Pytorch 批量归一化(Batch Normalization)
0. 环境介绍
环境使用 Kaggle 里免费建立的 Notebook
小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。
1. 批量归一化
1.1 简介
深度卷积神经神经网络训练中的问题:
- 损失出现在最后,后面的层训练较快
- 数据在最底部
- 底部的层训练较慢
- 底部层一变化,所有都得跟着变
- 最后的那些层需要重新学习多次
- 导致收敛变慢
批量归一化就是去解决在学习底部层的时候避免变化顶部层这一问题而提出。
目前几乎所有主流的卷积神经网络都是或多或少用到了批量归一化。
Batch Normalization 论文地址:https://arxiv.org/abs/1502.03167
Understanding Batch Normalization 论文地址:https://arxiv.org/abs/1806.02375
1.2 BN 公式
固定小批量里面的均值和方差:
μ B = 1 ∣ B ∣ ∑ i ∈ B x i and σ B 2 = 1 ∣ B ∣ ∑ i ∈ B ( x i − μ B ) 2 + ϵ \mu_{B}=\frac{1}{|B|} \sum_{i \in B} x_{i} \text { and } \sigma_{B}^{2}=\frac{1}{|B|} \sum_{i \in B}\left(x_{i}-\mu_{B}\right)^{2}+\epsilon μB=∣B∣1i∈B∑xi and σB2=∣B∣1i∈B∑(xi−μB)2+ϵ
方差估计值中添加一个小的常量 ϵ > 0 \epsilon > 0 ϵ>0,以确保我们永远不会尝试除以零。
然后再做额外的调整(可学习的参数):
x i + 1 = γ x i − μ B σ B + β x_{i+1}=\gamma \frac{x_{i}-\mu_{B}}{\sigma_{B}}+\beta xi+1=γσBxi−μB+β
其中 γ \gamma γ 和 β \beta β 为可以学习的参数,形状和样本 x x x 相同:
- γ \gamma γ 为拉伸参数
- β \beta β 为偏移参数
- 作用在:
- 全连接层和卷积层的输出上,激活函数之前
- 全连接层和卷积层输入上
- 对于全连接层,作用在特征维
- 对于卷积层,作用在通道维
在应用批量归一化时,批量大小的选择可能比没有批量归一化时更重要。如果设置批量为 1 1 1,将无法学到任何东西。 这是因为在减去均值之后,每个隐藏单元将为 0 0 0。
1.3 BN 在做什么?
- 最初论文是想用它来减少内部协变量转移
- 后续有论文指出它可能就是通过在每个小批量里加入噪音来控制模型复杂度( μ ^ B \hat{\mu}_{B} μ^B 为随机偏移, σ ^ B \hat{\sigma}_{B} σ^B 为随机缩放):
x i + 1 = γ x i − μ ^ B σ ^ B + β x_{i+1}=\gamma \frac{x_{i}-\hat{\mu}_{B}}{\hat{\sigma}_{B}}+\beta xi+1=γσ^Bxi−μ^B+β - 因此没必要和 Dropout 混合使用
BN 先固定小批量中的均值和方差,然后学习出合适的偏移和缩放。
BN 可以加速收敛速度,但一般不改变模型精度。
1.4 BN 在不同情况下的作用
1.4.1 全连接层
假设全连接层输入为 x x x,权重和偏置参数为 W W W 和 b b b,激活函数为 ϕ \phi ϕ,批量归一化操作为 B N ( ) BN() BN(),则使用批量归一化后的输出为:
h o u t = ϕ ( B N ( W x + b ) ) . h_{out} = \phi(BN(Wx + b) ). hout=ϕ(BN(Wx+b)).
1.4.2 卷积层
对于卷积层,我们可以在卷积层之后和非线性激活函数之前应用批量归一化。当卷积有多个输出通道时,我们需要对这些通道的每个输出执行批量归一化,每个通道都有自己的拉伸(scale)和偏移(shift)参数,这两个参数都是标量。 假设我们的小批量包含 m m m 个样本,并且对于每个通道,卷积的输出具有高度 h h h 和宽度 w w w。 那么对于卷积层,我们在每个输出通道的 m h w m h w mhw 个元素上同时执行每个批量规范化。
1.4.3 预测过程
将训练好的模型用于预测时,我们不需要样本均值中的噪声以及估计每个小批次产生的样本方差了。 需要估算整个训练数据集的样本均值和方差,并在预测时使用它们得到确定的输出。和 Dropout 一样,批量归一化层在训练模式和预测模式下的计算结果也是不一样的。
2. 代码从零实现
2.1 batch_norm 函数
!pip install -U d2l
import torch
from torch import nn
from d2l import torch as d2l
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过 is_grad_enabled 来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
# 查看维度,若为 2,代表全连接层(batch,全连接层神经元个数),若为 4,代表卷积层(batch,输入通道数,核高,核宽)
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。
# 这里我们需要保持X的形状以便后面可以做广播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
moving_mean 和 moving_var 参数可以看作全局的均值和方差,在预测时使用,
eps 参数是为了防止除 0 0 0(防止方差为 0 0 0),
momentum 用于更新 moving_mean 和 moving_var,通常取 0.9 0.9 0.9。
momentum 这个用法可以参考 SGD with momentum :https://zh.d2l.ai/chapter_optimization/momentum.html
2.2 BatchNorm 层
class BatchNorm(nn.Module):
# num_features:全连接层的输出数量或卷积层的输出通道数。
# num_dims:2 表示全连接层,4 表示卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 非模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var
# 复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
2.3 在 LeNet 中加入 BN
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),
nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),
nn.Linear(84, 10))
应用在全连接层和卷积层之后,激活函数之前。
2.4 训练
# 之前 LeNet 学习率 0.9,这里调大一点 1.0
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
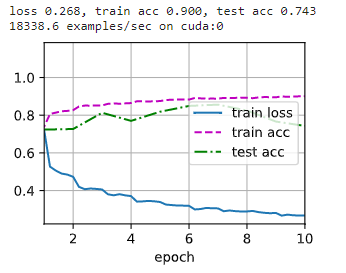
从结果上看测试集的精度变化有点抖动,但是损失比没加 BN 要小。在 6 − 7 6-7 6−7 个 epoch 的时候就收敛的很好了。
调整训练 epoch 数为 6 6 6:
lr, num_epochs, batch_size = 1.0, 6, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
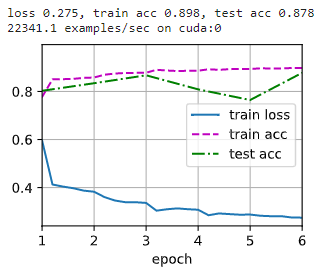
调整为最大池化和 ReLU 激活函数:
net2 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.ReLU(),
nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.ReLU(),
nn.Linear(84, 10))
lr, num_epochs, batch_size = 1.0, 10, 256
d2l.train_ch6(net2, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
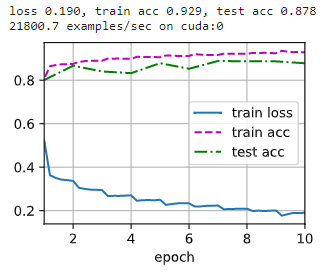
2.5 查看学到的拉伸参数 γ \gamma γ 和偏移参数 β \beta β
net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,))

3. 使用 Pytorch 简洁实现
直接使用深度学习框架中定义的 BatchNorm:
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
nn.Linear(84, 10))

可以看到使用 pytorch 的 API 由于它的代码已编译为C++或CUDA,所以训练得更快。
4. Q&A
Q:epoch,学习率,batch size 怎么调整?
A:epoch 通常可以大一点,batch size 设置要让GPU效率高,然后再调学习率。
Q:LayerNorm ,Instance Normalization 等方法和 BN 的异同:
A:都是在不同的维度进行 Norm。
分享一下课后练习,一个同学的答案:
在使用批量规范化之前,我们是否可以从全连接层或卷积层中删除偏置参数?为什么?
我认为可以,因为是否使用偏置不改变样本方差,而使用偏置b则数据x和均值u会分别变成x+b和u+b,做差的结果仍然是(x-u),和没有偏置的情况是一样的,因此偏置可以被去掉比较LeNet在使用和不使用批量规范化情况下的学习率。
- 绘制训练和测试准确度的提高。
- 你的学习率有多高?
不使用 Batch Norm 则学习率为 0.9,使用则变成 1.0,同时训练精度从 81.1% 提高到 90.3%,而测试精度则从78.1%提高到 78.3%。通过实验发现使用 Batch Norm 比能够整体提高训练和测试精度,10 个 epoch 结束时 train acc 提高 0.068, test acc 提高 0.066,loss 降低0.177,可见确实能够提高网络性能。
我们是否需要在每个层中进行批量规范化?尝试一下?
不删除BN层,则loss 0.268, train acc 0.901, test acc 0.861
只保留第二个和第四个BN层,则loss 0.289, train acc 0.894, test acc 0.787
只保留第一个和第三个BN层,则loss 0.286, train acc 0.893, test acc 0.820
只删除第一个BN层,则loss 0.272, train acc 0.899, test acc 0.769
只删除第二个BN层,则loss 0.269, train acc 0.901, test acc 0.774
只删除第三个BN层,则loss 0.272, train acc 0.901, test acc 0.857
只删除第四个BN层,则loss 0.283, train acc 0.895, test acc 0.857
可以看出删除全连接层后面的批量规范化对结果影响不大,因此实际上是可以删除的你可以通过批量规范化来替换暂退法吗?行为会如何改变? 似乎是可以的,BN 层兼具稳定训练过程和正则化的效果,将全连接阶段的BN层全部替换为弃置概率为 0.5 的 Dropout 层, 则 loss 0.486, train acc 0.827, test acc 0.763,对比而言精度不如使用BN层的情况,而且 train acc 与 test acc 的差距也更大,说明 BN 反而能够起到比dropout更好更稳定的正则化效果
确定参数 beta 和 gamma,并观察和分析结果。
通过实验观察模型中gamma和beta的情况。从结果来看,随着网络加深,beta 的值逐渐稳定到 0 附近,而 gamma 的值则逐步稳定到 1 到 2 之间,说明BN层确实有助于稳定中间结果的数据分布