动手学深度学习16:批量归一化
训练深层神经网络是十分困难的,特别是在较短的时间内使他们收敛更加棘手。
批量归一化可持续加速深层网络的收敛速度。结合resnet,批量规范化使得研究人员能够训练100层以上的网络。
训练深层网络
训练神经网络时出现的一些实际挑战
-
首先,数据预处理的方式通常会对最终结果产生巨大影响。
回想一下我们应用多层感知机来预测房价的例子。 使用真实数据时,我们的第一步是标准化输入特征,使其平均值为0,方差为1。 直观地说,这种标准化可以很好地与我们的优化器配合使用,因为它可以将参数的量级进行统一。
-
第二,对于典型的多层感知机或卷积神经网络。当我们训练时,中间层中的变量(例如,多层感知机中的仿射变换输出)可能具有更广的变化范围
直观地说,我们可能会猜想,如果一个层的可变值是另一层的100倍,这可能需要对学习率进行补偿调整。
-
第三,更深层的网络很复杂,容易过拟合。
对输入数据进行标准化处理的原因
使输入数据各个特征的分布相近:
- 神经网络学习的本质就是学习数据的分布,如果训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;
- 在使用小批量数据对神经网络进行训练时,若每批训练数据的分布各不相同,网络在每次迭代都去学习适应不同的分布,这会大大降低网络的训练速度;
为什么要使用批量归一化?
使用浅层模型时,随着模型训练的进行,当每层中参数更新时,靠近输出层的输出较难出现剧烈变化。对深层神经网络来说,随着网络训练的进行,前一层参数的调整使得后一层输入数据的分布发生变化,各层在训练的过程中就需要不断的改变以适应学习这种新的数据分布。所以即使输入数据已做标准化,训练中模型参数的更新依然很容易导致后面层输入数据分布的变化,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。最终造成靠近输出层输出的剧烈变化。这种计算数值的不稳定性通常令我们难以训练出有效的深度模型。如果训练过程中,训练数据的分布一直在发生变化,那么将不仅会增大训练的复杂度,影响网络的训练速度而且增加了过拟合的风险。
在模型训练时,在应用激活函数之前,先对一个层的输出进行归一化,将所有批数据强制在统一的数据分布下,然后再将其输入到下一层,使整个神经网络在各层的中间输出的数值更稳定。从而使深层神经网络更容易收敛而且降低模型过拟合的风险。
批量归一化的优势:
- 不加批量归一化的网络需要慢慢的调整学习率时,网络中加入批量归一化时,可以采用初始化很大的学习率,然后学习率衰减速度也很大,因此这个算法收敛很快。
- BN可以大大提高模型训练速度,提高网络泛化性能。
- 数据批量归一化后相当于只使用了S型激活函数的线性部分,可以缓解S型激活函数反向传播中的梯度消失的问题。
在激活函数前使用批量归一化
批量归一化可以看作在每一层输入和上一层输出之间加入了一个新的计算层,对数据的分布进行额外的约束,从而增强模型的泛化能力。但是批量归一化同时也降低了模型的拟合能力,归一化之后的输入分布被强制拉到均值为0和标准差为1的正态分布上来。以Sigmoid激活函数为例,批量归一化之后数据整体处于函数的非饱和区域,只包含线性变换(多层的线性函数跟一层线性网络是等价的,网络的表达能力下降),破坏了之前学习到的特征分布。为了恢复原始数据分布,保证非线性的获得,引入了变换重构以及可学习参数γ和β,其对应于输入数据分布的方差和偏差。对于一般的网络,不采用批量归一化操作时,这两个参数高度依赖前面网络学习到的连接权重(对应复杂的非线性)。而在批量归一化操作中,γ和β变成了该层的学习参数,仅用两个参数就可以恢复最优的输入数据分布,与之前网络层的参数解耦,从而更加有利于优化的过程,提高模型的泛化能力。
将数据从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。
实现
从零实现就略去了。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
nn.Linear(84, 10))
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
实验结果
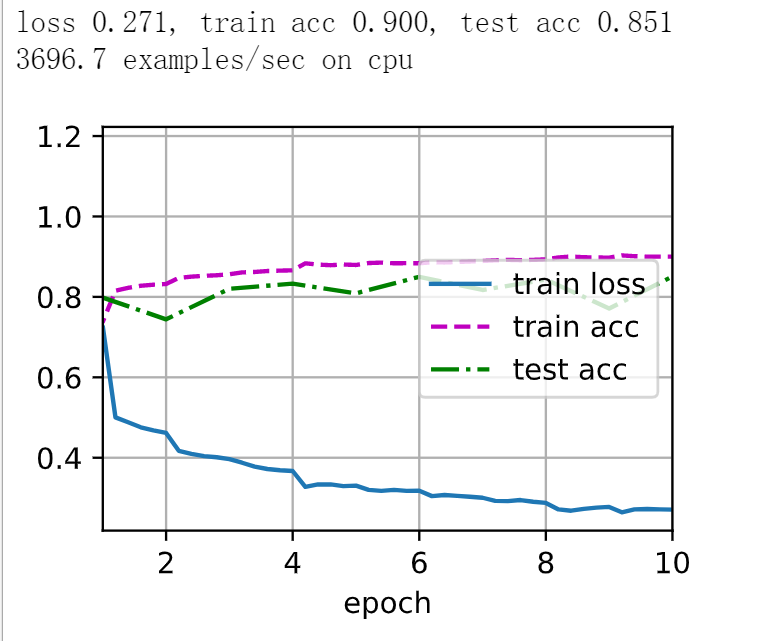
小结
- 在模型训练过程中,批量规范化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定。
- 批量规范化在全连接层和卷积层的使用略有不同。
- 批量规范化层和暂退层一样,在训练模式和预测模式下计算不同。
- 批量规范化有许多有益的副作用,主要是正则化。另一方面,”减少内部协变量偏移“的原始动机似乎不是一个有效的解释。