行数据归一化处理,但每一层对所有数据都进行归一化处理的计算开销太大,因此就和使用最小批量梯度下降一样,批量归一化中的“批量”其实是采样一小批数据,然后对该批数据在网络各层的输出进行归一化处理 。
假如我们一次采样几条数据训练,用表示训练第ķ条数据时,第
层的第
神经元模型的输出值;
表示这批数据在第
层的
神经元处的平均输出值;
表示这批数据在第
的层第
神经元型态处输出值的标准差。批量归一化后的输出值就如下式所示。
其中神经元型态的输出为均值为:
神经元输出值的标准差为:
其中的英文一个很小的常数。
其中的英文一个很小的常数,目的是防止上式的分母为0批量归一化的目的其实很简单,就是把神经网络每一层的输入数据都调整到均值为零,方差为1的标准正态分布。那为什么这样做呢?这还要从深度神经网络最大的梦魇一一梯度消失讲起。假设我们使用sigmod函数作为神经元的激活函数,当输出值较大时,sigmod函数就会进入饱和区域,导致其导数几乎为零,即使我们知道需要矫正该神经元,也会因为梯度太小而无法训练。如图下图所示,sigmod激活函数在[·2,2]之间的取值是一段近似线性的区域。想必你也猜到了吧,其实BN算法所做的就是把输入值尽可能地归一化在激活函数这一狭窄区域。但这又引入了另一个问题,我们知道多层线性神经网络其实可以用一层线性网络来表示,那我们使用BN算法将输入值投射到激活函数的线性区域,会不会使 得深度网络力下降呢?答案是肯定的,如果仅仅是归一化各层输入值到一个近似的线性区域,我们的深层网络能力将大大降低。

因此,BN算法其实还有另一个步骤,那就是再将归一化的数据放大,平移回非线性区域,如下式所示,我们引入,
两个学习参数,调整归一化的输出值。
变量和
是允许新变量有任意均值和标准差的学习参数,这似乎不合理,为什么我们将均值设为0,然后又引入参数允许它重被设为
呢?这是因为新的参数不但可以表示旧参数的非线性能力,而且新参数还可以消除层与层之间的关联,具有相对独立的学习方式。在旧参数中,H的均值和方差取决于ħ下层中参数的复杂关联。在新参数中,
的均值与方差仅仅由本层决定,新参数很容易通过梯度下降来学习。
运行时平均(运行平均值)
由于训练时我们仅仅对批量采样数据进行归一化处理,该批数据的均值和方差不能代表全体数据的均值和方差。因此,我们需要在每批训练数据归一化后,累积其均值和方差。当训练完成后再求出总体数据的均值和方差,然后再在测试时使用,但累积每一次数据的均值和方差太过麻烦,在实践中,我们经常使用运行时的均值和方差代替全体数据的均值和方差。
如下式所示,和动量学习法类似,我们引入衰减因子对均值和方差进行衰减累积。
BN的传播详解
先给出BN总体处理的框图,然后详细给出他是如何进行计算了

其实上式就是根据前面的式子进行画的,现在这里主要有两个参数进行更新,如何更新呢?一般使用梯度下降法进行更新,那么损失函数是什么呢?
我查了很多资料,很多然人都没解释原因,为什么需要反向传播,或者反向传播的原因在哪里?这里我简单的解释一下,如果有错误,请大家指正首先,我们这里的BN是针对谁做归一化?这个大家需要搞清楚,这不是针对神经网络刚开始的输入,这是针对网络的隐层或者说是中间层进行归一化,刚开始最让我困惑的是上图的反向传播的误差信号到底来自哪里这也是很多博客没说清楚的原因,大家先看一个BN在神经网络的位置的图,如下?

我们知道大多数的神经网络都是基于误差反向传播即BP,因此在反向传播误差时就会经过BN此时怎么传播呢?因此需要考虑BN的反向传播,另外就是BN本身也有两个待定参数需要进行确定,因此这里的损失函数是上一层传递过来的损失,这里大家应该理解损失的来源,下面我们从原始开始推倒公式,在推倒前,大家心里一个有一个很清晰的BP网络反向传播的过程图,下面我贴出来,另外就是大家要时刻记住误差是如何传播的结合上图BN的误差反向传播和下图BP进行理解:

权值调整公式:
我们下面开始详细推倒:
在训练神经网络时,标准化输入可以提高训练的速度。方法是对训练数据集进行归一化的操作,原始即将数据减去其均值后,再除以其方差
。但是标准化输入只是对输入进行了处理,那么对于神经网络,又该如何对各隐藏层的输入进行标准化处理呢?其实在神经网络中,第
层隐藏层的输入侧就是上一层隐藏层
层的输出
。对
进行标准化处理,从原理上来说可以提高
和
的训练速度和准确度。这种对各隐藏层的标准化处理就是批量标准化。值得注意的是,实际应用中,一般是对
进行标准化处理而不是
,其实差别不是很大。
Batch Normalization对第层隐藏层的输入
做如下标准化处理,忽略上标
:
其中,m是单个mini-bach包含样本个数,是为了防止分母为零,可取值
。这样,该使得隐藏层的所有输入
均值为0,方差为1.但是,大部分情况下并不希望的所有
均值都为0,方差都为1,也不太合理通常需要对。通常需要对
进行进一步处理:
上式中,是可学习参数,类似于W和b一样,可以通过梯度下降等算法求得。这里
的作用是让
的均值和方差为任意值,只需调整其值就可以了。
例如,令:
,则,即他们两恒等。
可见,设置和
为不同的值,可以得到任意的均值和方差。
这样,通过Batch Normalization,对隐藏层的各个进行标准化处理,得到
,替代
输入的标准化处理Normalizing inputs和隐藏层的标准化处理Batch Normalization是有区别的:
Normalizing inputs使所有输入的均值为0,方差为1,而Batch Normalization可使各隐藏层输入的均值和方差为任意值。实际上,从激活函数的角度来说,如果各隐藏层的输入均值在靠近0的区域即处于激活函数的线性区域,这样不利于训练好的非线性神经网络,得到的模型效果也不会太好。也。这解释了为什么需要用和
来对
作进一步处理。
Batch Norm经常使用在mini-batch上,这也是其名称的由来。
值得注意的是,因为Batch Norm对隐藏层有去均值的操作,这里所以常数的项
可以消去,数值其效果完全可以由
中的
来实现。因此,我们在使用Batch Norm的时候,可以忽略各隐藏层的常数项
。在使用梯度下降算法时,分别对
,
和
进行迭代更新。
除了传统的梯度下降算法之外,还可以使用我们之前介绍过的动量梯度下降,RMSprop或者亚当等优化算法。
BN算法 在训练中对于一个mini-batch

在训练过程中,我们还需要计算反向传播损失函数l的梯度,并且计算每个参数(注意:和
)。我们使用链式法则,如下所示:下面的公式就是链式求导的,请结合BN大反向传播图进行推倒和查看
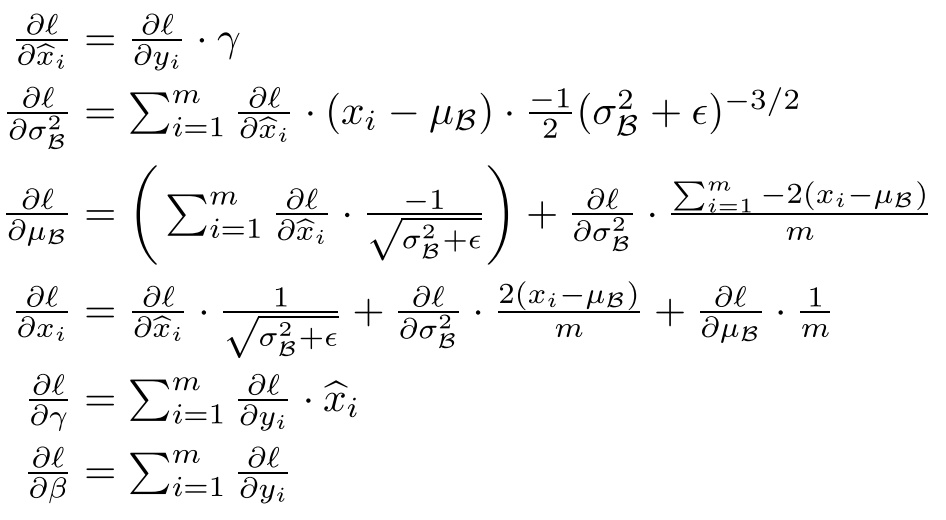
BN算法在训练和测试时的应用
BN算法在训练时的操作就如我们上面所说,首先提取每次迭代时的每个mini-batch 的平均值和方差进行归一化,再通过两个可学习的变量恢复要学习的特征。但是在实际应用时就没有mini-batch 了,那么BN算法怎样进行归一化呢?实际上在测试的过程中,BN算法的参数就已经固定好了,首先进行归一化时的平均值和方差分别为:
方法1:即平均值为所有mini-batch 的平均值的平均值,而方差为每个批次的方差的无偏估计
方法2:估计的方法有很多,理论上我们可以将所有训练集放入最终的神经网络模型中,然后将每个隐藏层计算得到的直接作为测试过程的
和
来使用。但是,实际应用中一般不使用这种方法,而是使用我们之前介绍过的指数加权平均(exponentially weighted average)的方法来预测测试过程单个样本的
和
。
指数加权平均的做法很简单,对于第层隐藏层,考虑所有mini-batch在该隐藏层下的
,然后用指数加权平均的方式来预测得到当前单个样本的的
。这样就实现了对测试过程单个样本的均值和方差估计。最后,利用再训练过程得到的
和
值计算出各层的值
最终BN算法的训练和测试的流程如下图所示:

Batch Norm让模型更加健壮
如果实际应用的样本与训练样本分布不同,即发生了covariate shift,则一般是要对模型重新进行训练的。在神经网络,尤其是深度神经网络中,covariate shift会导致模型预测效果变差,重新的训练模型各隐藏层的和
均产生偏移,变化。
而Batch Norm的作用恰恰是减小covariate shift的影响,让模型变得更加健壮,鲁棒性更强。
Batch Norm减少了各层,
之间的耦合性,让各层更加独立,实现自我训练学习的效果。
也就是说,如果输入发生covariate shift,那么因为Batch Norm的作用,对个隐藏层输出进行均值和方差的归一化处理,
和
更加稳定,使得原来的模型也有不错的表现.
BN优点
(1)神经网络本质是学习数据分布,如果寻来你数据与测试数据分布不同,网络的泛化能力将降低,batchnorm就是通过对每一层的计算做scale和shift的方法,通过规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到正太分布,减小其影响,让模型更加健壮。
(2)使用BN就可以使得不同层不同scal的权重变化整体步调更一致,可以使用更高的学习率,加快训练速度。
(3)防止过拟合。此时可以移除或使用较低的dropout,降低L2权重衰减系数等防止过拟合的手段。论文中最后的模型分别使用10%,5%和0%的dropout训练模型,与之前的40%-50%相比,可以大大提高训练速度。
至于更详细在CNN中的应用,建议参考下面的文章,很好的文章:
深度学习中的标准化模型
这里在简要说一下就是BN理解很容易,但是真正的反向传播不容易理解,大家应该重整体出发,搞懂为什么要这样,结合BP的更新过程就顺利多了,多思考一下,本篇就到这里了,那篇文章在下一篇翻译,那篇文章更多是说明BN的合理性,细节没有给出,所有这里整理了一下,不过下一篇的BN还是很建议看看的,他从不同的角度对BN进行了解释,好,本节结束。