概述
本文介绍RDD的Shuffle原理,并分析shuffle过程的实现。
RDD Shuffle简介
spark的某些操作会触发被称为shuffle的事件。shuffle是Spark重新分配数据的机制,它可以对数据进行分组,该操作可以跨不同分区。该操作通常会在不同的执行器(executor)和主机之间复制数据,这使shuffle成为复杂且非常消耗资源的操作。
Shuffle背景
为了理解shuffle过程,我们可以拿reduceByKey操作进行举例。reduceByKey操作会产生一个新的RDD,其中单个键的所有值都组合成一个元组(tuple) - 对key和与该key关联的所有值执行reduce函数的结果。挑战在于,并非单个key的所有值都必须位于同一个分区,甚至是同一个机器上,但它们必须能够被定位到才能计算结果。
在Spark中,数据通常不跨分区分布,以便特定操作能够访问到必要位置。
在计算过程中,单个任务将在单个分区上运行 - 因此,要组织单个reduceByKey reduce任务执行的所有数据,Spark需要执行all-to-all的操作。Spark必须从所有分区读取以查找所有key的所有值,然后将各个值组合在一起以计算每个key的最终结果 - 这个过程称为shuffle。
虽然新shuffle数据的每个分区中的元素集是确定的,且分区本身的顺序也是确定的,但分区中的数据的顺序是不确定的。如果在shuffle后希望得到特定顺序的数据,则可以使用:
- 在mapPartitions使用例如.sorted对每个分区进行排序
- repartitionAndSortWithinPartitions在同时重新分区的同时有效地对分区进行排序
- sortBy来创建一个全局排序的RDD
可能导致shuffle的操作包括以下几种:
- 重新分区(repartition)操作,例如: repartition和 coalesce。
- ByKey操作(计数除外),例如:如groupByKey和reduceByKey
- 联合(join)操作,例如:cogroup和join。
shuffle对性能的影响
shuffle操作十分昂贵(消耗性能和资源),因为它包括:磁盘I/O,数据序列号,网络I/O等操作。为了对数进行shuffle,Spark创建了一个任务集,map任务负责组织数据,reduce任务负责对数据进行聚合。这两个术语来自MapReduce,但与Spark的map和reduce操作并没有直接关系。
在内部,各个map任务的结果会保留在内存中,直到它们不再合适(fit)。然后,这些结果基于目标分区进行排序并写入单个文件。reduce任务读取相关的排好序的数据块。
某些shuffle操作会消耗大量的堆内存,因为它们使用内存中的数据结构来在传输记录之前或之后组织记录。具体来说,reduceByKey和aggregateByKey在map端创建这些结构,并且’ByKey操作在reduce端生成这些结构。当数据不适合内存时,Spark会将这些写入到磁盘,从而导致磁盘I / O的额外开销和垃圾收集的增加。
Shuffle还会在磁盘上生成大量中间文件。从Spark 1.3开始,这些文件将被保留,直到对应的RDD不再被使用,且被垃圾回收。这样做是为了在重新计算谱系时不需要重新创建shuffle文件。如果应用程序保留对这些RDD的引用或GC不经常启动,则垃圾收集可能仅在很长一段时间后才会发生。这意味着长时间运行的Spark作业可能会占用大量磁盘空间。配置Spark上下文时,spark.local.dir配置参数指定临时存储目录。
可以通过调整各种配置参数来调整shuffle行为。具体的配置将会在实战部分讲到。
注:以上两端来自官方文档对shuffle过程的说明。
理解shuffle过程
从以上分析我们可以看出,分区之间的物理数据的搬迁被称为shuffling。当需要构建新的RDD时,为了构建新的分区需要整合多个分区的数据,就会发生shuffling。例如:当通过key对成员进行分组时,Spark可能会扫描所有分区,来发现具有相同key的元素,然后在物理上对这些数据进行分组。
从以下图中可以看出具体shuffling过程:
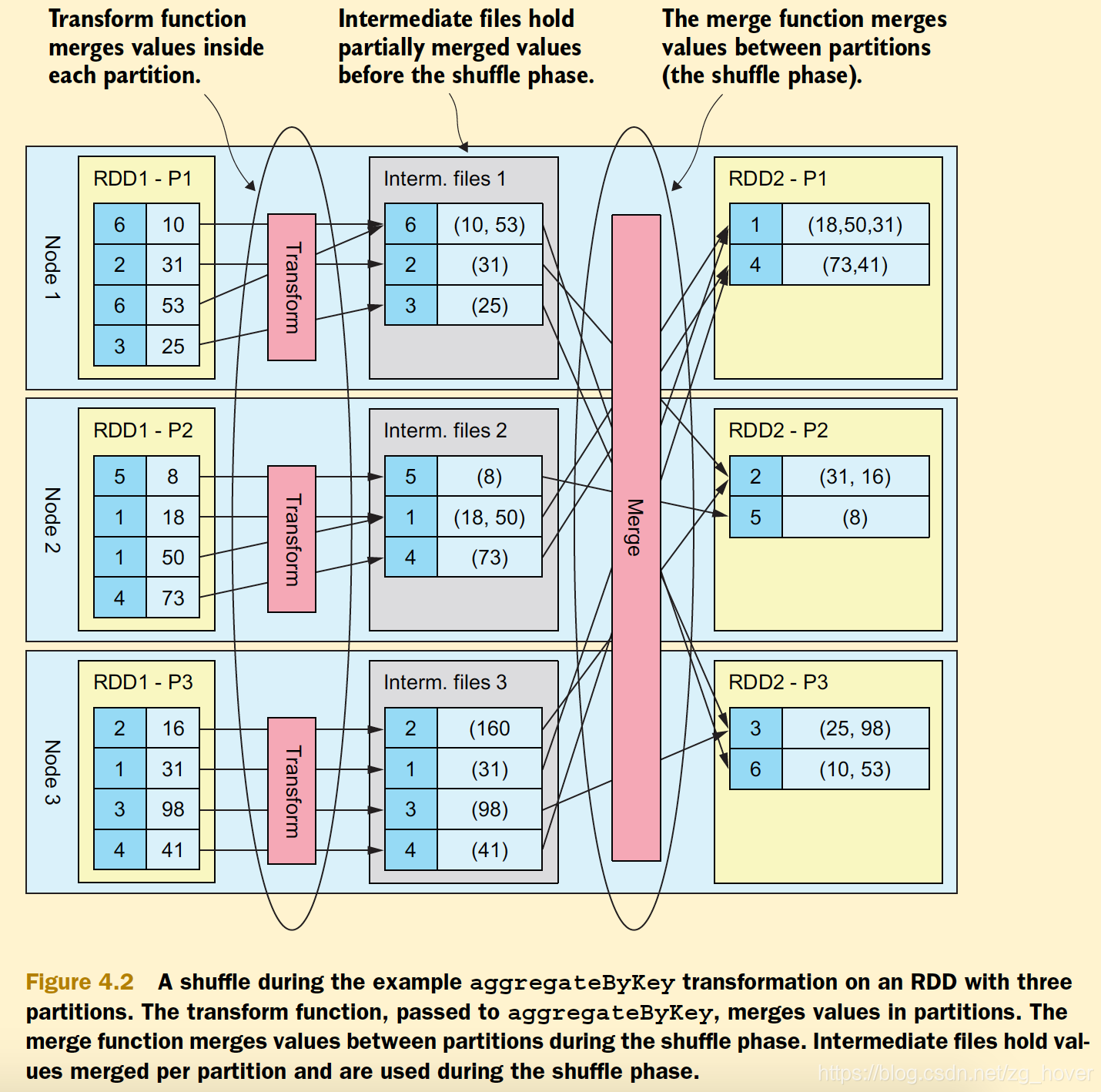
上图是《spark in action》中的例子图。
上图是一个通过key来聚合数据的例子,开始的时候各个key的数据分布在不同的Spark节点上。先进行transform过程,转换过程是在各个数据的分区上进行,聚合过程需要从不同节点的分区上获取数据,此时将会发生shuffling。
注意:关于shuffle的详细代码实现,还会有文章专门进行讲解。