概述
本文介绍Saprk中DAGScheduler的基本概念。该对象实现了一个面向Stage的高层调度器。它为每个Job计算一个Stage的DAG图,并跟踪这些RDD和Stage的输出,并找到一个最小的代价的DAG图来运行该Job。
DAGScheduler介绍
在文章《spark2原理分析-Stage的实现原理》中,介绍了Stage的基本概念和Stage的提交实现原理。本文主要介绍 DAGScheduler调度器的实现。
DAGScheduler是spark的较高层次的调度器,它实现了stage-oriented(面向stage)的调度。它为每个job的stages计算并创建一个DAG,跟踪RDD和stage的输出。并找出一个最小代价的DAG去执行。然后,它把stage作为TaskSets提交给在集群上运行的TaskScheduler。一个TaskSet包含全部的可以立即执行的独立任务,这些任务基于目前集群中已经存在的数据运行,这些任务可能会执行失败。
RDD 2 Stage:
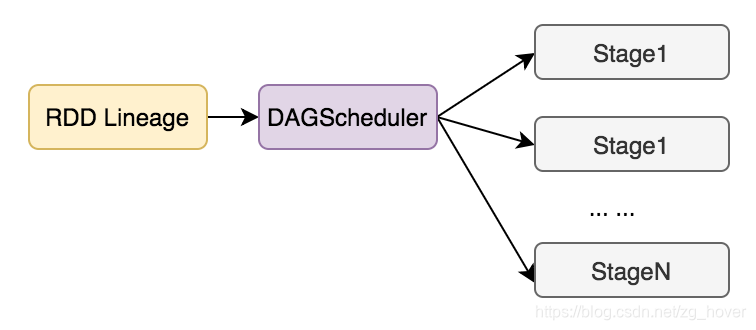
DAGScheduler的功能
- 为每个Job计算一个DAG图(根据rdd和父rdd的lineage来创建)
- 基于目前的cache的状态决定运行每个task的最佳位置,并把它们传递给TaskScheduler
- 处理由于shuffle输出文件丢失而产生的错误,可能会重新提交旧的stage。
为避免重复计算,DAGScheduler标记处哪些rdd已经被缓存。同样,会记录哪些在进行shuffle的map stage已经产生了输出文件,从而避免重复运行shuffle的map操作。
DAGScheduler会基于rdd的依赖关系,缓存或shuffling数据的位置来计算运行任务的最佳位置。
当任务运行完成后,所有的数据结构都会被清空。
为了从失败中恢复,同样的stage可能会运行多次。若由于前一个stage的map输出文件丢失,TaskScheduler报告了一个任务失败,DAGScheduler会重新提交丢失的stage。这是通过一个带有FetchFailed或ExecutorLost的CompletionEvent事件检测到的。DAGScheduler将等待一小段时间以查看其他节点或任务是否失败,然后为任何缺失的阶段(Stage)重新提交TaskSet(任务集)。
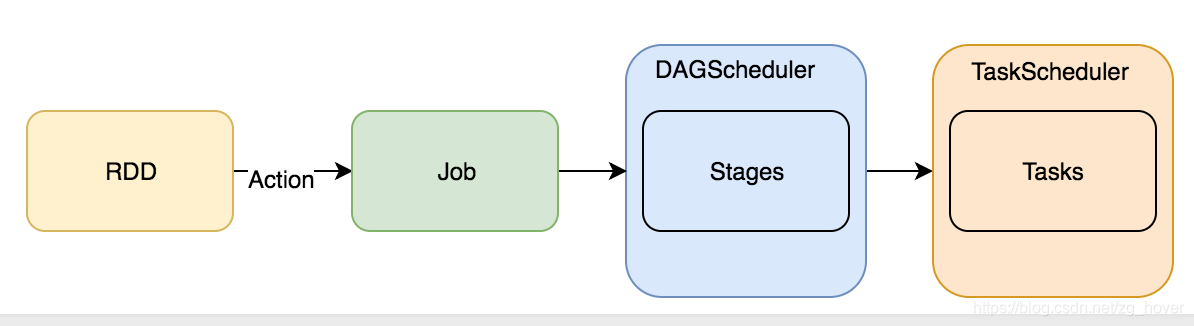
DAGScheduler的使用
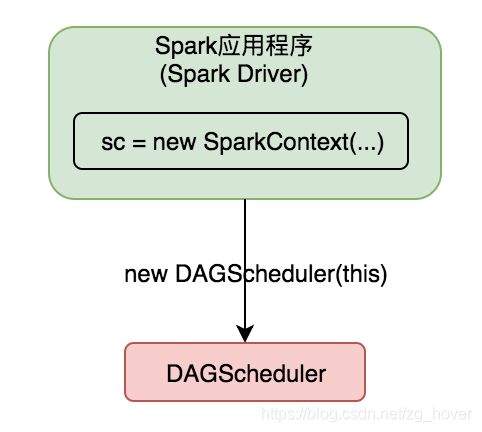
DAGScheduler实例在SparkContext中创建,SparkContext会把自己的成员变量,作为参数传递给DAGScheduler的构造函数。
如下图所示:
总结
本文对DAGScheduler的功能和使用相关概念进行了介绍,接下来的文章会详细分析DAGScheduler的实现原理,并对实现代码进行相应的剖析。