-
BN的地位:
与激活函数层、卷积层、全连接层、池化层一样,BN(Batch Normalization)也属于网络的一层。与激活函数层、卷积层、全连接层、池化层一样,BN(Batch Normalization)也属于网络的一层。 -
BN的本质原理:
在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理(归一化至:均值0、方差为1),然后再进入网络的下一层。不过这儿的归一化层,可不像我们想象的那么简单,它是一个可学习、有参数(γ、β)的网络层。在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理(归一化至:均值0、方差为1),然后经过激活函数之后,才再进入网络的下一层。不过文献归一化层,可不像我们想象的那么简单,它是一个可学习、有参数(γ、β)的网络层。 -
归一化公式:
如果是仅仅使用上面的归一化公式,对网络某一层A的输出数据做归一化,然后送入网络下一层B,这样是会影响到本层网络A所学习到的特征的。比如我网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧,你强制把它给我归一化处理、标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于我这一层网络所学习到的特征分布被你搞坏了,这可怎么办?于是文献使出了一招惊天地泣鬼神的招式:变换重构,引入了可学习参数γ、β,这就是算法关键之处:
上面的公式表明,通过学习到的重构参数γ、β,是可以恢复出原始的某一层所学到的特征的。 -
最后Batch Normalization网络层的前向传导过程公式就是:
BN层是对于每个神经元做归一化处理,甚至只需要对某一个神经元进行归一化,而不是对一整层网络的神经元进行归一化。既然BN是对单个神经元的运算,那么在CNN中卷积层上要怎么搞?假如某一层卷积层有6个特征图,每个特征图的大小是100100,这样就相当于这一层网络有6100100个神经元,如果采用BN,就会有6100*100个参数γ、β,这样岂不是太恐怖了。因此卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理。 -
BN的作用:
在使用BN前,减小学习率、小心的权重初始化的目的是:使其输出的数据分布不要发生太大的变化。.
1)改善流经网络的梯度
2)允许更大的学习率,大幅提高训练速度:
你可以选择比较大的初始学习率,让你的训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
3)减少对初始化的强烈依赖
4)改善正则化策略:作为正则化的一种形式,轻微减少了对dropout的需求
你再也不用去理会过拟合中drop out、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项了参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
5)再也不需要使用使用局部响应归一化层了(局部响应归一化是Alexnet网络用到的方法,搞视觉的估计比较熟悉),因为BN本身就是一个归一化网络层;
6)可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度)
批量归一化(BN: Batch Normalization)
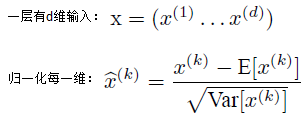
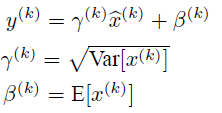

猜你喜欢
转载自blog.csdn.net/qq_42219077/article/details/88379566
今日推荐
周排行