Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
本博客只为学习使用,如有对原论文造成侵权,请联系博主删除。本博客为原创,如果转载请注明出处。
1.如果我们可在训练时保证非线性输入的稳定分布,就可以减少因饱和而产生的梯度消失等问题,进而加速网络训练。
解释:输入经过非线性激活函数以后,原来输入的分布状态会有所改变,例如,在第一层输入xs为高斯分布,经过sigmoid激活函数后的输出xo则不再是高斯分布,xo作为第二层输入时,与第一层输入xs不再一致,此时对于第二层来说,输入xo就不再是归一化的数据。网络层数越深,这种分布差异越大。Internal Covariate Shift在此处解释大概意思就是如上。
论文中定义Internal Covariate Shift : the change in the distribution of network activations due to the change in network parameters during training(在训练期间网络参数的变化导致激活函数中输出数值分布的变化)
2. BN就能够减少梯度对参数或者权重初始值的依赖,还可以有更高的学习率,不像SGD(随机梯度下降)那样需要小心的初始化权重并且需要小的学习率,BN还具有一定的正则化作用。
如果在每一层输入前加入白化过程就可以除去因Internal Covariate Shift造成的影响,但是白化过程需要大量的计算耗费。
3. 小批量归一化
输入x的每一维度上都加入归一化,归一化公式如下

在一层的输出之后,可以用下面的公式对数据集进行复原,因为经过非线性操作后,原数据分布被打乱。
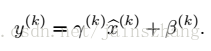

BN转换并非在每个训练样本中独立处理的,而是在batch中处理。在模型训练过程中,各层可持续学习,可以加速训练。
3.2 BN卷积神经网络


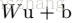
按照我的理解就是:假如上一层输入input1是经过归一化后的Gaussian分布,经过非线性激活后输出out1不再是Gaussian分布,也就意味着当前层输入input2(out1)不是Gaussian分布,所以需要一个BN转换,把上层的输出out1(此层的输入input2)转换成类似于原来的Gaussian分布。如此一来,不同层之间的Internal Covariate Shift就会减少。

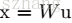
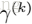
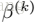
3.3 BN可以用高的学习率
传统的深层网络中,高的学习率可能会导致梯度爆炸或者梯度消失,也可能会进入到局部最优,但是BN就可以帮助解决这个问题。通过每层中归一化方式激活后,它能够防止因参数小幅度变动而造成数据在网络传播过程中变动不断放大的问题。例如,在更深的网络中使用sigmoid函数,这种方式可以更容易的让其停留在非饱和区域,而传统的方式很容易进入饱和区域,造成梯度消失。

4.1 随时间激活
为了验证BN的效果,在MNIST数据集上测试。训练网络5w步,每个minbatch=60个样本,采用交叉熵损失函数,对比效果如下图:

(a)是否使用BN测试的准确率,(b),(c)分别是不使用BN和使用BN的数据分布情况,可以看出(b)不使用BN的情况下数据分布变化很大,而使用了BN后,数据分布变化不那么明显。
4.2.1 加速训练的BN网络
简单的把BN应用在网络中并不能很好的体现该方法的优势,需要应用如下几个修改:
- 可以提高初始学习率
- 丢弃dropout
在inception结构中不使用dropout也可以在验证集上达到高的准确率,因此我们推测BN可以有类似于正则化的作用。
- 更彻底的打乱训练样本
- 减少L2正则化
- 加速学习率衰减
- 可移除LRN,LRN是神经网络中另一种方式
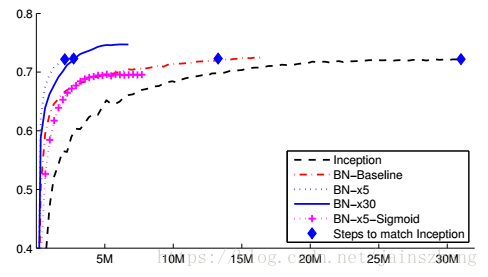
上图是验证集上精确度与训练迭代步数

上图描述了达到72.2%所需的迭代次数,以及能达到的最大精度

上图描述了不同方式的表现情况
5. 以上内容为个人对论文的理解,如果有错欢迎留言指出,谢谢。