概述
本文介绍Spark任务执行框架中Stage的原理,并分析其实现机制。
Stage的基本概念
一个Stage是一个并行任务(Task实体)集,它们执行相同的计算逻辑,并作为Spark任务执行的一部分,所有的任务都具有相同的shuffle依赖。
调度器运行的每个任务DAG,在shuffle的边界处(发生shuffling时)被分解成多个stage,然后DAGScheduler以拓扑顺序运行这些阶段(Stage)。
前面一篇介绍Job的文章中提到过,Job中的分区对应RDD的分区,而在Spark中RDD中的一个分区对应了Stage中的一个任务,它属于一个RDD用于计算执行函数的部分结果,这些结果作为Spark Job的一部分。
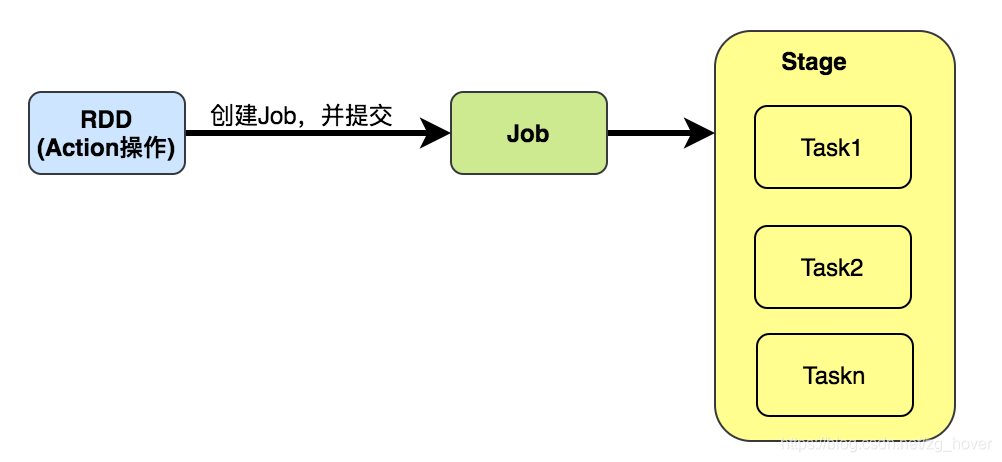
DAGScheduler将一个Job分成Stage集。每个Stage包含一系列narrow transformations(窄转换),这些转换操作可以在不进行shuffling的情况下完成,这些阶段在shuffle的边界(例如:shuffle发生的地方)处被分离,因此,可以说Stage是RDD graph在shuffle阶段分裂的结果。
在每个阶段RDD的窄转换(例如:map()或filter()等)操作被pipeline(多个任务形成流水线,中间结果在内存中,以便加快计算性能)成一个任务集,但是shuffle操作却需要依赖多个Stage。
在Stage生命中的某个时间点,Stage的每个分区都会转换为一个Tasks - 分别为ShuffleMapStage和ResultStage的ShuffleMapTask和ResultTask。
分区在Job中计算,并且结果阶段可能并不总是需要计算其目标RDD中的所有分区,例如,对于first()和lookup()等操作。

Stage的实现合约
在Spark中,有两种不同的Stage,实现这两种类型的Stage需要遵循Stage的实现合约(实现Stage抽象类)。
Stage的抽象类声明如下:
private[scheduler] abstract class Stage
为了能够更好的理解后面的两种具体的Stage,下面对Stage的抽象类的成员做一个说明:
| 成员名 | 类型 | 说明 |
|---|---|---|
| id | Int | Stage的id,是Stage的唯一标识 |
| rdd | RDD[_] | 此Stage依赖的Stage列表(通过shuffle依赖关系得到) |
| numTasks | Int | 此Stage的总任务数。 |
| parents | List[Stage] | 此Stage依赖的Stage列表 |
| firstJobId | Int | 对于FIFO调度来说,此变量是此Stage属于的第一个Job的ID |
| callSite | CallSite | 用户编写的程序中与该Stage相关的部分 |
| numPartitions | Int | RDD的分区数 |
| jobIds | 此Stage属于的Job集 | |
| nextAttemptId | 此Stage下一次尝试的ID | |
| _latestInfo | 返回最近的Stage信息结构:StageInfo | |
| fetchFailedAttemptIds | 记录Stage尝试失败的次数 | |
| makeNewStageAttempt | 为该Stage创建一个新的StageInfo和ID | |
| latestInfo | 返回该Stage最新的StageInfo信息 | |
| findMissingPartitions | 返回需要计算(missing)但还没计算的分区id集合 |
对于这些成员,有几个需要重点说明:
- numTasks
该成员代表的是Stage的总任务数。但对于result stages可能不需要计算所有分区,例如:first(),lookup(),take()等。
ResultStage
ResultStages阶段在RDD的各个分区上执行一些功能函数,来处理RDD的Action转换的执行结果。
该实体的定义如下:
private[spark] class ResultStage(
id: Int,
rdd: RDD[_],
val func: (TaskContext, Iterator[_]) => _,
val partitions: Array[Int],
parents: List[Stage],
firstJobId: Int,
callSite: CallSite)
extends Stage(id, rdd, partitions.length, parents, firstJobId, callSite) {
ResultStage对象会捕获函数func去执行,并把该函数应用参数’partitions’表示的分区ID集中的每一个分区。
注意:ResultStage是Job的最后一个Stage。
在提交Stage时会先递归找到该Stage依赖的父级Stage,并先提交父级Stage。
ShuffleMapStage
在执行Stage的DAG(有向无环图)中,ShuffleMapStage是一个中间阶段,为其他阶段生成数据。
它为一个shuffle过程产生map操作的输出文件。它也可能是自适应查询规划/自适应调度工作的最后阶段。
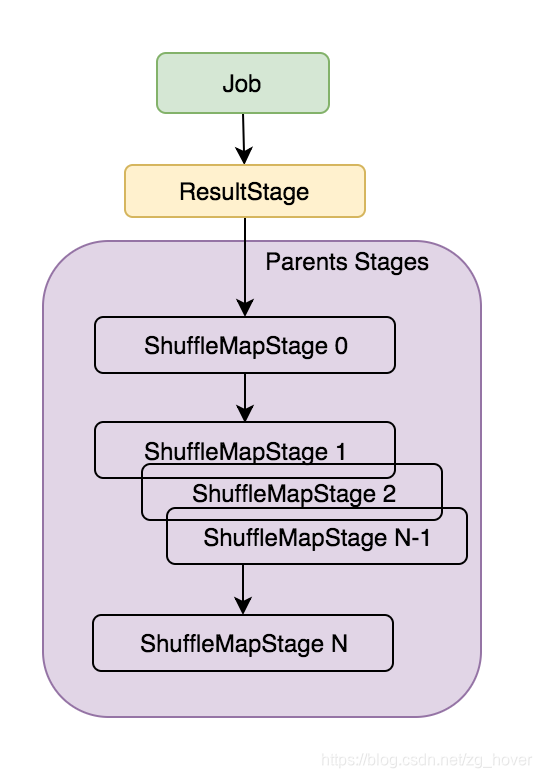
Stage的提交过程
通过上一节的分析可知,在提交Job时会先创建一个ResultStage,再根据RDD的血缘关系(lineage)查找与ResultStage相关联的RDD的分区,再根据这些分区来创建新的Stage。
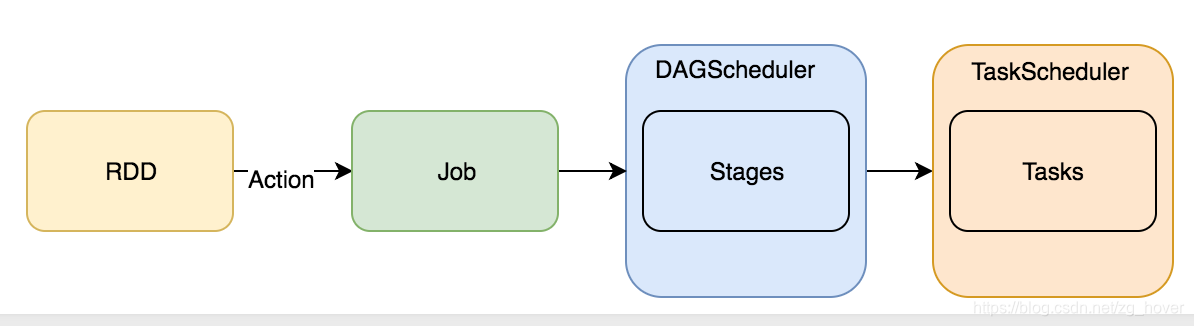
下图是Job提交的总体流程:
下图是提交Stage的流程:
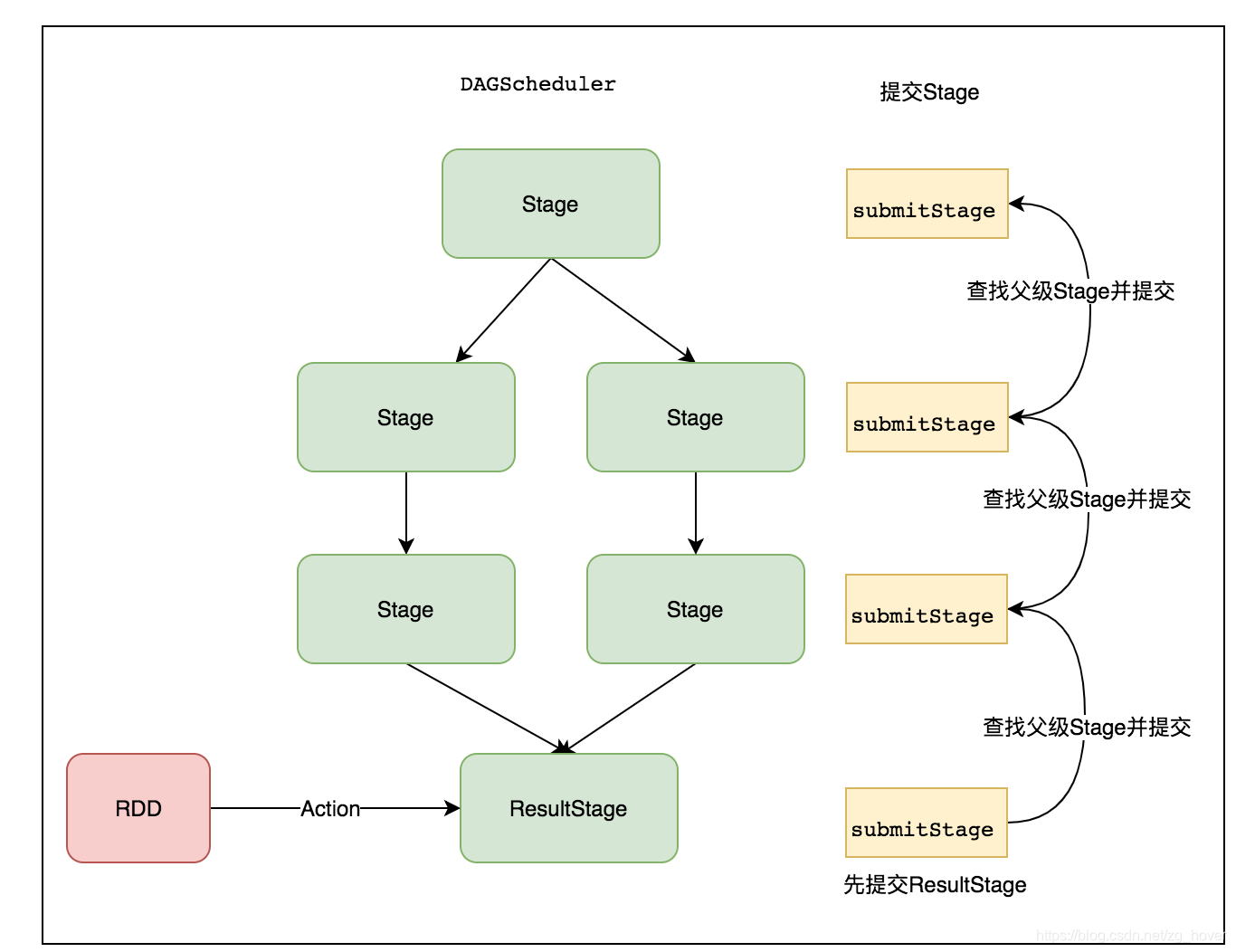
在提交Stage时,也是通过递归提交最先依赖的Stage,最后提交ResultStage。实现过程如下:
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
...
// 创建一个阶段:最后的一个阶段
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
...
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
// 向事件处理总线发起SparkListenerJobStart事件(会在后面的文章中讲到)
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 提交最后一个阶段
submitStage(finalStage)
我们看一下阶段的提交的实现,阶段提交在submitStage函数中实现:
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
...
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 查找并获取依赖的父Stage
val missing = getMissingParentStages(stage).sortBy(_.id)
...
if (missing.isEmpty) {
...
// 已经找到全部的依赖Stage并已提交,最后提交最后一个Stage
submitMissingTasks(stage, jobId.get)
} else {
// 先提交依赖的父Stage
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
从提交Stage的代码实现中可以看出,先创建最后一个Stage,而在提交时,提交Stage时会先提交依赖的父Stage。
总结
本文说明了Stage的实现原理,并对Stage的提交过程进行了分析。