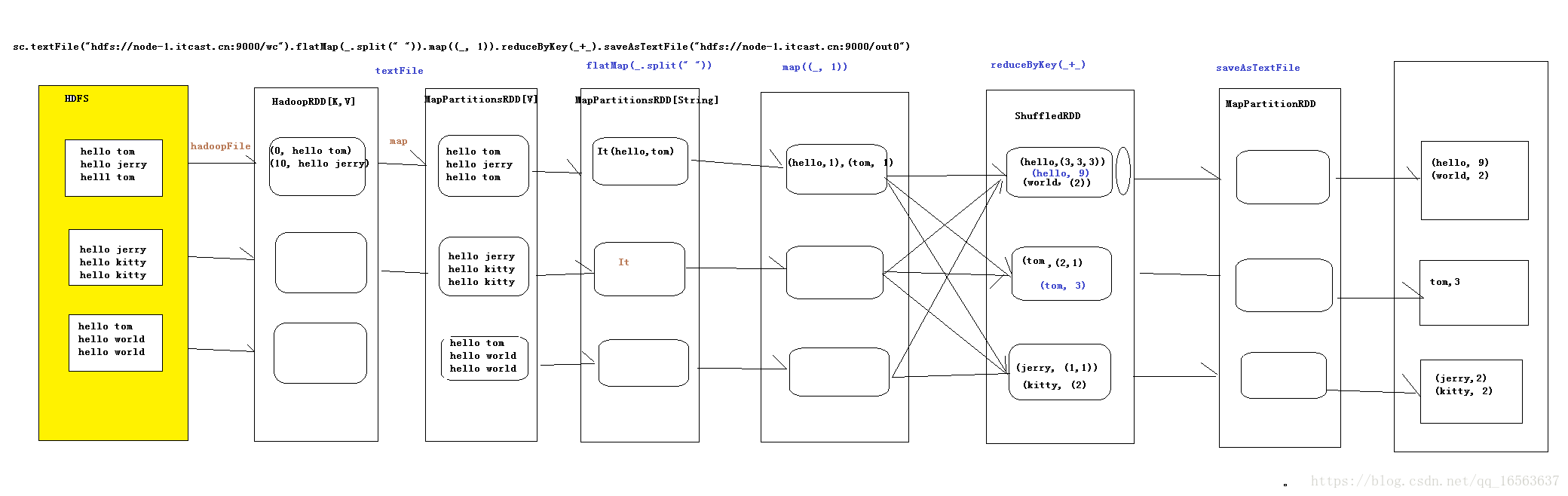
val rdd = sc.textFile("file:///root/wc").flatMap(_.split(" ")).map(_,1).reduceByKey(_,_).saveAsTextFile("file:///root/wc00")
上面单词计数总共产生6个rdd
可以执行下面语句查询
rdd数量查询
rdd.toDebugString
rdd依赖查询
rdd.dependencies
textFile会产生两个rdd,第一个是hadoopRdd(k,v形式),第二个是MapPatitionsRdd
flatMap产生一个rdd是MapPatitionsRdd
map产生一个rdd是MapPatitionsRdd
reduceByKey产生ShuffledRdd(把数据从上游拉过来进行聚合)
saveAsTextFile产生MapPatitions
RDD缓存
spark运算非常快的原因之一就是在不同操作中可以在内存中持久化或者缓存整个数据集
比如:
val rdd=sc.textFile(“hdfs://192.168.1.101:9000/root/wc/input.txt”).cache()
#cache不是立即缓存也是一个转换动作(延迟加载)
#查看192.168.1.101:4040/job
persist()也是缓存需要输入入参StorageLevel,缓存级别(可以根据文件重要情况缓存1-2份)
用完后记得清除缓存
rdd.unpersist(true)