概述
本文讲述了RDD依赖的原理,并对其实现进行了分析。
Dependency的基本概念
Dependency表示一个或两个RDD的依赖关系。
依赖(Dependency)类是用于对两个或多个RDD之间的依赖关系建模的基础(抽象)类。
Dependency有一个方法rdd来访问依赖的RDD。
当你使用transformation函数来构建RDD的血缘(lineage)时,Dependency代表了血缘图(lineage graph)中的边。
该抽象类的定义如下:
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
该类和实现类之间的关系如下图:
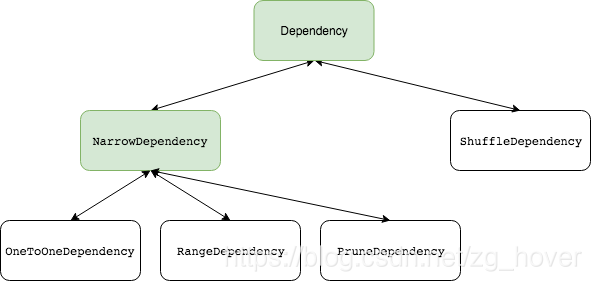
说明:其中绿色的类图框是抽象类,而白色的框是实体类。
Dependency的类型
每种类型的Dependency类,都实现该Dependency抽象类。各种Dependency实体类如下:
NarrowDependency
NarrowDependency是一个子抽象类。
NarrowDependency是一个抽象的基础Dependency类,它具有父RDD的窄narrow(有限:不会超过父RDD的数量)数量的分区(子RDD的某个分区最多对应父RDD的一个分区)。这些父RDD被用来计算子RDD的分区。也可以参考文章:spark2原理分析-RDD的Transformations原理分析中对窄转换的解释。
窄依赖的RDD允许通过pipelined执行,来提高执行效率。
其定义如下:
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}
ShuffleDependency
该类Dependency表示对shuffle阶段输出的依赖性。 请注意,在shuffle的情况下,RDD是瞬态的,因为我们在执行程序端不需要它。
每个ShuffleDependency都有一个唯一的应用程序范围的shuffleId编号,该编号在创建ShuffleDependency时分配(并在整个Spark的代码中用于引用ShuffleDependency)。定义如下:
val shuffleId: Int = _rdd.context.newShuffleId()
shuffle id随后由SparkContext进行跟踪。
ShuffleDependency是ShuffledRDD以及CoGroupedRDD和SubtractedRDD(但仅当partitioners(RDD和转换后)不同时) 的依赖关系。
为键值对RDD创建ShuffleDependency,即RDD [Product2 [K,V]],其中K和V分别是键和值的类型。
ShuffleDependency的成员
- aggregator
是RDD shuffle时map/reduce-side的聚合器。定义如下:
val aggregator: Option[Aggregator[K, V, C]] = None
该成员主要用于以下几种情况:
(1)该成员变量用于shuffle过程中进行的通过key进行聚合读取数据分区的情况下,也就是在 BlockStoreShuffleReader类中读取reduce任务的聚合key-value的结果。
(2) SortShuffleWriter类中进行记录的写入。
- shuffleHandle
该成员的定义如下:
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this)
shuffleHandle是ShuffleDependency的ShuffleHandle,在创建ShuffleDependency时进行分配。
- partitioner
partitioner属性是一个Partitioner,用于对shuffle输出进行分区。
在创建ShuffleDependency时指定Partitioner。
- keyOrdering
该成员变量的定义如下:
val keyOrdering: Option[Ordering[K]] = None
该成员用于在shuffle过程中对key进行排序。
- serializer
该成员变量的定义如下:
val serializer: Serializer = SparkEnv.get.serializer,
该成员用于在对shuffle过程中的数据进行serialize。
- mapSideCombine
该成员是一个boolean变量,表示:是否执行部分聚合(也称为地图侧合并)。
注意:本章先简单介绍一下ShuffleDependency,在后面还会详细介绍该依赖。
OneToOneDependency
从上一节的图上可以看出,该依赖继承自抽象类:NarrowDependency,它是一个窄依赖。它表示父RDD和子RDD的分区之间的一对一依赖关系。
通过以下程序可以更好的理解该依赖(Dependency):
scala> val r1 = sc.parallelize(0 to 100)
r1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:24
scala> val r3 = r1.map((_, 1))
r3: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[3] at map at <console>:26
scala> r3.dependencies
res4: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@24572adc)
scala> r3.toDebugString
res5: String =
(8) MapPartitionsRDD[3] at map at <console>:26 []
| ParallelCollectionRDD[2] at parallelize at <console>:24 []
我们来看一下该类的实现:
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
可以看到,该类的实现非常简单,继承NarrowDependency类,并重写了getParents方法。该方法返回给定分区的id列表。
RangeDependency
该类代表的依赖也是窄依赖(NarrowDependency),该类继承了NarrowDependency类。
该类表示父RDD和子RDD中分区范围之间的一对一依赖关系。
该依赖关系在UnionRDD中被使用,该RDD是通过SparkContext.union,RDD.union转换得到的。
我们来通过例子看一下具体的产生情况:
scala> val r1 = sc.parallelize(0 to 9)
r1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val r2 = sc.parallelize(10 to 19)
r2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> val unioned = sc.union(r1, r2)
unioned: org.apache.spark.rdd.RDD[Int] = UnionRDD[2] at union at <console>:28
scala> unioned.dependencies
res0: Seq[org.apache.spark.Dependency[_]] = ArrayBuffer(org.apache.spark.RangeDependency@2296ed0d, org.apache.spark.RangeDependency@6b174aa3)
scala> r1.dependencies
res1: Seq[org.apache.spark.Dependency[_]] = List()
scala> r2.dependencies
res2: Seq[org.apache.spark.Dependency[_]] = List()
scala> unioned.toDebugString
res3: String =
(16) UnionRDD[2] at union at <console>:28 []
| ParallelCollectionRDD[0] at parallelize at <console>:24 []
| ParallelCollectionRDD[1] at parallelize at <console>:24 []
PruneDependency
PruneDependency是一个窄依赖,表示PartitionPruningRDD与其父RDD之间的依赖关系。在这种情况下,子RDD包含父项的分区子集。
该类是一个私有类,代码实现如下:
private[spark] class PruneDependency[T](rdd: RDD[T], partitionFilterFunc: Int => Boolean)
extends NarrowDependency[T](rdd) {
@transient
val partitions: Array[Partition] = rdd.partitions
.filter(s => partitionFilterFunc(s.index)).zipWithIndex
.map { case(split, idx) => new PartitionPruningRDDPartition(idx, split) : Partition }
override def getParents(partitionId: Int): List[Int] = {
List(partitions(partitionId).asInstanceOf[PartitionPruningRDDPartition].parentSplit.index)
}
}
可以看到,该依赖的代表了父RDD的分区的子集。
总结
本文主要介绍了spark RDD 的依赖的原理,并对各种依赖进行了说明。简单分析了依赖的代码实现。