概述
本文介绍RDD的checkpoint的作用和原理,并对checkpointing的实现进行分析。
RDD checkpoint的基本概念
RDD可能经过任意多个transformations操作,导致RDD血缘(lineage)任意的增长,Spark提供了一种将整个RDD进行持久化保存的方法。这样,当节点发生故障而无法运行时,Spark不需要从头开始重新计算丢失的RDD片段,而是使用一种类似于快照的方式,从快照的点开始计算剩下的血缘的RDD,这个特征被称为checkpointing。
在进行checkpointing时,整个RDD将持久化到磁盘上,包括数据和RDD的血缘(lineage)。在checkpointing完成后,RDD的依赖关系以及有关其父RDD的信息将被删除,因为它们不再需要重新计算。
换一种说话,checkpointing是一个截断RDD血缘,并把RDD持久化保存到外部文件系统,例如HDFS,S3或本地文件系统的过程。
由于Checkpointing会把RDD的数据写到Spark外部,因此checkpointing的数据比Spark应用程序存活的时间长一些,并且它会强制进行RDD评估(evaluation)。
Checkpointing将会占用更多的外部存储空间,它的写操作将会消耗系统资源,所以它会比persisting(持久化)操作要慢。但是,checkpointing不会使用任何Spark内存,而且若Spark worder失败,也不会进行重新计算。
checkpointing的使用
当我们更加关心失败和重新计算的资源消耗而不是外部存储空间时,最好使用checkpointing。另外,建议当jobs很慢时使用持久化(persisting),当jobs失败时使用checkpointing。
若Spark作业由于内存不足错误而失败,则checkpointing将减少资源消耗并降低失败的可能性,而不会耗尽执行器(executor)上的内存。
若作业由于网络错误或集群的抢占而失败,可以通过checkpointing把长时间运行的job分解为较小的段,来降低失败的可能性。
在调用checkpoint函数前,需要先通过SparkContext调用setCheckpointDir(directory:String)方法设置checkpoint目录。若运行在集群模式,必须是HDFS路径。
Checkpointing的分类
有两类Checkpointing:

- reliable checkpointing
这类checkpointing将RDD数据写入到可靠的存储系统中,比如:HDFS,S3等。它允许spark driver(驱动程序)在当前计算的状态下失败时重新启动。
- local checkpointing
local checkpointing在性能和容错性之间进行权衡,它会跳过把数据保存到可靠且容错性好的存储系统的步骤。把数据写入每个执行器中的本地临时存储。这对于RDD构建需要经常截断的长血缘(long lineage)(例如GraphX或Spark streaming等)的应用非常有用。
checkpointing的实现
在spark中定义了一个checkpointing的抽象类:RDDCheckpointData,有两个类继承了该抽象类,他们分别是:ReliableRDDCheckpointData和LocalRDDCheckpointData。这两个类分别对应checnpointing的两种类型。
另外,定义了一个checkpoint的RDD类型,有一个抽象类CheckpointRDD来描述。分别有两个类实现了该抽象类:LocalCheckpointRDD和ReliableCheckpointRDD。
Reliable Checkpointing
基本原理
上面已经提到过,reliable checkpointing,需要把RDD的数据写入到可靠的外部存储系统中。在执行checkpoint操作之前,必须要设置checkpoint的目录,若是集群模式,该目录必须是HDFS目录。
设置checkpoint目录的函数如下:
SparkContext.setCheckpointDir(directory: String)
若spark运行在集群模式,而设置的路径是本地路径,此时将会输出警告日志。在集群模式下,当spark driver程序试图从它所在的本地文件系统重建checkpointed RDD时,将会发生错误,因为checkpoint文件实际上保存在执行器(executor)所在的机器上。
可以调用RDD.checkpoint()来标记一个需要checkpointing的RDD。RDD将保存到检查点目录内的文件中,并且将删除对其父RDD的所有引用。注意:必须在对此RDD执行任何作业之前调用此函数。
另外,在源码中有一个建议需要注意:
强烈建议将checkpointed RDD保存在内存中,否则将其保存在文件中将需要重新计算。
ReliableRDDCheckpointData
当调用RDD.checkpoint()函数时,会创建一个ReliableRDDCheckpointData类。该类包含了对RDD进行checkpointing需要的所有信息,包括:执行checkpointing的函数(doCheckpoint),checkpointing的路径,checkpointing的辅助清理函数等。
ReliableCheckpointRDD
它是一个RDD,确切的说是一个CheckpointRDD,该RDD是从先前已经写入的可靠存储系统的checkpoint文件中读出的。该类包括以下几个主要变量:
| 成员名 | 说明 |
|---|---|
| hadoopConf | hadoop的配置实体 |
| cpath | checkpoint的路径 |
| fs | 文件系统实体 |
| broadcastedConf | Broadcast实体,该变量将会传递给集群中的每个实体 |
| partitioner | 分区实体 |
包括以下几个成员函数:
| 成员名 | 说明 |
|---|---|
| getPartitions | 返回checkpoint 文件中的分区 |
| getPreferredLocations | 返回和所给分区相关联的checkpoint文件的位置 |
| compute | 读取和所给分区相关联的checkpoint的内容 |
| checkpointFileName | 返回所给分区的checkpoint文件的名字 |
| writeRDDToCheckpointDirectory | 把RDD写入checkpoint文件中,并返回ReliableCheckpointRDD |
| writePartitionToCheckpointFile | 把RDD的一个分区写入到checkpoint文件中 |
| writePartitionerToCheckpointDir | 把所给分区写入到checkpoint给定目录 |
| readCheckpointedPartitionerFile | 从给定的checkpoint目录下读取一个RDD分区。 |
| readCheckpointFile | 读取指定checkpoint目录中的内容 |
Local Checkpointing
基本原理
localCheckpoint使用Spark的缓存层(caching layer)对local checkpointing进行标记。
localCheckpoint适用于希望截断RDD 血缘图(RDD linage graph)的用户,但跳过了访问外部可靠存储系统的系统消耗。这对于具有需要定期截断的长血统(long linage)的RDD很有用,例如,GraphX。
local checkpointing为了性能牺牲了容错性。 特别是,检查点数据(checkpointed data)被写入执行器中的临时本地存储系统而不是可靠的容错存储系统。 其结果是,如果执行程序在计算过程中失败,则可能无法再访问检查点数据(checkpointed data),从而导致无法恢复失败的作业。
local checkpointing不通过SparkContext.setCheckpointDir设置checkpointing目录。
localCheckpoint和LocalRDDCheckpointData
在Spark的缓存层(caching layer)之上检查点(checkpointing)的实现。当调用RDD.localCheckpoint()时会创建一个LocalRDDCheckpointData类。
LocalCheckpointRDD
一个虚拟的CheckpointRDD,以便在任务失败时提供错误消息。
该类只是一个占位符,因为原始的checkpointed RDD应该完全缓存。 只有当执行器(executor )失败或者用户明确地取消原始RDD时,Spark才会尝试计算此CheckpointRDD。 但是,当发生这种情况时,我们必须提的错误消息。
spark的caching和checkpoint的关系
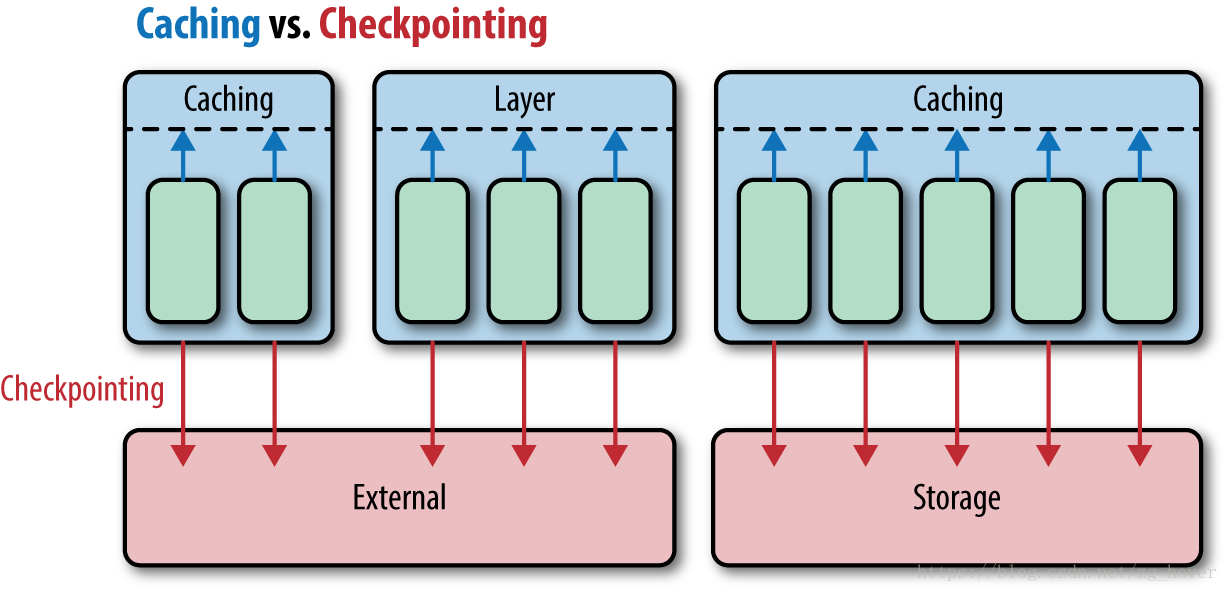
从上图可以看出,checkpoint是按分区进行保存的,这样读取的时候也能够读取分区的数据。
总结
本文分析了RDD checkpointing的原理,包括checkpointing的分类和实现。checkpoint的实战部分,可以留意我接下来的spark实战系列文章之:《spark2实战-checkpointing的使用》
参考文献
- spark-2.3源码
- 《高性能Spark》