概述
本文介绍了Spark的几种部署模式,以及在这种模式下的总体架构。各种模式的详细实现讲解会在其他文章中介绍。
Spark架构概览
Spark使用:主/从(master/slave)架构模式。和一般的主从模式的分布式系统不同(例如:zookeeper等),Spark还可以通过yarn或mesos来分配和管理资源。
Spark可以单机运行,单机运行时所有角色都运行在同一个jvm进程中,这种模式可以用来进行调试程序或测试数据量较小的任务。当然,常用的还是集群模式,根据使用的集群资源管理机制不同,Spark的部署模式也不相同。Spark可以使用的集群资源管理器有以下几种:
-
Standalone:
Spark自己实现的简单集群管理器,可以轻松设置集群。 -
Hadoop YARN:
Hadoop 2中的资源管理器。 -
Apache Mesos:
一般的集群管理器,也可以运行Hadoop MapReduce和服务应用程序。 -
Kubernetes:
一个开源系统,用于自动化容器化应用程序的部署,扩展和管理。
Standalone模式
这是spark的内建部署和集群管理模式,在这种模式下,spark会启动一个叫master的角色和服务来管理整个spark集群的资源。通过master还可以查看整个集群的任务和资源情况。
这是最简单的spark部署模式。
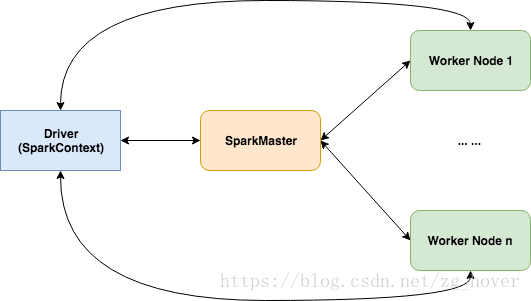
从上图可以看出,在standalone模式下,spark通过启动的spark master来管理整个集群的资源,并对任务进行调度。
这种模式下的spark也可以运行在单机上,在单机上可以模拟分布式程序执行,可以打印提交程序的调试信息,方便对提交的任务进行调试。
手动启动standalone群集
可以通过执行以下命令来启动spark master:
./sbin/start-master.sh
一旦启动,spark master将为自己打印一个spark:// HOST:PORT URL,可以使用它来将worker连接到它,或者将其作为"master"参数传递给SparkContext。还可以在master的Web UI上找到此URL,默认情况下为http:// localhost:8080。
同样,您可以启动一个或worker并通过以下方式将他们连接到master:
./sbin/start-slave.sh <master-spark-URL>
启动后,查看master的Web UI(默认情况下为http:// localhost:8080)。可以看到其中列出的新节点,以及CPU和内存的数量(减去操作系统剩余的1 GB)。
更加详细的standalone的讲解可以参看后面文章的讲解。
Spark on yarn模式
在yarn部署模式下,spark有两种部署模式:
- 客户端部署模式
- 集群部署模式
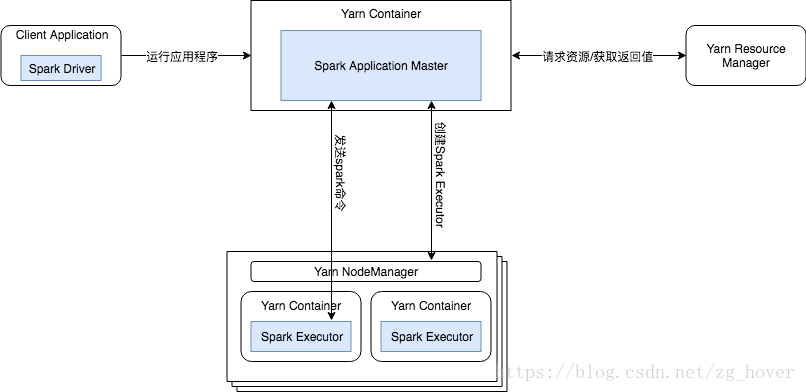
客户端部署模式
在客户端部署模式下,Spark Driver的生命周期和任务的生命周期保持一致,在任务运行过程中,Driver可以和任务进行互动,向任务发送命令,或者获取任务的运行状态。
集群部署模式
在群集模式下,Spark Driver 在yarn群集主机上的ApplicationMaster container 中运行。yarn容器中的单个进程负责驱动应用程序和从yarn请求资源。启动应用程序的客户端不需要在应用程序的整个生命周期内运行。
集群模式的架构图如下所示:
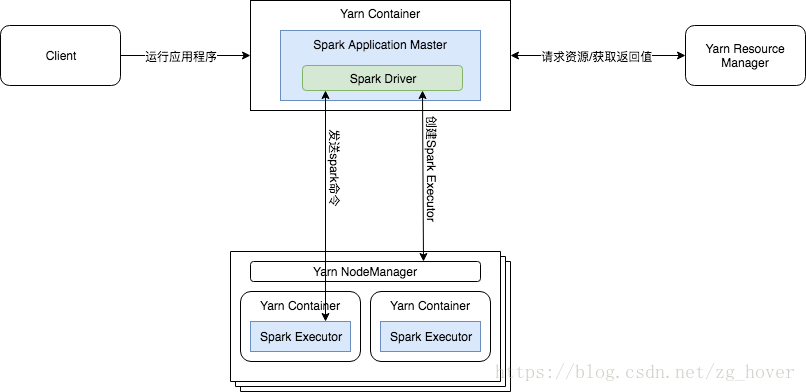
群集模式不适合以交互方式使用Spark。需要用户输入的Spark应用程序(例如spark-shell和pyspark)需要Spark驱动程序在启动Spark应用程序的客户端进程内运行。这些交互式应用程序不能在集群模式下运行。
Spark on mesos模式
在standalone模式下集群的管理器是独立的spark master服务,在mesos部署模式下, Mesos master将作为集群管理器(Cluster Manager)。
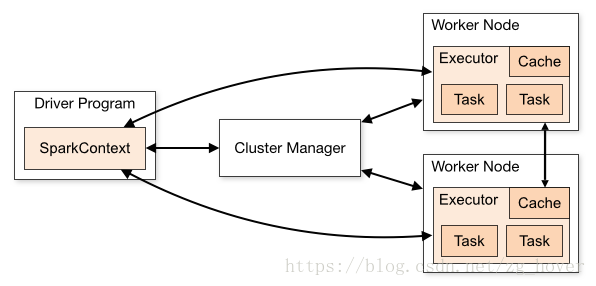
更加详细一点的架构模型如下:
注意上图的箭头,通过上图可以看到mesos master和Worke node的交互,以及Driver Program和Spark Executor的交互。

Spark on Kubernetes模式
spark-submit可以直接用于向Kubernetes集群提交Spark应用程序。提交机制的工作原理如下:
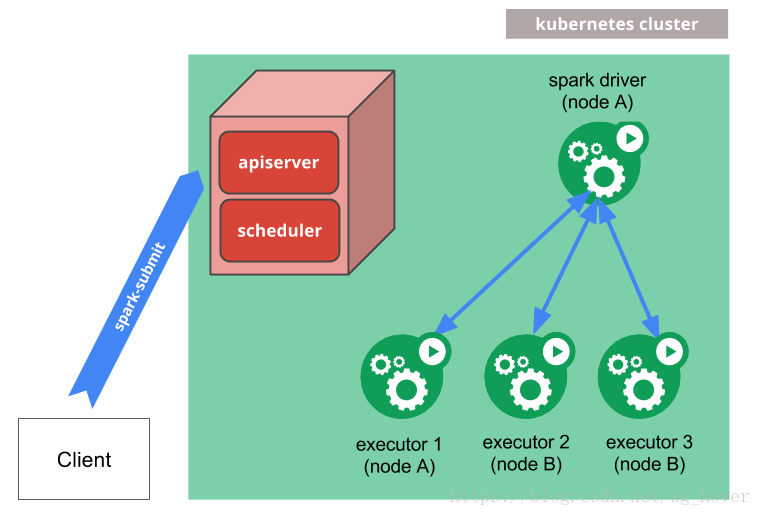
- Spark创建一个运行在Kubernetes pod中的Spark Driver。
- Spark Driver创建executors,这些执行程序也在Kubernetes pod中运行并连接到它们,并执行应用程序代码。
- 当应用程序完成时,执行程序的pods会终止并清理,但驱动程序的pods会保留日志并在Kubernetes API中保持“已完成”状态,直到它最终被垃圾回收或被手动清理。
请注意,在完成状态下, driver pod不使用任何计算或内存资源。
驱动程序(driver)和执行器(executor)的pod的调度由Kubernetes处理。可以通过节点选择器(node selector)使用其配置属性在可用节点的子集上调度driver和executor的pod。在将来的版本中,可以使用更高级的调度提示,如node/ pod关联。