概述
本文描述了Spark2的job的实现框架,并对其各个组成部分进行了介绍。
spark的Job介绍
从前面的文章中我们知道:一般来说Spark RDD的转换函数(transformation)不会执行任何动作,而当Spark在执行RDD的action函数时,Spark调度程序(scheduler)会构建执行图(graph)并发起一个Spark作业(Job)。
Job由很多的Stage构成,这些Stage是在转换中实现最终RDD所需数据的步骤。
每个Stage由一组在执行器(executor)上并行计算的任务(task)构成。
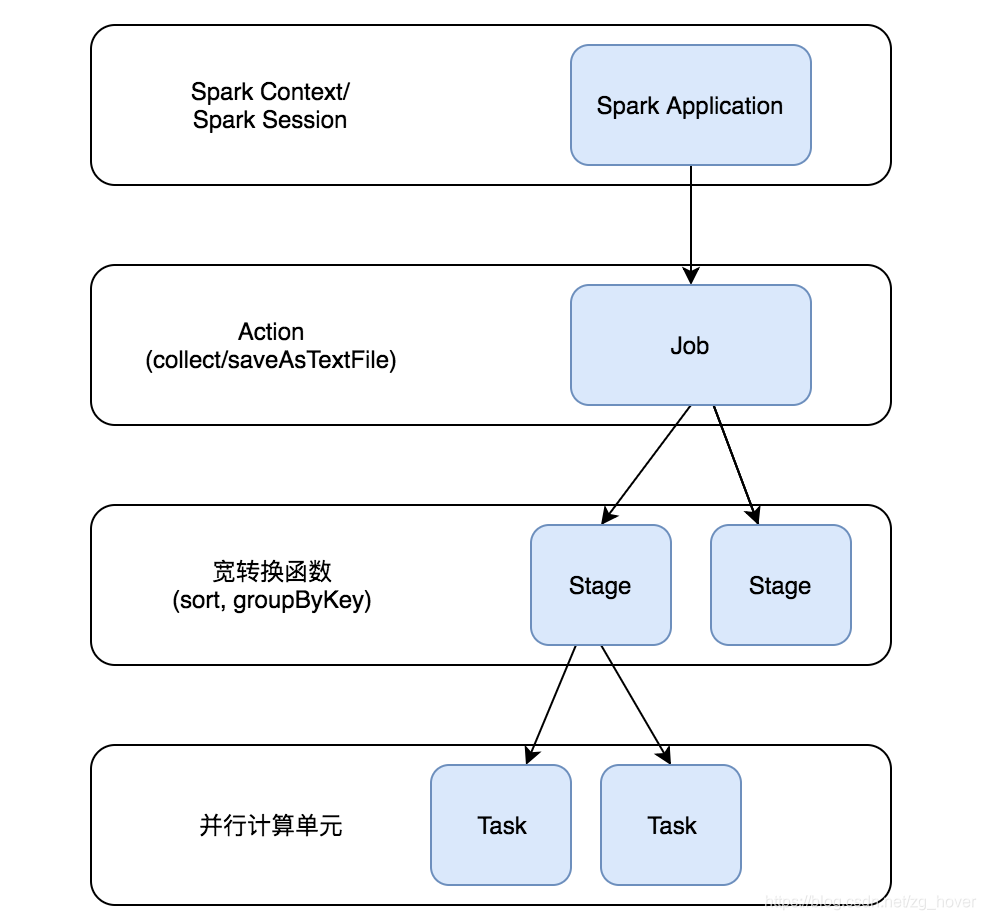
上图说明了Job->Stage->Task的创建过程:
- 通过SparkContext或SparkSession来执行应用程序
- 在应用程序中若有Action操作,此时会生成Job,并提交
- 若在Job中需要进行宽转换等操作,则会创建若干的Stage
- Stage会创建出一系列的Task,这些Task会在各个执行器(executor)中并行执行
DAG
在Spark任务调度的高的层面,Spark会根据RDD的依赖关系,为每个Job构建Stage的有向无环图(DAG)。在Spark中,这被称为DAG Scheduler。
DAG Scheduler为每个Job构建一个stage graph,确定运行每个任务(Task)的位置,并将该信息传递给TaskScheduler。TaskScheduler负责在集群上运行任务。 TaskScheduler创建一个包含分区之间依赖关系的图(graph)。
DAGScheduler
实现面向阶段(Stage)的高层次的调度。 它为每个Job计算出一个由Stage组成的DAG,跟踪RDD和Stage的输出,并找到运行Job的最小执行计划。
然后,它将阶段(Stage)作为TaskSets提交给已经实现的TaskScheduler,再由TaskScheduler在集群上运行TaskSets。
TaskSet包含完全独立的任务,这些可以根据群集中已有的数据立即运行(例如,映射前一阶段的输出文件),但如果此数据不可用,则任务可能会失败。
DAGScheduler除了创建Stage的DAG,它们还会根据目前的cache状态来决定运行每个任务(task)的最优位置,并把这些任务发送给较低层次的TaskScheduler。同时,它还会处理由于shuffle输出文件丢失产生的失败任务,这种失败会导致一些已经计算过的Stage从新被提交。不是由shuffle文件丢失引起的Stage内的失败由TaskScheduler处理,它将在取消整个Stages之前重试每个任务小几次。
Job
Job由[[ActiveJob]]表示,是提交给调度程序(scheduler)的顶级工作项。例如,当用户调用一个action操作函数(如count())时,将会通过submitJob提交作业。每个作业(Job)可能需要执行多个阶段(Stage)来构建中间数据。
Stages
Stage是job中一组计算中间结果的任务集,每个task在相同的RDD的分区上执行计算。
有两种类型的Stage(阶段):[[ResultStage]],用于执行Action(动作)的最后阶段,[[ShuffleMapStage]],用于为shuffle写入graph(地图)输出文件。若这些Job重复使用相同的RDD,则Stage通常会在多个Job中共享。
Tasks
每个Stage由一组Task组成。Task(任务)是执行层次结构中的最小单元,每个单元可以表示一个本地计算。
一个阶段中的所有任务在不同的数据片段上执行相同的代码。一个Task不能在多个执行器(executor)上执行。
但是,每个执行器(executor)都有一个动态分配器的资源数用来运行任务,并且可以在其生命周期内并发运行多个任务。
每个阶段(Stage)的任务数对应于该阶段的输出RDD的分区数。
总结
本文介绍了Spark Job的执行框架,对给执行框架中的各个成员进行了简要的说明。后续的文章将详细分析Spark Job执行框架中的各个成员的实现原理。